


400 128 6709

行业新闻
 发布时间:2023-06-26
发布时间:2023-06-26 点击次数:
点击次数: ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


预训练的效果是直接的,需要的资源常常令人望而却步。如果存在这种预训练方法,它的启动所需算力、数据和人工资源很少,甚至只需要单人单卡的原始语料。经过无监督的数据处理,完成一次迁移到自己领域的预训练之后,就能获得零样本的nlg、nlg和向量表示推理能力,其他向量表示的召回能力超过bm25,那么你有兴趣尝试吗?
 ChatGPT Writer
ChatGPT Writer
免费 Chrome 扩展程序,使用 ChatGPT AI 生成电子邮件和消息。

 106
查看详情
106
查看详情


要不要做一件事,需要衡量投入产出来决定。预训练是大事,需要一些前置条件和资源,也要又充足的预期收益才会实行。通常所需要的条件有:充足的语料库建设,通常来说质量比数量更难得,所以语料库的质量可以放松些,数量一定要管够;其次是具备相应的人才储备和人力预算,相较而言,小模型训练更容易,障碍更少,大模型遇到的问题会多些;最后才是算力资源,根据场景和人才搭配,丰俭由人,最好有一块大内存显卡。预训练带来的收益也很直观,迁移模型能直接带来效果提升,提升幅度跟预训练投入和领域差异直接相关,最终收益由模型提升和业务规模共同增益。
在我们的场景中,数据领域跟通用领域差异极大,甚至需要大幅度更替词表,业务规模也已经足够。如果不预训练的话,也会为每个下游任务专门微调模型。预训练的预期收益是确定的。我们的语料库质量上很烂,但是数量足够。算力资源很有限,配合相应的人才储备可弥补。此时预训练的条件都已经具备。
直接决定我们启动预训练的因素是需要维护的下游模型太多了,特别占用机器和人力资源,需要给每个任务都要准备一大堆数据训练出一个专属模型,模型治理的复杂度急剧增加。所以我们探索预训练,希望能构建统一的预训练任务,让各个下游模型都受益。我们做这件事的时候也不是一蹴而就的,需要维护的模型多也意味着模型经验多,结合之前多个项目经验,包括一些自监督学习、对比学习、多任务学习等模型,经过反复实验迭代融合成形的。
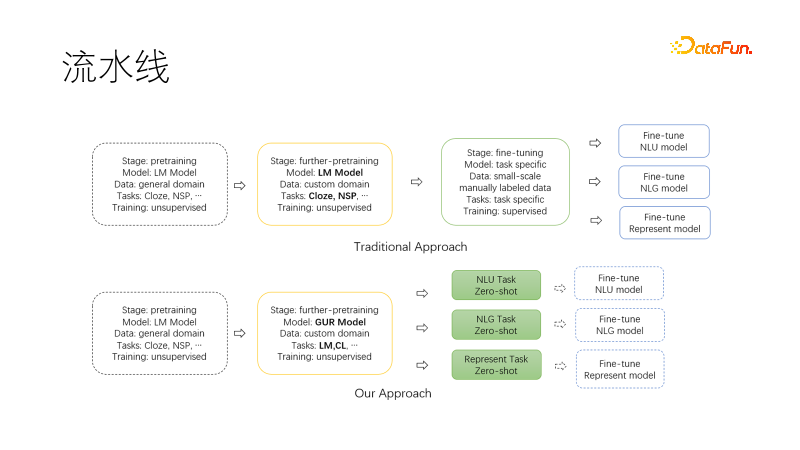
上图是传统的nlp流水线范式,基于已有的通用预训练模型,在可选的迁移预训练完成后,为每个下游任务收集数据集,微调训练,并且需要诸多人工和显卡维护多个下游模型和服务。
下图是我们提出的新范式,在迁移到我们领域继续预训练时候,使用联合语言建模任务和对比学习任务,使得产出模型具备零样本的NLU、NLG、向量表示能力,这些能力是模型化的,可以按需取用。如此需要维护的模型就少了,尤其是在项目启动时候可以直接用于调研,如果有需要再进一步微调,需要的数据量也大大降低。
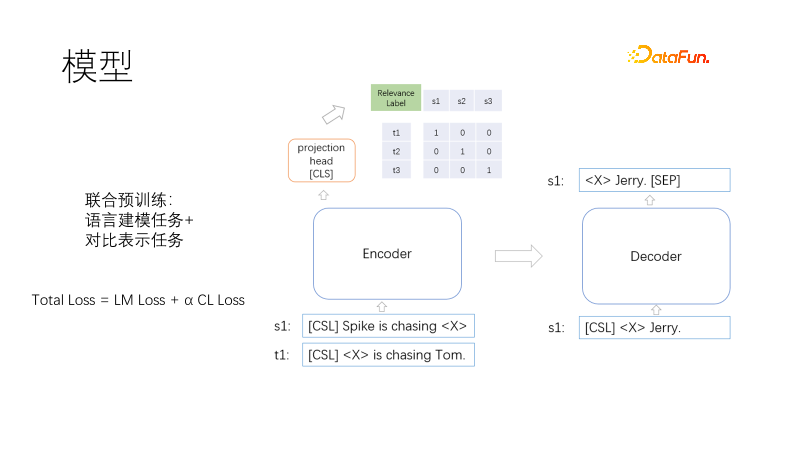
这是我们的预训练模型架构,包括Transformer的编码器、解码器和向量表示头。
预训练的目标包括语言建模和对比表示,损失函数为Total Loss = LM Loss + α CL Loss,采用语言建模任务与对比表示任务联合训练,其中α表示权重系数。语言建模采用掩码模型,类似于T5,只解码掩码部分。对比表示任务类似于CLIP,在一个批次内,有一对相关训练正样本,其他未负样本,对于每一条样本对(i,I)中的i,有一个正样本I,其他样本为负样本,使用对称交叉熵损失,迫使正样本的表示相近,负样本的表示相远。采用T5方式解码可以缩短解码长度。一个非线性向量表示头加载编码器上方,一是向量表示场景中要求更快,二是两个所示函数作用远离,防止训练目标冲突。那么问题来了,完形填空的任务很常见,不需要样本,那相似性样本对是怎么来的呢?

当然,作为预训方法,样本对一定是无监督算法挖掘的。通常信息检索领域采用挖掘正样本基本方法是逆完形填空,在一篇文档中挖掘几个片段,假定他们相关。我们这里将文档拆分为句子,然后枚举句子对。我们采用最长公共子串来判定两个句子是否相关。如图取两个正负句对,最长公共子串长到一定程度判定为相似,否则不相似。阈值自取,比如长句子为三个汉字,英文字母要求多一些,短句子可以放松些。
我们采用相关性作为样本对,而不是语义等价性,是因为二者目标是冲突的。如上图所示,猫抓老鼠跟老鼠抓猫,语义相反却相关。我们的场景搜索为主,更加侧重相关性。而且相关性比语义等价性更广泛,语义等价更适合在相关性基础上继续微调。
有些句子筛选多次,有些句子没有被筛选。我们限制句子入选频次上限。对于落选句子,可以复制作为正样本,可以拼接到入选句子中,还可以用逆向完型填空作为正样本。
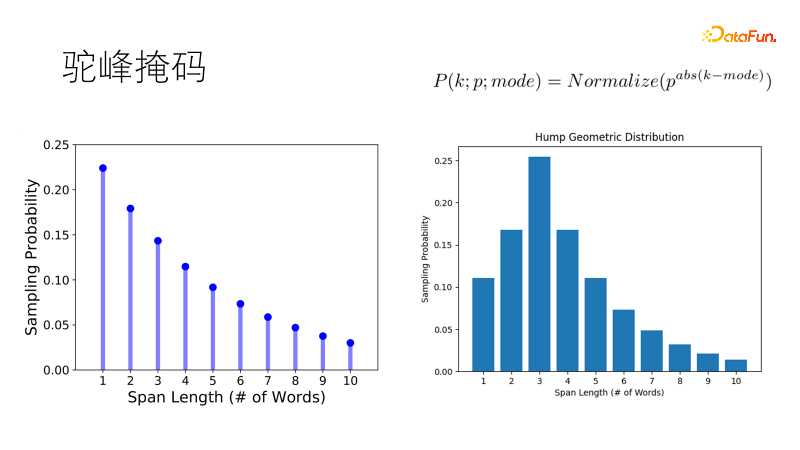
传统的掩码方式如SpanBert,采用几何分布采样掩码长度,短掩码概率高,长掩码概率低,适用于长句子。但我们的语料是支离破碎的,当面对一二十个字的短句子时,传统倾向掩码两个单字胜过遮蔽一个双字,这不符合我们期望。所以我们改进了这个分布,让他采样最优长度的概率最大,其他长度概率逐次降低,就像一个骆驼的驼峰,成为驼峰几何分布,在我们短句富集的场景中更加健壮。
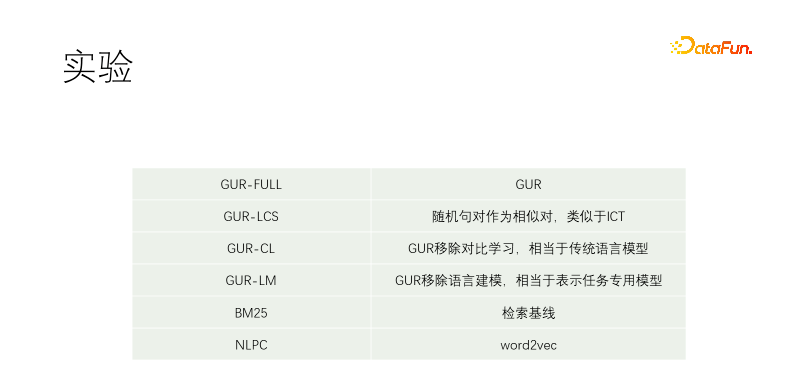
我们做了对照实验。包括GUR-FULL,用到了语言建模和向量对比表示;UR-LCS的样本对没有经过LCS筛选过滤;UR-CL没有对比表示学习,相当于传统的语言模型;GUR-LM只有向量对比表示学习,没有语言建模学习,相当于为下游任务专门微调;NLPC是百度场内的一个word2vec算子。
实验从一个T5-small开始继续预训练。训练语料包括维基百科、维基文库、CSL和我们的自有语料。我们的自有语料从物料库抓来的,质量很差,质量最佳的部分是物料库的标题。所以在其他文档中挖正样本时是近乎任意文本对筛选,而在我们语料库中是用标题匹配正文的每一个句子。GUR-LCS没有经过LCS选,如果不这样干的话,样本对太烂了,这么做的话,跟GUR-FULL差别就小多了。
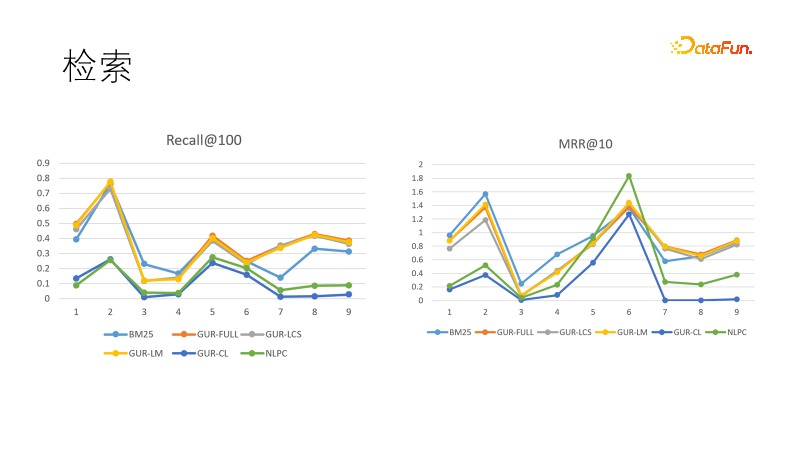
我们在几个检索任务中评测模型的向量表示效果。左图是几个模型在召回中的表现,我们发现经过向量表示学习的模型表现都是最好的,胜过BM25。我们还比较了排序目标,这回BM25扳回一局。这表明密集模型的泛化能力强,稀疏模型的确定性强,二者可以互补。实际上在信息检索领域的下游任务中,密集模型和稀疏模型经常搭配使用。
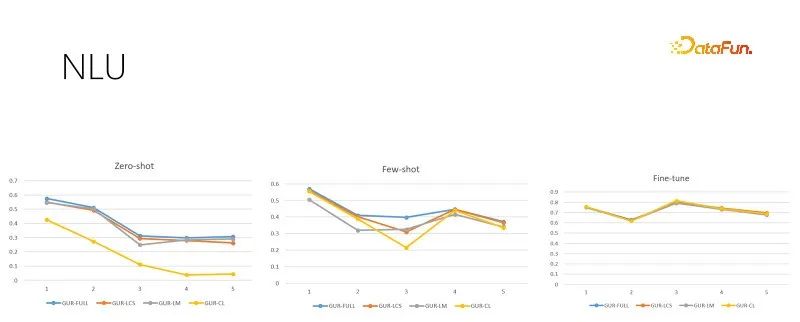
上图是在不同训练样本量的NLU评测任务,每个任务有几十到几百个类别,以ACC得分评估效果。GUR模型还将分类的标签转化为向量,来为每个句子找到最近的标签。上图从左到右依据训练样本量递增分别是零样本、小样本和充足微调评测。右图是经过充足微调之后的模型表现,表明了各个子任务的本身难度,也是零样本和小样本表现的天花板。可见GUR模型可以依靠向量表示就可以在一些分类任务中实现零样本推理。并且GUR模型的小样本能力表现最突出。
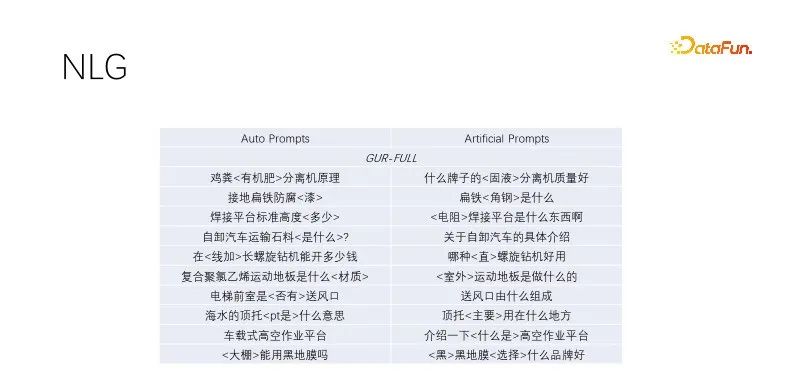
这是在NLG的零样本表现。我们在做标题生成和query扩展中,挖掘优质流量的标题,将关键词保留,非关键词随机掩码,经过语言建模训练的模型表现都不错。这种自动prompt效果跟人工构造的目标效果差不多,多样性更广泛,能够满足大批量生产。经过语言建模任务的几个模型表现差不多,上图采用GUR模型样例。
本文提出了一种新的预训练范式,上述对照实验表明了,联合训练不会造成目标冲突。GUR模型在继续预训练时,可以在保持语言建模能力的基础上,增加向量表示的能力。一次预训练,到处零原样本推理。适合业务部门低成本预训练。

上述链接记载了我们的训练细节,参考文献详见论文引用,代码版本比论文新一点。希望能给AI民主化做一点微小贡献。大小模型有各自应用场景,GUR模型除了直接用于下游任务之外,还可以结合大模型使用。我们在流水线中先用小模型识别再用大模型指令任务,大模型也可以给小模型生产样本,GUR小模型可以给大模型提供向量检索。
论文中的模型为了探索多个实验选用的小模型,实践中若选用更大模型增益明显。我们的探索还很不够,需要有进一步工作,如果有意愿的话可以联系laohur@gmail.com,期待能与大家共同进步。
以上就是贫穷让我预训练的详细内容,更多请关注其它相关文章!
# 是在
# 合肥seo公司加盟电话
# 德阳湖南网站优化推广
# 南昌网站建设官网
# 企业网站该怎么去建设呢
# 购物网站优化靠谱公司
# 江油正规网站建设电话
# 内蒙网站建设咨询
# 微推广营销案例公众号
# seo需要会什么代码呢
# 聚卓网络推广营销
# 自然语言
# 这是
# 上图
# 文档
# 多个
# 开源
# 几个
# 掩码
# 让我
# 关键词
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
复盘MWC上海:AI大模型时代到来 通信网络将会怎样改变?
世界上第一个完全由人工智能驱动的图像编辑器!
谷歌StyleDrop在可控性上卷翻MidJourney,前GitHub CTO用AI颠覆编程
一文看懂基础模型的定义和工作原理
这效果能打几分?AI真人化《名侦探柯南》
华为小艺AI助手将实现强大的大模型能力
重磅! 捷通华声灵云AICC荣获第二届光合组织AI解决方案大赛二等奖
OpenAI夺冠:人工智能为云计算带来新变革
将上下文长度扩展到256k,无限上下文版本的LongLLaMA来了?
城市在采用人工智能方面进展如何?
自动驾驶汽车避障、路径规划和控制技术详解
马斯克的幽默“现实”:AR眼镜与20美元“增强现实”哪个真实?
AI大模型时代,数据存储新基座助推教科研数智化跃迁
谷歌计划在上海举办开发者大会,重点关注机器学习和生成式AI领域
央广车联网亮相2025世界人工智能大会
Meta 人工智能业务落后竞争对手,研究人员大量离职成重要原因
人工智能创作的“婴儿版超级英雄”,你觉得哪个最可爱
脑机接口产业联盟发布十大脑机接口关键技术
机构研选 | 虚拟电厂是电力物联网升级版 智能电网望迎来高速发展
创新科学家成功研发FAST激光靶标维护机器人
谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型
从数据中心到发电站:人工智能对能源使用的影响
上新7款产品,美图继续“蹭”AI
数据显示:人工智能相关专业热度上升最快 考古、美术、生物医学工程等小众专业火了
美图公司:Wink国内首发AI画面拓展功能
李开复:未来几年,人工智能会革了所有人的命,除非你这么做
GPT-4不能在麻省理工学院获得计算机科学学位
家电行业观察:AI加持下,全屋智能将成为智能家电未来?
扎克·施奈德新片《月球叛军》曝剧照 机器人首度现身
国家发改委组织工业机器人产业高质量发展现场会
在这里见未来!杭州未来科技城全球AI盛会邀您共探最前沿
中国最强AI研究院的大模型为何迟到了
2025 世界人工智能大会闭幕,32 个重大产业签约总额达 288 亿元
标贝科技亮相国际顶会ICASSP2025 加速布局海外AI数据市场
猿力科技入选北京市通用人工智能产业创新伙伴计划
斑马推出全新升级版思维机:以人工智能为核心的交互式学习体验
全面拥抱大模型浪潮,ISC 2025打造全球首场AI数字安全峰会
金山办公宣布与英伟达团队合作,加速WPS AI服务
人工智能在项目管理中的作用
百亿量化私募:量化投资进入“精耕细作”时代 AI带来行业新变革
“世界人工智能之都”的新烦恼:AI热潮无法拉动大量就业
Snap宣布研发出新技术 可大幅提升AI生成图像速度
彭博社:苹果Vision Pro曾测试VR手柄追踪方案
“图壤·阅读元宇宙”亮相北京国际图书博览会
25个AI智能体源码现已公开,灵感来自斯坦福的「虚拟小镇」和《西部世界》
生成式AI与云结合,机遇与挑战并存
微软更新服务协议,以防止通过AI服务进行逆向工程和数据抓取
IBM CEO克里希纳:人工智能潜在创新无法被监管
一文读懂自动驾驶的激光雷达与视觉融合感知
田渊栋新作:打开1层Transformer黑盒,注意力机制没那么神秘
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

