


400 128 6709

行业新闻
 发布时间:2024-01-11
发布时间:2024-01-11 点击次数:
点击次数: GPT-5何时到来,会有什么能力?
来自艾伦人工智能研究所(Allen Institute for AI )的新模型告诉你答案。
)的新模型告诉你答案。
艾伦人工智能研究所推出的Unified-IO 2是第一个可以处理和生成文本、图像、音频、视频和动作序列的模型。
这个高级AI模型使用数十亿个数据点进行训练,模型大小仅7B,却展现出迄今最广泛的多模态能力。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文地址:https://arxiv.org/pdf/2312.17172.pdf
 TTSMaker
TTSMaker
TTSMaker是一个免费的文本转语音工具,提供语音生成服务,支持多种语言。
 2275
查看详情
2275
查看详情

那么,Unified-IO 2和GPT-5有什么关系呢?
2025年6月,艾伦人工智能研究所推出了首代Unified-IO,成为一种能够同时处理图像和语言的多模态模型之一。
大约在同一时间,OpenAI正在内部测试GPT-4,并在2025年3月正式发布。
所以,Unified-IO可以看作是对于未来大规模AI模型的前瞻。
也就是说,OpenAI可能正在内部测试GPT-5,并将在几个月后发布。
而本次Unified-IO 2向我们展现的能力,也将是我们在新的一年可以期待的内容:
GPT-5等新的AI模型可以处理更多模态,通过广泛的学习以本地方式执行许多任务,并且对与物体和机器人的交互有基本的了解。
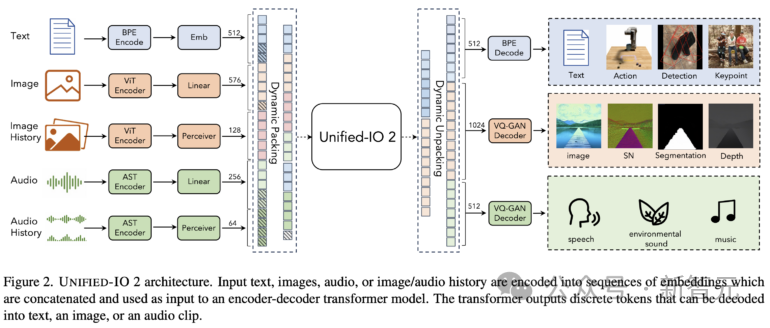
Unified-IO 2的训练数据包括:10亿个图像-文本对、1 万亿个文本标记、1.8亿个视频剪辑、1.3亿张带文本的图像、300万个3D资产和100万个机器人代理运动序列。
研究团队将总共120多个数据集组合成一个600 TB的包,涵盖220个视觉、语言、听觉和动作任务。
Unified-IO 2采用编码器-解码器架构,并进行了一些更改,以稳定训练并有效利用多模态信号。
模型可以回答问题、根据指令撰写文本、以及分析文本内容。
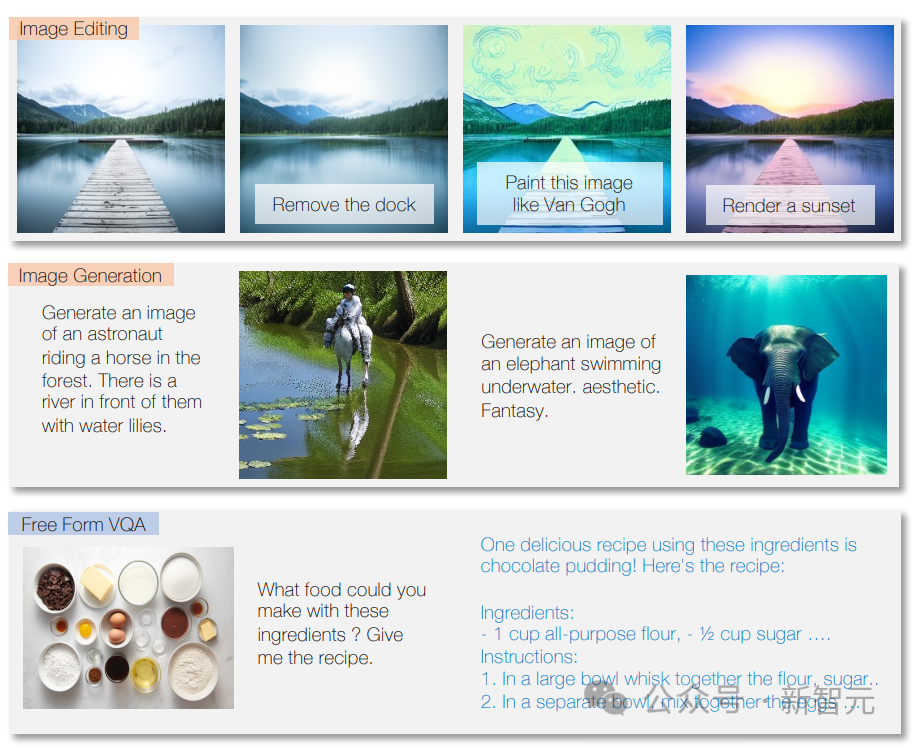
模型还可以识别图像内容,提供图像描述,执行图像处理任务,并根据文本描述创建新图像。
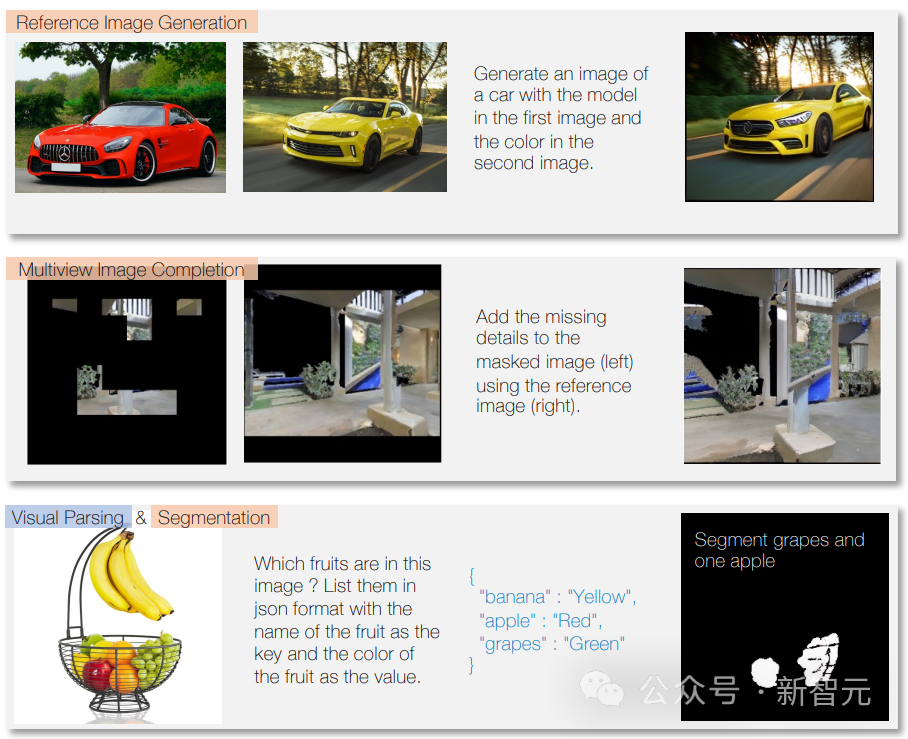
它还可以根据描述或说明生成音乐或声音,以及分析视频并回答有关视频的问题。
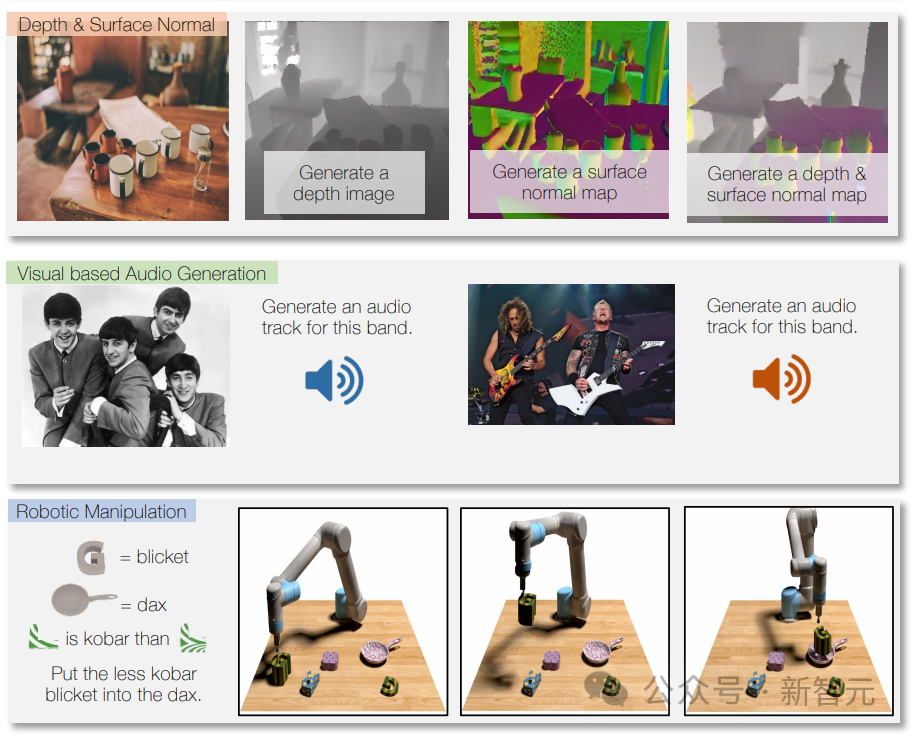
通过使用机器人数据进行训练,Unified-IO 2还可以为机器人系统生成动作,例如将指令转换为机器人的动作序列。
由于多模态训练,它还可以处理不同的模态,例如,在图像上标记某个音轨使用的乐器。

Unified-IO 2在超过35个基准测试中表现良好,包括图像生成和理解、自然语言理解、视频和音频理解以及机器人操作。
在大多数任务中,它能够比肩专用模型,甚至更胜一筹。
在图像任务的GRIT基准测试中,Unified-IO 2获得了目前的最高分(GRIT用于测试模型如何处理图像噪声和其他问题)。
研究人员现在计划进一步扩展Unified-IO 2,提高数据质量,并将编码器-解码器模型,转换为行业标准的解码器模型架构。
Unified-IO 2是第一个能够理解和生成图像、文本、音频和动作的自回归多模态模型。
为了统一不同的模态,研究人员将输入和输出(图像、文本、音频、动作、边界框等)标记到一个共享的语义空间中,然后使用单个编码器-解码器转换器模型对其进行处理。
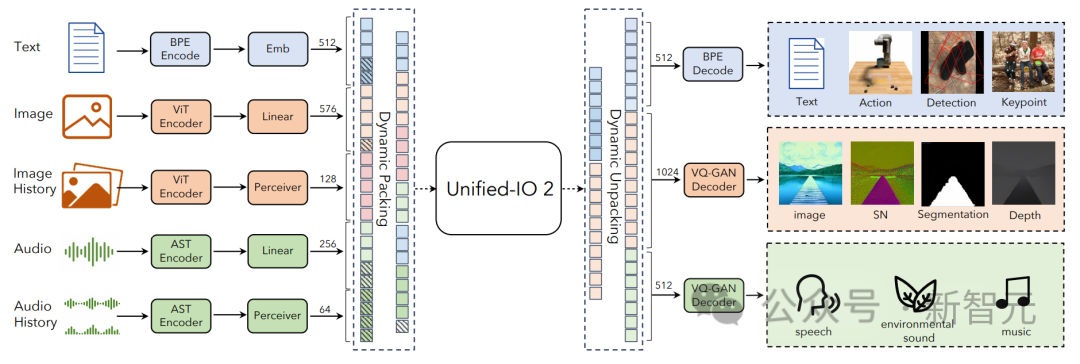
由于训练模型所采用的数据量庞大,而且来自各种不同的模态,研究人员采取了一系列技术来改进整个训练过程。
为了有效地促进跨多种模态的自监督学习信号,研究人员开发了一种新型的去噪器目标的多模态混合,结合了跨模态的去噪和生成。
还开发了动态打包,可将训练吞吐量提高4倍,以处理高度可变的序列。
为了克服训练中的稳定性和可扩展性问题,研究人员在感知器重采样器上做了架构更改,包括2D旋转嵌入、QK归一化和缩放余弦注意力机制。
对于指令调整,确保每个任务都有一个明确的提示,无论是使用现有任务还是制作新任务。另外还包括开放式任务,并为不太常见的模式创建合成任务,以增强任务和教学的多样性。
将多模态数据编码到共享表示空间中的标记序列,包括以下几个方面:
文本输入和输出使用LLaMA中的字节对编码进行标记化,边界框、关键点和相机姿势等稀疏结构被离散化,然后使用添加到词汇表中的1000个特殊标记进行编码。
点使用两个标记(x,y)进行编码,盒子用四个标记(左上角和右下角)的序列进行编码,3D长方体用12个标记表示(编码投影中心、虚拟深度、对数归一化框尺寸、和连续同心旋转)。
对于具身任务,离散的机器人动作被生成为文本命令(例如,「向前移动」)。特殊标记用于对机器人的状态进行编码(例如位置和旋转)。
图像使用预先训练的视觉转换器(ViT)进行编码。将ViT的第二层和倒数第二层的补丁特征连接起来,以捕获低级和高级视觉信息。
生成图像时,使用VQ-GAN将图像转换为离散标记,这里采用patch大小为8 × 8的密集预训练VQ-GAN模型,将256 × 256的图像编码为1024个token,码本大小为16512。
然后将每个像素的标签(包括深度、表面法线和二进制分割掩码)表示为RGB图像。
U-IO 2将长达4.08秒的音频编码为频谱图,然后使用预先训练的音频频谱图转换器(AST)对频谱图进行编码,并通过连接AST的第二层和倒数第二层特征并应用线性层来构建输入嵌入,就像图像ViT一样。
生成音频时,使用ViT-VQGAN将音频转换为离散的标记,模型的patch大小为8 × 8,将256 × 128的频谱图编码为512个token,码本大小为8196。
模型最多允许提供四个额外的图像和音频片段作为输入,这些元素也使用ViT或AST进行编码,随后使用感知器重采样器,进一步将特征压缩为较少数量(图像为32个,音频为16个)。
这大大缩短了序列长度,并允许模型在使用历史记录中的元素作为上下文时,以高细节检查图像或音频片段。
研究人员观察到,随着我们集成其他模式,使用 U-IO 之后的标准实现会导致训练越来越不稳定。
如下图(a)和(b)所示,仅对图像生成(绿色曲线)进行训练会导致稳定的损失和梯度范数收敛。
与单一模态相比,引入图像和文本任务的组合(橙色曲线)略微增加了梯度范数,但保持稳定。然而,包含视频模态(蓝色曲线)会导致梯度范数的无限制升级。
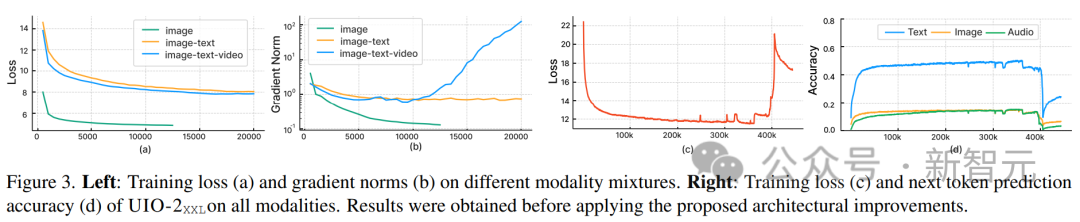
如图中(c)和(d)所示,当模型的XXL版本在所有模态上训练时,损失在350k步后爆炸,下一个标记预测精度在400k步时显著下降。
为了解决这个问题,研究人员进行了各种架构更改:
在每个Transformer层应用旋转位置嵌入(RoPE)。对于非文本模态,将RoPE扩展到二维位置;当包括图像和音频模态时,将LayerNorm应用于点积注意力计算之前的Q和K。
另外,使用感知器重采样器,将每个图像帧和音频片段压缩成固定数量的标记,并使用缩放余弦注意力在感知者中应用更严格的归一化,这显著稳定了训练。
为了避免数值不稳定,还启用了float32注意力对数,并在预训练期间冻结ViT和 AST,并在指令调整结束时对其进行微调。
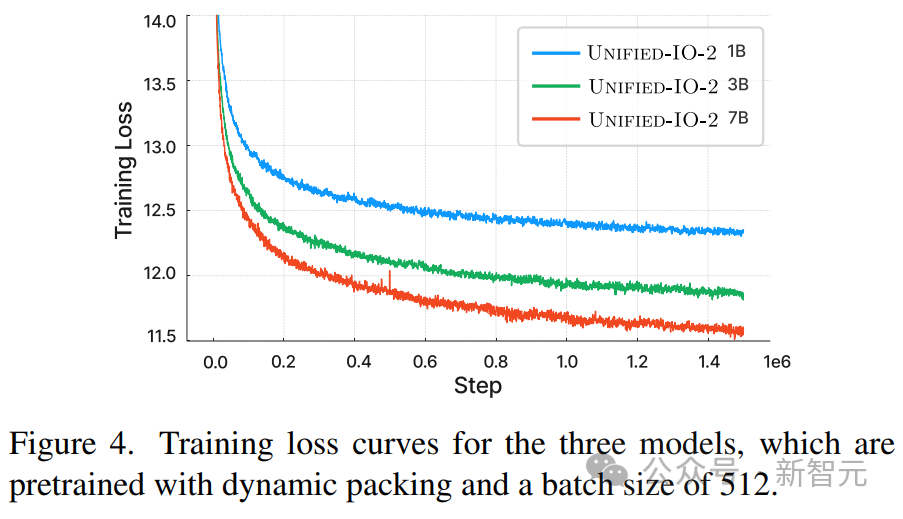
上图显示,尽管输入和输出模态存在异质性,但模型的预训练损失是稳定的。
本文遵循UL2范式。对于图像和音频目标,这里定义了两种类似的范式:
[R]:掩码去噪,随机屏蔽x%的输入图像或音频补丁特征,并让模型重新构建它;
[S]:要求模型在其他输入模态条件下生成目标模态。
在训练期间,用模态标记([Text]、[Image] 或 [Audio])和范式标记([R]、[S] 或 [X])作为输入文本的前缀,以指示任务,并使用动态遮罩进行自回归。
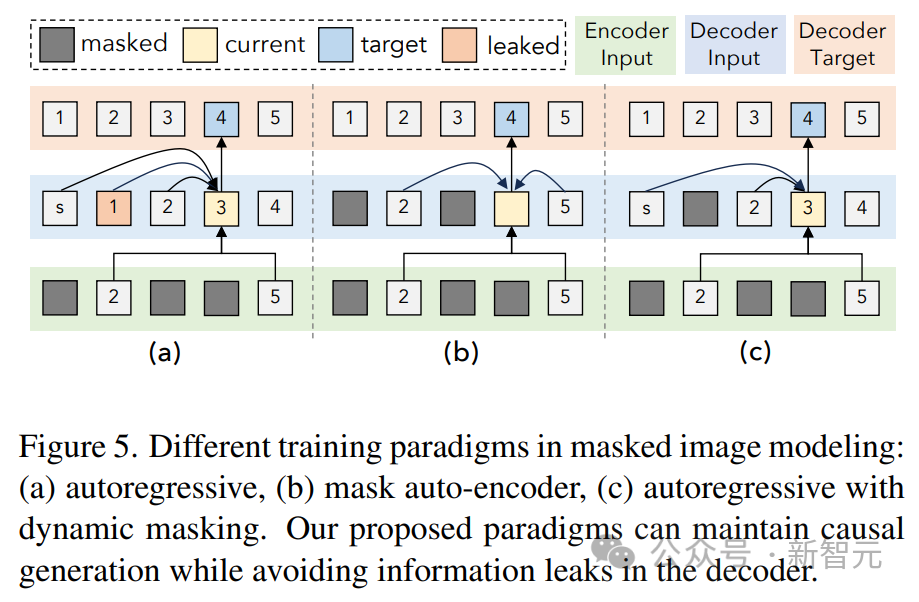
如上图所示,图像和音频屏蔽去噪的一个问题是解码器侧的信息泄漏。
这里的解决方案是在解码器中屏蔽token(除非在预测这个token),这不会干扰因果预测,同时又消除了数据泄漏。
对大量多模态数据进行训练,会导致转换器输入和输出的序列长度高度可变。
这里使用打包来解决这个问题:多个示例的标记被打包到一个序列中,并屏蔽注意力以防止转换器在示例之间交叉参与。
在训练过程中,使用启发式算法来重新排列流式传输到模型的数据,以便将长样本与可以打包的短样本相匹配。本文的动态打包使训练吞吐量增加了近4倍。
多模态指令调优是使模型具备各种模态的不同技能和能力,甚至适应新的和独特的指令的关键过程。
研究人员通过结合广泛的监督数据集和任务来构建多模态指令调优数据集。
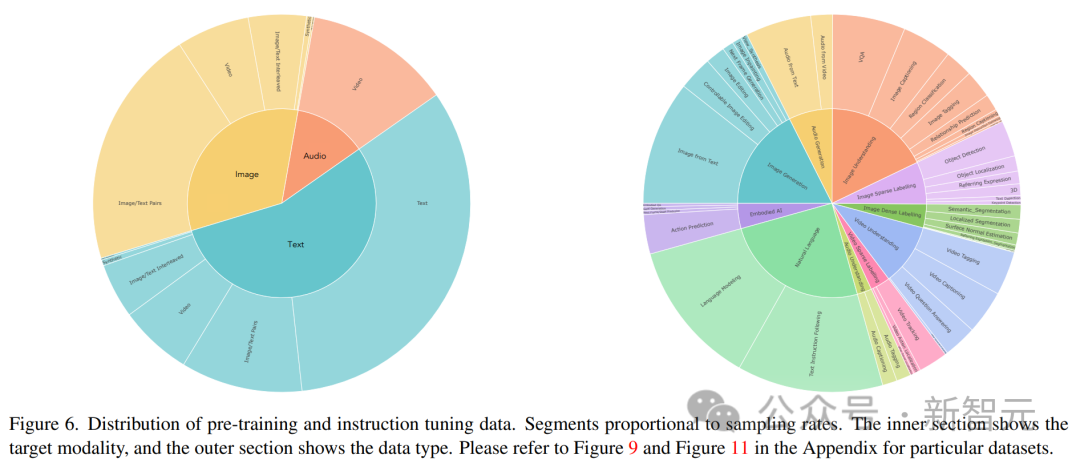
指令调谐数据的分布如上图所示。总体而言,指令调优组合包括60%的提示数据、30%从预训练中继承下来的数据(为了避免灾难性的遗忘)、6%使用现有数据源构建的任务增强数据、以及4%自由格式文本(以实现类似聊天的回复)。
以上就是GPT-5前瞻!艾伦人工智能研究所发布最强多模态模型,预测GPT-5新能力的详细内容,更多请关注其它相关文章!
# 训练
# 永州seo公司都选火星
# 网站优化解决方案公司
# 哪家网站推广好做
# 香蜜湖学习网站建设
# 北京市建设网站
# 山西能源公司网站建设
# 第一个
# 丰田
# 中国科学院
# 第二层
# 并在
# 转换为
# 所示
# 模态
# 艾伦
# 多模
# udio
# llama
# 模型
# 潍坊seo外包优化
# 黄石网站建设托管
# 厦门抖音seo优化团队
# 全网营销推广选哪家好
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
朱民:普通人炒股炒不过机器人是很正常的 AI已经能理解市场情绪
微软在 Build 大会上宣布的新 Microsoft Store AI Hub 现已开始推出
AI 大模型重塑软件开发,有哪些落地前景和痛点?| ArchSummit
Midjourney 5.2震撼发布!原画生成3D场景,无限缩放无垠宇宙
技术如何使人变得懒惰?
AI生成会议纪要 百度如流升级推出超级助手、智能编码等功能
GPT-4不能在麻省理工学院获得计算机科学学位
谷歌在人工智能领域没有“护城河”?
13条咒语挖掘GPT-4最大潜力,Github万星AI导师火了,网友:隔行再也不隔山了
pixivFANBOX 更新运营规则,禁止通过外链绕开 AI 生成禁令
兆讯传媒率先全面拥抱AI 数智广告内容焕发新生机
外科医生的智能助手,“机器人手术”得到补充商业医保覆盖
两小时就能超过人类!DeepMind最新AI速通26款雅达利游戏
2025智源大会AI安全话题备受关注,《人机对齐》新书首发
再也不怕「视频会议」尬住了!谷歌CHI顶会发布新神器Visual Captions:让图片做你的字幕助手
贫穷让我预训练
智能手机应用中的人工智能的重要性
北京市通用人工智能产业创新伙伴计划名单公布,京东科技入选“算力伙伴”
人工智能快速发展 打开就业新空间
DreamAvatar数字人在哪里下载
中国最强AI研究院的大模型为何迟到了
甲骨文与Cohere合作为企业提供生成式人工智能服务
英伟达CEO宣称生成式AI已迎来“划时代时刻”
洞穴探险神器?可自主导航的单旋翼自旋无人机,效率更高!
马斯克发推讽刺人工智能,机器学习本质是统计?
解决导航“最后50米”难题 高德地图升级AR步行导航找终点功能
彬州市第三届青少年机器人创新大赛成功举办
原小米 9 号员工李明打造全球首款 AI 安卓桌面机器人
亚马逊CEO:人工智能将成为公司未来战略的重中之重
AI教父Bengio:我感到迷失,对AI担忧已成「精神内耗」!
真全息产品,亮相深圳文博会——dipal数伴拓展元宇宙非沉浸式体验
AMD在AI方面奋起直追,与英伟达的差距缩小了吗?
本届人工智能大会上的这个“镇馆之宝”,来自长宁企业西井科技!
人工智能在项目管理中的作用
ChatGPT只讲这25个笑话!实验上千次有90%重复,网友:幽默是人类最后的尊严
标小智LOGO推出AI公司起名生成器“Name.GPT”
QQ音乐业内率先推出「AI一起听」功能,领取你的AI听歌助手
陈根:AI工具为游戏软件实时3D内容助力
大模型新品出现井喷,AI产业迎来新时代
定义人工智能的十个关键术语
一家 380 亿美元的数据巨头,要掀起企业「AI 化」革命
马斯克发推讽刺人工智能:机器学习的本质就是统计
马斯克WAIC2025演讲全文:AI将对人类文明产生深远影响
“长沙造”无人机,领先的不止植保
你大脑中的画面,现在可以高清还原了
马斯克“揭秘”人工智能真面目
联想创投携手12家被投企业MWC展示元宇宙、机器人等技术
改动一行代码,PyTorch训练三倍提速,这些「高级技术」是关键
国家发改委组织工业机器人产业高质量发展现场会
学生作文评分的新趋势:教师与AI的合作模式
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

