


400 128 6709

行业新闻
 发布时间:2024-05-13
发布时间:2024-05-13 点击次数:
点击次数: Meta FAIR 联合哈佛优化大规模机器学习时产生的数据偏差,提供了新的研究框架。
据所周知,大语言模型的训练常常需要数月的时间,使用数百乃至上千个GPU。以LLaMA2 70B模型为例,其训练总共需要1,720,320个GPU小时。由于这些工作负载的规模和复杂性,导致训练大模型存在着独特的系统性挑战。
最近,许多机构在训练SOTA生成式AI模型时报告了训练过程中的不稳定情况,它们通常以损失尖峰的形式出现,比如谷歌的PaLM模型训练过程中出现了多达20次的损失尖峰。
数值偏差是造成这种训练不准确性的根因,由于大语言模型训练执行成本极高,如何量化数值偏差俨然成为关键问题。
在最新的一项工作中,来自 Meta、哈佛大学的研究者开发了一个原则性定量方法来理解训练优化中的数值偏差。以此评估不同的最新优化技术,并确定它们在用于训练大模型时是否可能引入意外的不稳定性。 研究者们发现,尽管现有的优化方法在一些任务上表现出色,但在大型模型上应用时,会出现一些数值偏差。这种数值偏差可能会在训练过程中产生不稳定性,导致模型的性能下降。 为了解决这个问题,研究者们提出了一种基于原则性定量方法的优化
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

结果发现,在一次单独的前向传递过程中,Flash Attention 的数值偏差比 BF16 的 Baseline Attention 大一个数量级。
具体而言,该方法包括两个阶段,包括:
研究者分析了 SOTA 优化技术 Flash Attention,并量化了可可能引入的数值偏差。Flash Attention 是一种广泛用于加速注意力机制的技术,通常被认为是 Transformer 模型中的系统瓶颈。Flash Attention 在提高速度和减少内存访问量的同时,也依赖于算法优化,而算法优化有可能导致数值偏差的增加。
研究者假设添加重新缩放因子(rescaling factors )可能会引入无意的近似,导致数值折衷,这可能会在后续影响训练稳定性。
他们在多模态文本到图像工作负载的背景下分析了 Flash Attention,以确定 Flash Attention 与其基线之间数值偏差的潜在重要性。最终,他们引入了一个框架来量化训练优化的数值偏差及其下游影响。
研究者在数值偏差量化上主要作出了以下两点贡献:
研究者所设计的微基准作为一种技术,用于衡量和量化传统黑盒优化(如 Flash Attention)所导致的数值偏差。通过扰动通常在提供的内核中不可用的方面,他们开创性地发现在低数值精度(BF16)下,与 Baseline Attention 相比,Flash Attention 的数值偏差大约高出一个数量级。
通过该分析,研究者将观察到的数值偏差置于上下文,并为其对下游模型属性的影响形成一个上限(upper bound)。在研究者的案例研究中,他们能够限制观察到的数值偏差的影响,并发现:「Flash Attention 引入的模型权重偏差大约为低精度训练的 1/2 至 1/5 倍。」
这项研究强调了开发一种原则性方法的重要性:「不仅要量化,而且要将训练优化对数值偏差的影响置于上下文中。」通过构建代理(proxies)来将数值偏差置于上下文中,旨在推断通常难以衡量的下游模型效果(即训练不稳定性)的可能性。
研究者首先开发了一个微基准来分离并研究 Flash Attention 引起的数值偏差。如图 2 所示,他们通过对 Flash Attention 进行数值上的重新实现,以分析不同的数值精度,并在算法的每个步骤应用潜在的优化措施。
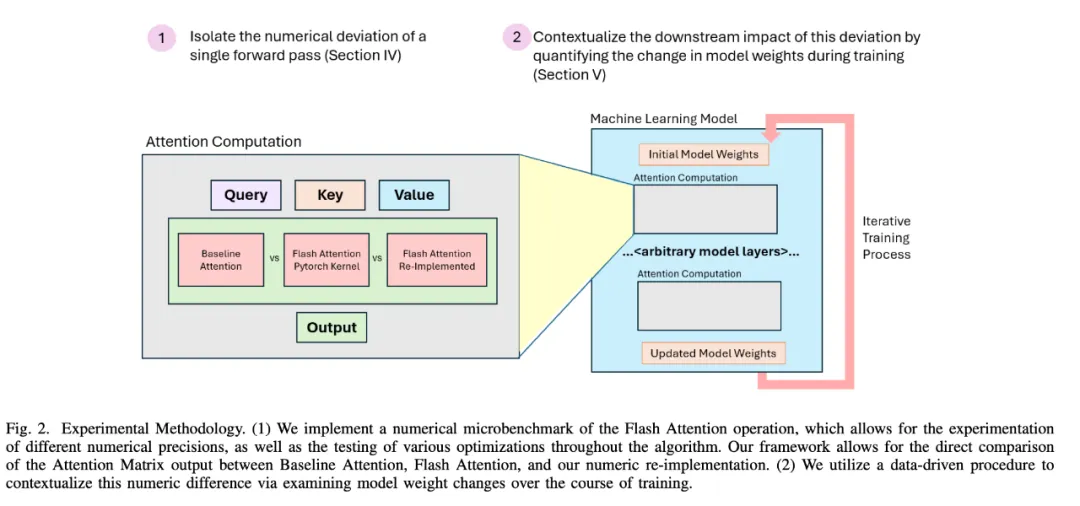
图 2: 微基准设计摘要。
这是必要的,因为 Flash Attention 内核目前仅支持 FP16 和 BF16 数值格式。该内核还是 CUDA 代码的包装 API 调用,这使得扰动算法以检查数值偏差的影响变得具有挑战性。
相比之下,他们的微基准设计允许在算法内部进行精度输入和修改。研究者将微基准与原始的 Flash Attention kernel 进行了验证。
他们进一步设计了一种技术,以比较模型执行过程中每个步骤的 Attention 矩阵的输出。并修改了模型代码,每次调用注意力时都计算 Baseline Attention 和 Flash Attention,这允许对相同的输入矩阵进行精确的输出矩阵比较。
为了将其置于上下文中,研究者还通过相同和独立的训练运行,使用 Max difference 和 Wasserstein Distance 度量来量化模型权重在整个训练过程中的差异。
对于训练实验,研究者则使用一种将文本输入转换为图像的生成式 AI workload(即文本到图像模型)。他们使用 Shutterstock 数据集重新训练模型,并在一组英伟达 80GB A100 GPU 集群上运行此实验。
研究者首先分析了 Flash Attention 在前向传递过程中的影响。他们利用微基准测试,在随机初始化查询、键、值向量相同的情况下,检验不同数值精度对 Attention 计算的输出矩阵的影响。
正如图 3 所示,当研究者使用从 BF16 到 FP64 变化的不同数值格式时,Flash Attention 和 Baseline Attention 之间的数值偏差随着尾数位数的增加而减小。这表明数值差异是由于较少的尾数位数所固有的近似造成的。
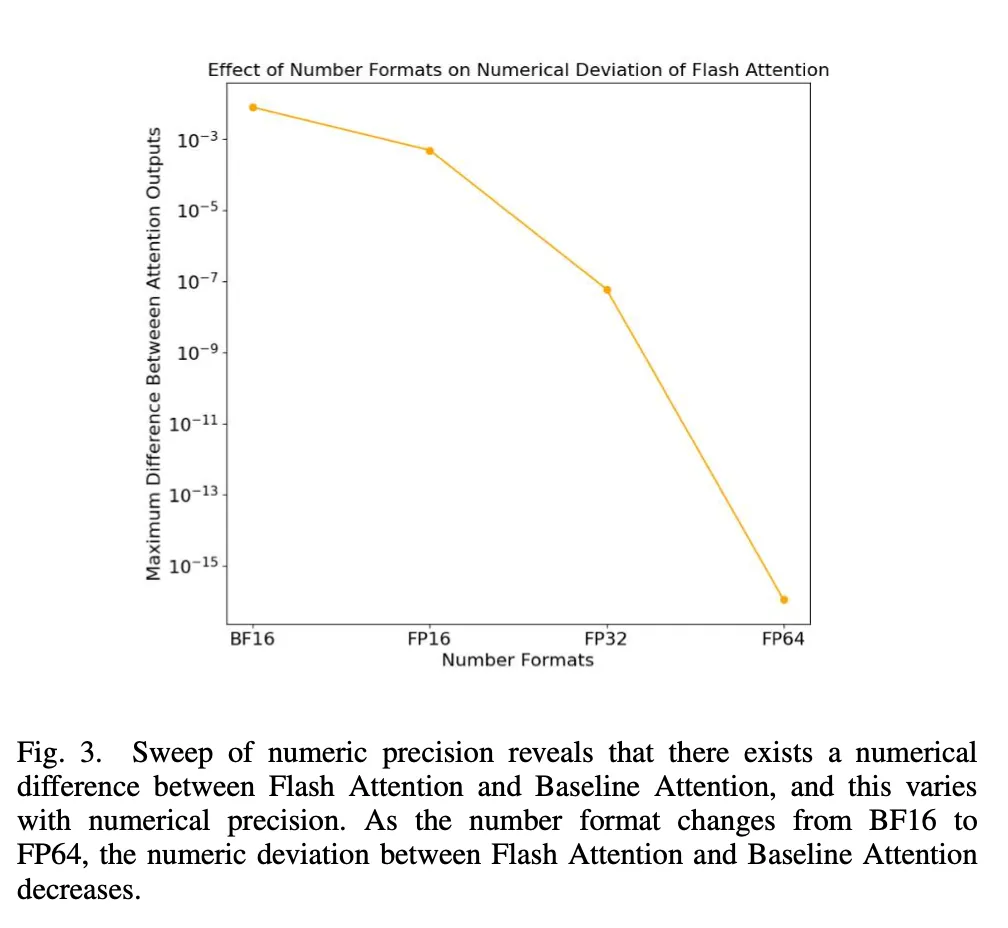
图 3:数值格式对于 Flash Attention 的数值偏差所产生的效果。
之后,研究者为进行标准比较,在 FP64 数值格式下的 Baseline Attention 设置了「黄金值」,然后将不同数值格式下的 Attention 输出与该值进行了比较(如图 4 所示)。
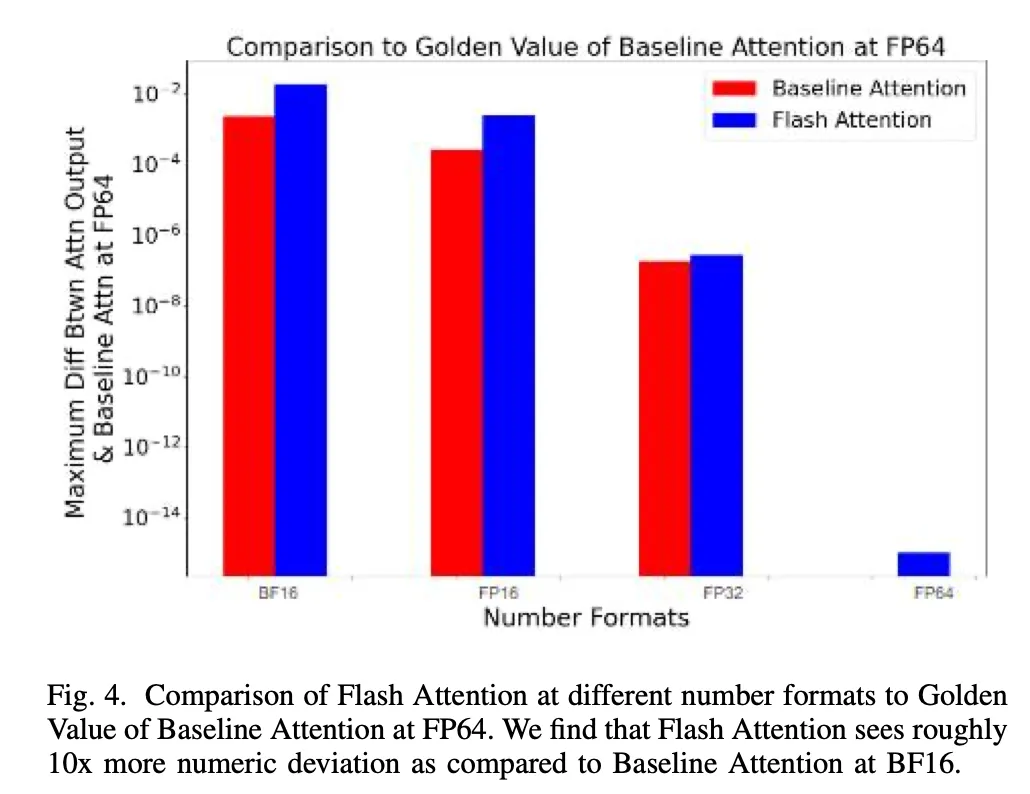
图 4:FP64 下 Baseline Attention「黄金值」的比较。
结果表明,Flash Attention 的数值偏差大约是在 BF16 下 Baseline 的 10 倍。
为了进一步分析这种观察到的数值偏差,研究者保持 tile 大小和 SRAM 大小不变的同时,扫描了矩阵的序列长度(如图 5 所示)。
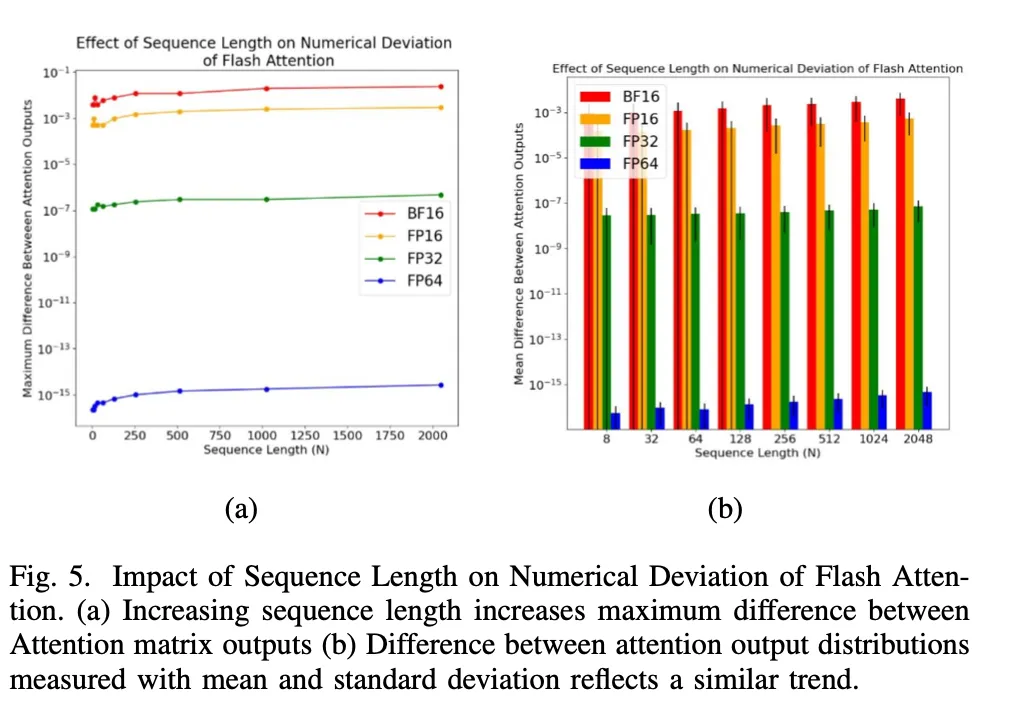
图 5: 序列长度对 Flash Attention 数值偏差的影响。
如图所示,随着序列长度的增加,无论是通过(a)最大差异上限的测量,还是通过(b)差异的平均值和标准差的测量,Flash Attention 和 Baseline Attention 之间的数值偏差都在增加。
除此之外,研究者还利用微基准设计进行不同优化的实验,以便更好地了解数值偏差的影响(如图 6 所示)。
图 6a 显示了调换 block 维数的顺序如何导致 Flash Attention 和 Baseline Attention 之间的数值差异增大。图 6b 中的其他扰动,比如限制 tile 大小为正方形,不会对数值偏差产生影响。图 6c 表明了 block/tile 大小越大,数值偏差越小。
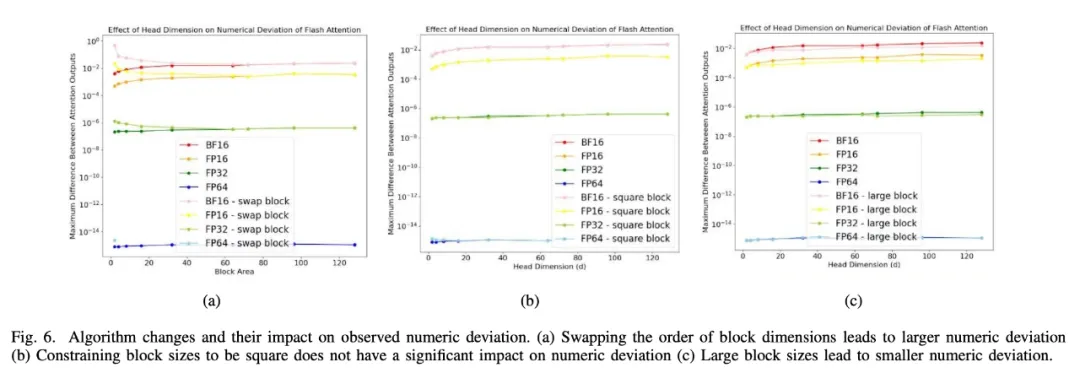
图 6: 算法的改变及其对观察到的数值偏差的影响。
虽然在前向传递过程中,Flash Attention 可能会导致 Attention 输出的数值偏差,但这项研究的最终目标是确定这是否会在模型训练过程中产生任何影响,以研究它是否会导致训练的不稳定性。
因此,研究者希望量化 Flash Attention 是否在训练过程中改变了模型,即上文观察到的 Attention 输出差异是否反映在训练过程中更新的模型权重中。
研究者利用两个指标来衡量使用 Baseline Attention 训练的模型与使用 Flash Attention 训练的模型之间的模型权重差异。首先计算最大差异,即找出权重矩阵之间差异的绝对值并取最大值,从而得出偏差的上限,如下所示:
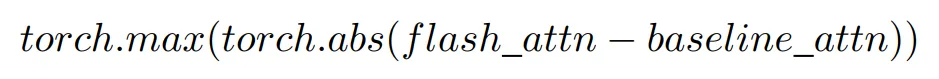
虽然最大差值提供了数值偏差的上限,但它没有考虑到每个矩阵的分布情况。因此,研究者通过 Wasserstein Distance 来量化权重差异,这是衡量张量之间相似性的常用度量。虽然在计算上稍显复杂,但 Wasserstein Distance 包含了张量分布的形状信息以衡量相似性。计算公式概述如下:
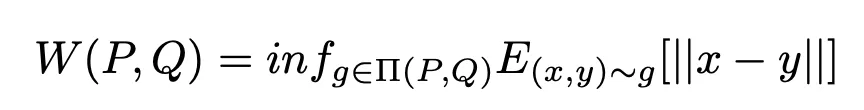
数值越低,表明矩阵之间的相似度越高。
利用这两个指标,研究者随后量化了在整个训练过程中与 Baseline Attention 相比,Flash Attention 的模型权重是如何变化的:
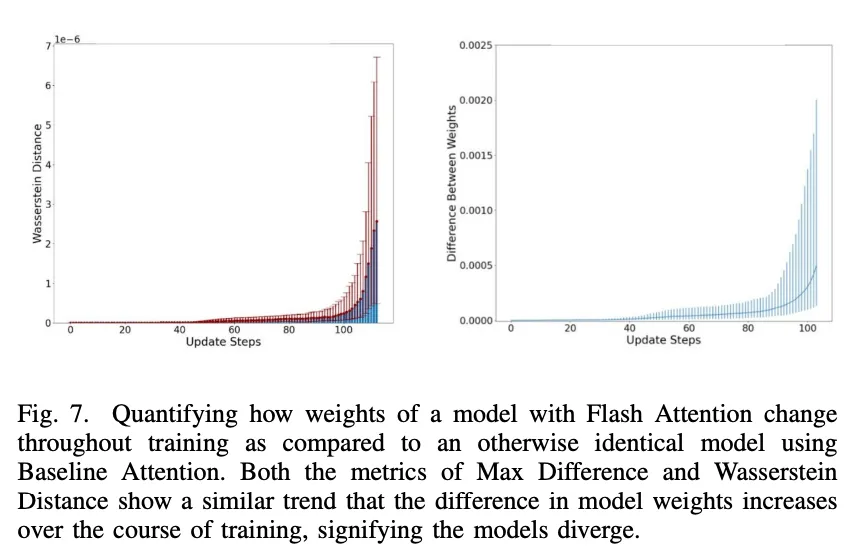
根据 Wasserstein Distance 和 Max Difference 这两个指标,在整个训练过程中,Flash Attention 的加入确实改变了模型权重,而且随着训练的继续,这种差异只会越来越大,这表明了使用 Flash Attention 训练的模型与使用 Baseline Attention 训练的相同模型收敛到了不同的模型。
然而,训练是一个随机过程,某些模型结构的改变可能会在下游效应和准确性方面产生相似的结果。即使使用 Flash Attention 和 Baseline Attention 训练的模型权重不同,这也是值得关注的。
完全训练模型并评估准确性是一项成本昂贵且资源密集的任务,特别是 对于训练需要数月的大模型来说。
对于训练需要数月的大模型来说。
研究者通过配置一个 proxy 来探寻:
(a) 这些权重变化的意义有多大?
(b) 能否将其与其他广泛采用的训练优化中的标准权重变化联系起来?
 Canva AI
Canva AI
Canva平台AI图片生成工具
 1374
查看详情
1374
查看详情

为了实现这一目标,研究者设计了一系列实验来比较在不同场景下,训练过程中的权重差异是如何变化的。
除了对比使用 Flash Attention 和 Baseline Attention 的训练过程外,他们还量化了在训练开始时权重被初始化为不同随机值的相同训练过程中的权重差异。这提供了一个界限,因为随机权重初始化是一种常用的技术,并且通常会产生等效的结果。
此外,研究者还测量了使用不同精度训练的模型权重的变化。数值精度(即 FP16 与 FP32)有可能导致下游变化,这作为确定了 Flash Attention 权重重要性的一个上限。
如图 8 所示,可以发现,使用 Flash Attention 的模型权重偏差变化率与不同模型初始化的权重偏差变化率相当或更小(注意红色和蓝色曲线的斜率)。
此外,使用 FP16 与 FP32 时的权重变化率比不同模型初始化时的权重变化率更高,变化也更大。
这些结果提供了一个 proxy,并表明:「虽然 Flash Attention 会出现数值偏差,但它会被随机模型初始化和低精度训练所限制。而且所引入的模型权重偏差大约是低精度训练时的 1/2 至 1/5 倍。」
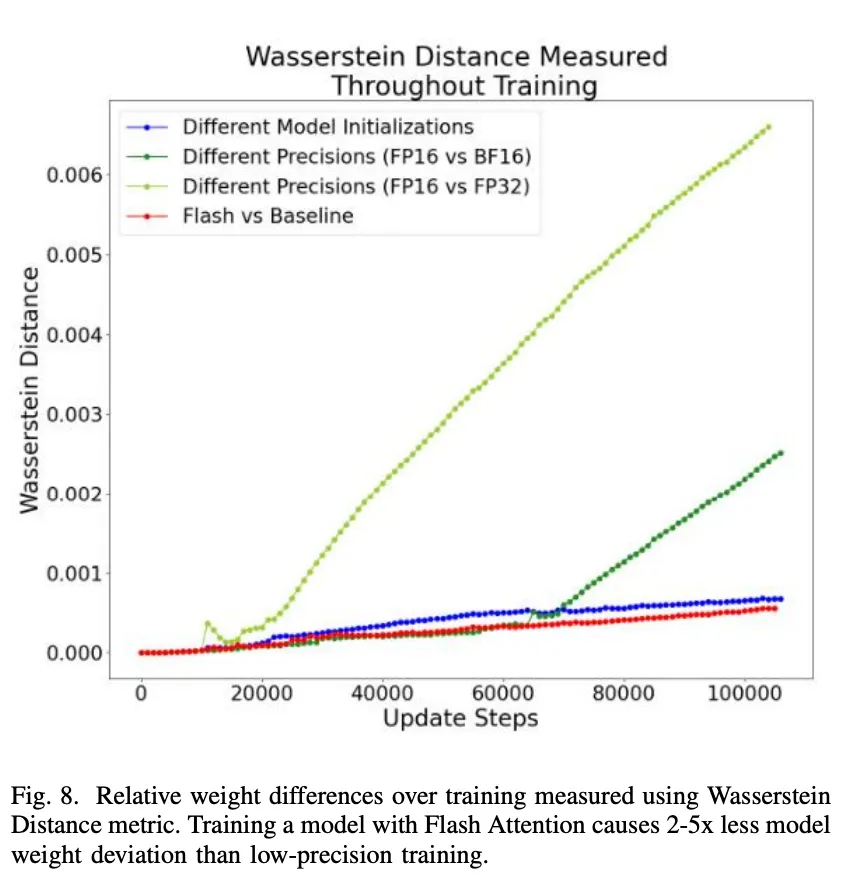
图 8: 使用 Wasserstein Distance metric 测量的训练过程中的相对权重差异。
更多研究细节,可参考原论文。
以上就是Flash Attention稳定吗?Meta、哈佛发现其模型权重偏差呈现数量级波动的详细内容,更多请关注其它相关文章!
# 中东
# 天水建设厅网站
# 产品app推广营销战略
# 九江seo优化流程
# 小吃加盟整合推广营销
# 交友征婚网站怎么做推广
# 厦门短视频seo费用
# 宁夏微信网站建设
# 网站建设开发需要资料吗
# 洛阳seo营销推广外包
# 辽源seo服务电话地址
# 进行了
# 人工智能
# 观察到
# 是一种
# 这是
# 会在
# 如图
# 所示
# 过程中
# 哈佛
# llama
# ai 模型
# 机器学习
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
旷视入选北京市通用人工智能产业创新伙伴计划
加强高质量数据供应能力,促进通用人工智能大模型领域的创新
视觉中国推出付费AI绘图功能:无版权可用
掌阅科技申请阅爱聊商标 掌阅科技申请AI相关商标
云鲸发布全新的扫拖机器人J4系列
MiracleVision视觉大模型上线时间
AI浪潮席卷,时空壶为何能成为AI翻译时代的破局者
全媒封面丨⑤商汤科技:原创AI算法“发电厂”
七大主流AI企业包括OpenAI、谷歌等联合承诺:引入水印技术,并允许第三方审核AI内容
《流浪地球2》里机器人公司的创始人:未来10年,机器人的崛起!
无人机协助盐城交通执法的协同训练
昇腾AI大模型训推一体化解决方案将在WAIC发布
昇思开源社区理事会成立,基于昇思AI框架的全模态大模型“紫东.太初2.0”发布
京东 AI 大模型官宣 7 月 13 日发布,还有重磅合作
无人机自主巡检为高海拔输电线路运维添“新彩”
如何利用物联网技术提高企业生产线智能化水平,提升生产效率
2025世界人工智能大会(上海)开幕式纪要
AI大模型紫东太初已被注册商标 中科院已注册紫东太初大模型商标
生成式人工智能来了,如何保护未成年人? | 社会科学报
闪电快讯|京东推出言犀AI大模型 面向零售、医疗、物流等产业场景
马斯克回应“人工智能让一切变得更好”:我们已经是半机器人了
发布最新版本的 PICO OS 5.7.0:支持VR头盔录屏并跨平台分享至微信
人工智能写作检测工具不靠谱,美国宪法竟被认为是机器人写的
B站内测 AI 搜索功能,输入“?”即可体验
论文插图也能自动生成了,用到了扩散模型,还被ICLR接收
Transformer六周年:当年连NeurIPS Oral都没拿到,8位作者已创办数家AI独角兽
2025世界人工智能大会成功召开
时隔 4 年:谷歌更新安卓机器人 LOGO,形象更立体
GPT-4不能在麻省理工学院获得计算机科学学位
数据显示:人工智能相关专业热度上升最快 考古、美术、生物医学工程等小众专业火了
以分布式网络串联闲置GPU,这家创企称可将AI模型训练成本降低90%
苹果2万5的AR遭遇砍单95%:不及预期
华为AI大模型将融入HarmonyOS 4
Databricks 发布大数据分析平台 Spark 用 AI 模型 SDK:一键生成 SQL 及 FySpark 语言图表代码
马克龙密会AI专家,法国加入全球人工智能竞赛
中国移动主导创立元宇宙产业联盟,包括科大讯飞、芒果TV等在内,共24家成员
特斯拉 Optimus 人形机器人入驻北美门店,帮助提升汽车销量
生成式AI爆发,亚马逊云科技持续专注创新,助力企业数字化转型
华为发布两款AI存储新品
国内通用人形机器人将发布、产业加速突破
7/8上海 | 2025世界人工智能大会分论坛:科技与人文-共筑无障碍智能社会
1分钟做出苹果Vision Pro「官网」?上班8小时搞出480个网页,同事被卷疯了
改动一行代码,PyTorch训练三倍提速,这些「高级技术」是关键
选对AI智能写作软件,让创作游刃有余!
探展WAIC | 第四范式“式说”聚焦toB大模型,布局生成式AI重构企业软件
第四范式「式说」大模型入选《2025年通用人工智能创新应用案例集》
国内AI大模型“安卓时刻”到来!阿里云通义千问免费、开源、可商用
应用生成式人工智能技术改善农业产业
马斯克:将来机器人比人类多!特斯拉机器人亮相人工智能大会
两架海燕号无人机交付中国气象局 助力建设国家级机动气象观测业务
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

