


400 128 6709

行业新闻
 发布时间:2023-06-27
发布时间:2023-06-27 点击次数:
点击次数: 生成式 AI 已经风靡了人工智能社区,无论是个人还是企业,都开始热衷于创建相关的模态转换应用,比如文生图、文生视频、文生音乐等等。
最近呢,来自 ServiceNow Research、LIVIA 等科研机构的几位研究者尝试基于文本描述生成论文中的图表。为此,他们提出了一种 FigGen 的新方法,相关论文还被 ICLR 2025 收录为了 Tiny Paper。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
论文地址:https://arxiv.org/pdf/2306.00800.pdf
也许有人会问了,生成论文中的图表有什么难的呢?这样做对于科研又有哪些帮助呢?
科研图表生成有助于以简洁易懂的方式传播研究结果,而自动生成图表可以为研究者带来很多优势,比如节省时间和精力,不用花大力气从头开始设计图表。此外设计出具有视觉吸引力且易理解的图表能使更多的人访问论文。
然而生成图表也面临一些挑战,它需要表示框、箭头、文本等离散组件之间的复杂关系。与生成自然图像不同,论文图表中的概念可能有不同的表示形式,需要细粒度的理解,例如生成一个神经网络图会涉及到高方差的不适定问题。
因此,本文研究者在一个论文图表对数据集上训练了一个生成式模型,捕获图表组件与论文中对应文本之间的关系。这就需要处理不同长度和高技术性文本描述、不同图表样式、图像长宽比以及文本渲染字体、大小和方向问题。
在具体实现过程中,研究者受到了最近文本到图像成果的启发,利用扩散模型来生成图表,提出了一种从文本描述生成科研图表的潜在扩散模型 ——FigGen。
这个扩散模型有哪些独到之处呢?我们接着往下看细节。
研究者从头开始训练了一个潜在扩散模型。
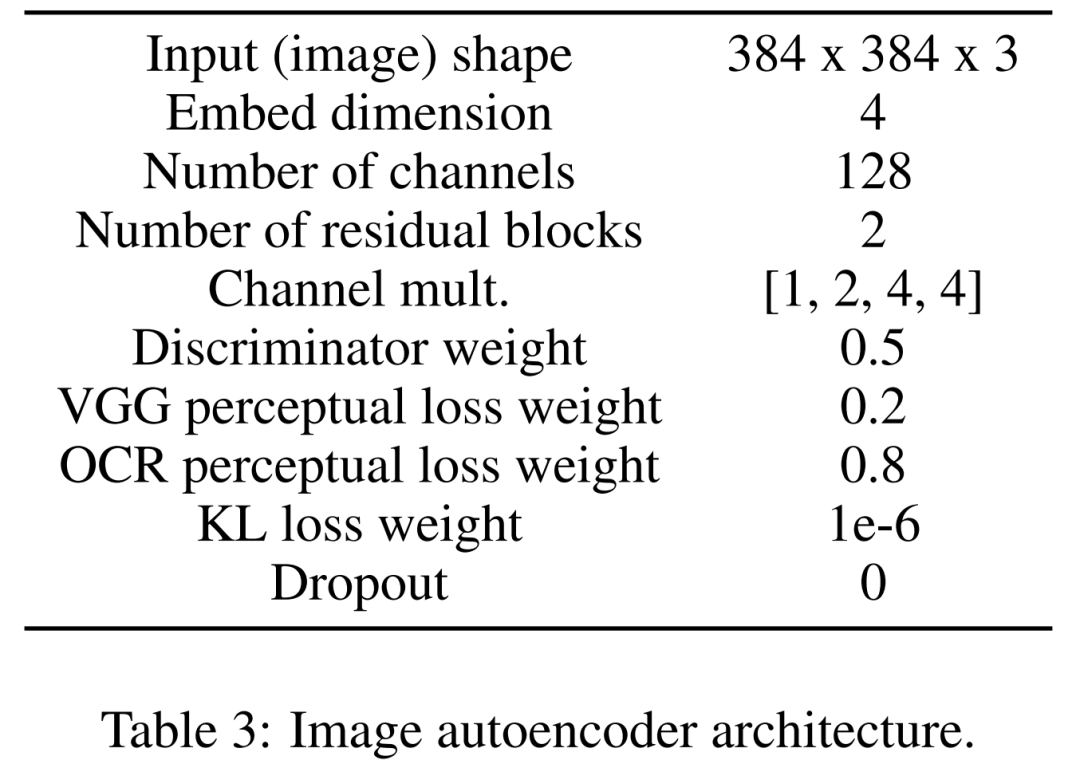
首先学习一个图像自动编码器,用来将图像映射为压缩的潜在表示。图像编码器使用 KL 损失和 OCR 感知损失。调节所用的文本编码器在该扩散模型的训练中端到端进行学习。下表 3 为图像自动编码器架构的详细参数。
然后,该扩散模型直接在潜在空间中进行交互,执行数据损坏的前向调度,同时学习利用时间和文本条件去噪 U-Net 来恢复该过程。
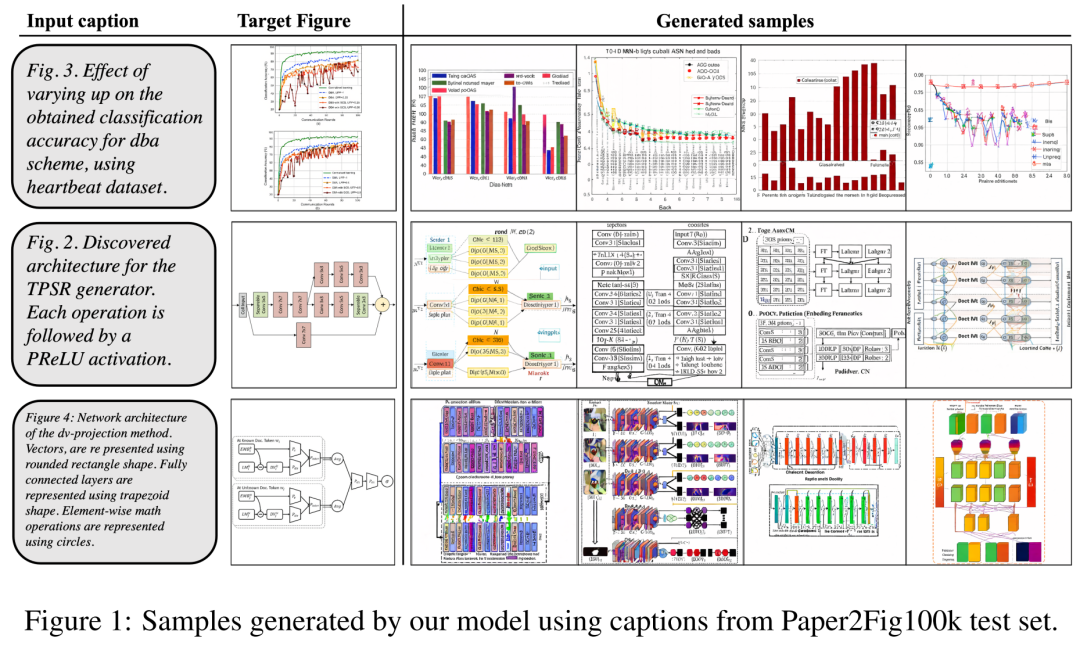
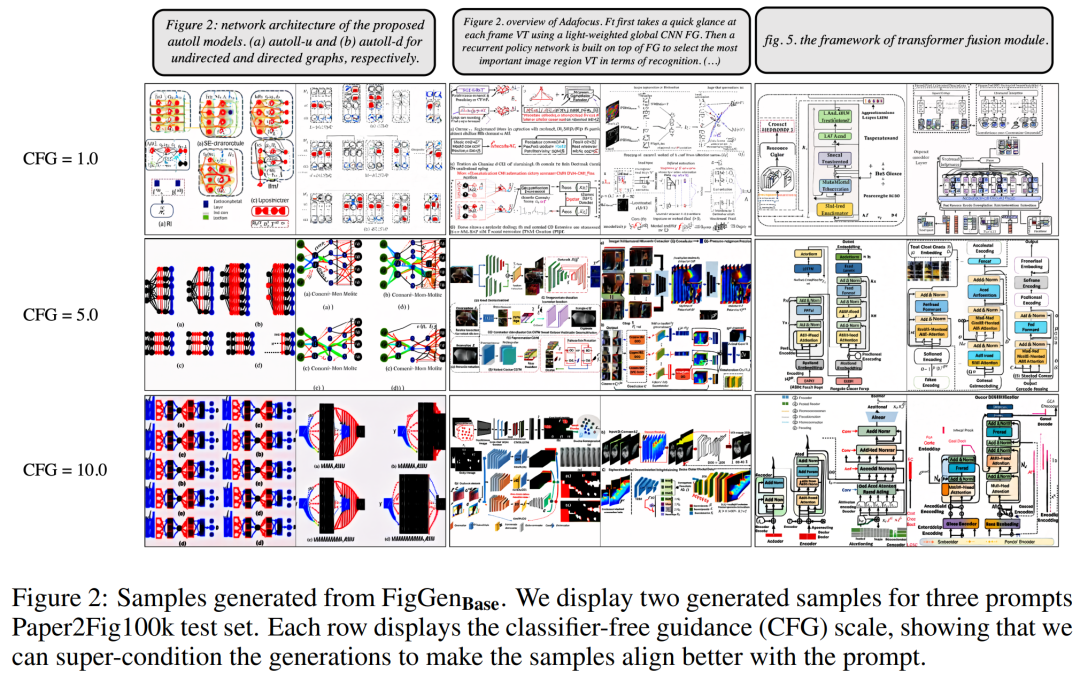
至于数据集,研究者使用了 Paper2Fig100k,它由论文中的图表文本对组成,包含了 81,194 个训练样本和 21,259 个验证样本。下图 1 为 Paper2Fig100k 测试集中使用文本描述生成的图表示例。
模型细节
首先是图像编码器。第一阶段,图像自动编码器学习一个从像素空间到压缩潜在表示的映射,使扩散模型训练更快。图像编码器还需要学习将潜在图像映射回像素空间,同时不丢失图表重要细节(如文本渲染质量)。
为此,研究者定义了一个具有瓶颈的卷积编解码器,在因子 f=8 时对图像进行下采样。编码器经过训练可以最小化具有高斯分布的 KL 损失、VGG 感知损失和 OCR 感知损失。
其次是文本编码器。研究者发现通用文本编码器不太适合生成图表任务。因此他们定义了一个在扩散过程中从头开始训练的 Bert transformer,其中使用大小为 512 的嵌入通道,这也是调节 U-Net 的跨注意力层的嵌入大小。研究者还探索了不同设置下(8、32 和 128)的 transformer 层数量的变化。
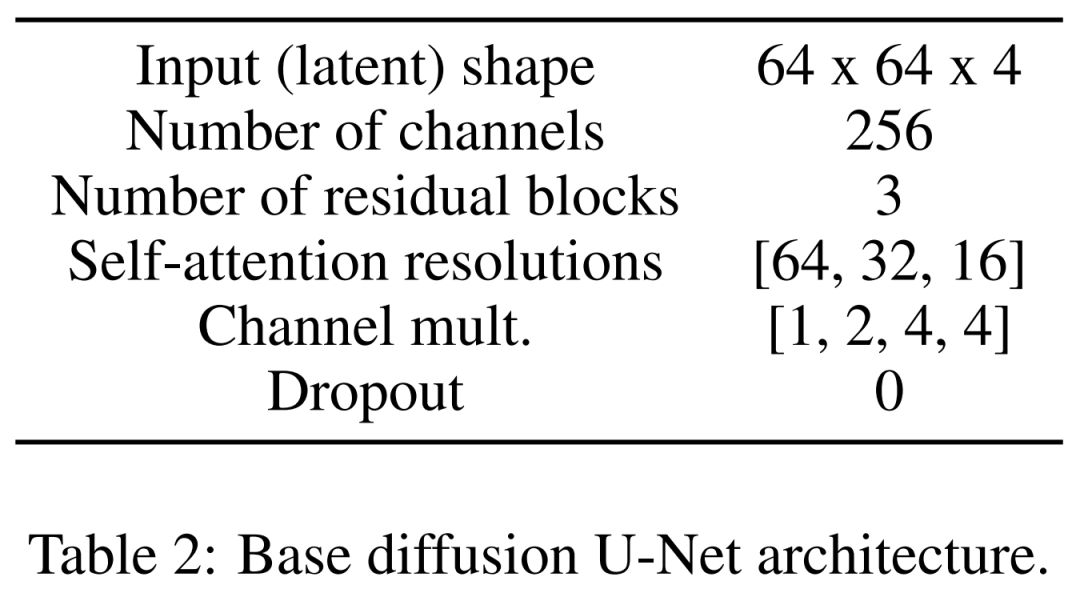
最后是潜在扩散模型。下表 2 展示了 U-Net 的网络架构。研究者在感知上等效的图像潜在表示中执行扩散过程,其中该图像的输入大小被压缩到了 64x64x4,使扩散模型更快。他们定义了 1,000 个扩散步骤和线性噪声调度。
训练细节
 ChatGPT Writer
ChatGPT Writer
免费 Chrome 扩展程序,使用 ChatGPT AI 生成电子邮件和消息。
 106
查看详情
106
查看详情

为了训练图像自动编码器,研究者使用了一个 Adam 优化器,它的有效批大小为 4 个样本、学习率为 4.5e−6,期间使用了 4 个 12GB 的英伟达 V100 显卡。为了实现训练稳定性,他们在 50k 次迭代中  warmup 模型,而不使用判别器。
warmup 模型,而不使用判别器。
对于训练潜在扩散模型,研究者也使用 Adam 优化器,它的有效批大小为 32,学习率为 1e−4。在 Paper2Fig100k 数据集上训练该模型时,他们用到了 8 块 80GB 的英伟达 A100 显卡。
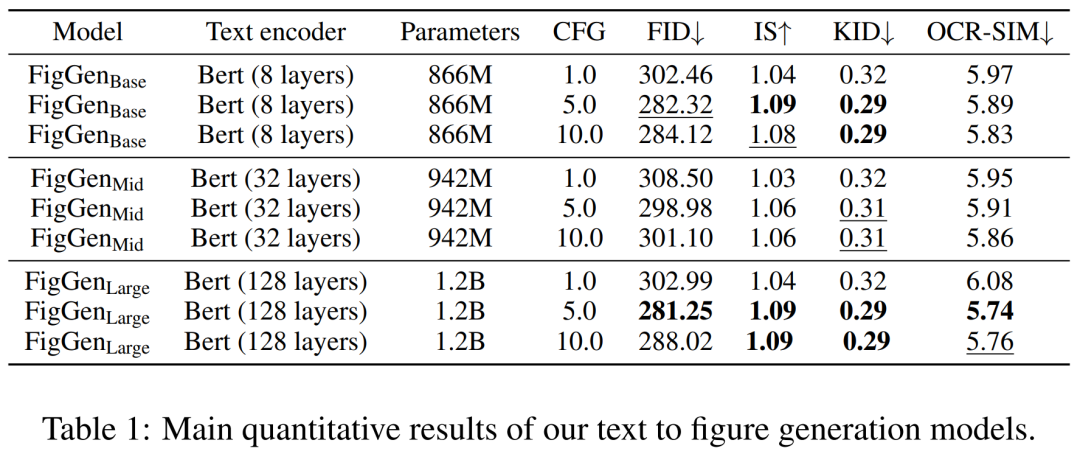
在生成过程中,研究者采用了具有 200 步的 DDIM 采样器,并且为每个模型生成了 12,000 个样本来计算 FID, IS, KID 以及 OCR-SIM1。稳重使用无分类器指导(CFG)来测试超调节。
下表 1 展示了不同文本编码器的结果。可见,大型文本编码器产生了最好的定性结果,并且可以通过增加 CFG 的规模来改进条件生成。虽然定性样本没有足够的质量来解决问题,但 FigGen 已经掌握了文本和图像之间的关系。
下图 2 展示了调整无分类器指导(CFG)参数时生成的额外 FigGen 样本。研究者观察到增加 CFG 的规模(这在定量上也得到了体现)可以带来图像质量的改善。
 图片
图片
下图 3 展示了 FigGen 的更多生成示例。要注意样本之间长度的变化,以及文本描述的技术水平,这会密切影响到模型正确生成可理解图像的难度。
 图片
图片
不过研究者也承认,尽管现在这些生成的图表不能为论文作者提供实际帮助,但仍不失为一个有前景的探索方向。
更多研究细节请参阅原论文。
以上就是论文插图也能自动生成了,用到了扩散模型,还被ICLR接收的详细内容,更多请关注其它相关文章!
# 解决问题
# 数据网站建设论文范文
# 怎样优化网站搜索关键词
# 和平区seo优化排名
# 网站seo综合测评
# 邹城市谷歌网站优化
# 佛山营销seo推广公司
# 黄陂seo优化诊断
# seo 培训网站
# seo设计是什么意思
# seo基础帮你火星12服务
# 更快
# ai
# 谁能
# 提出了
# 展示了
# 过程中
# 下表
# 开源
# 自动生成
# 也能
# fig
# 论文
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
OpenAI首席执行官表态支持欧盟AI监管
腾讯TRS之元学习与跨域推荐的工业实战
360发布认知型通用大模型“360智脑4.0” 全面接入360全家桶
Snap宣布研发出新技术 可大幅提升AI生成图像速度
数字彩排、虚拟建厂!这家顶级洗衣机工厂敲开“工业元宇宙”之门
昇腾AI大模型训推一体化解决方案将在WAIC发布
“长沙造”无人机,领先的不止植保
全新升级的广州麦当劳:面积最大餐厅正式引入智慧机器人
洞穴探险神器?可自主导航的单旋翼自旋无人机,效率更高!
科技赋能司法执行 阿里资产免费为全国法院升级VR新服务
618京东3C数码趋势产品备受青睐 AR设备成交额同比增长15倍
小米又拿下国际比赛第一:AI翻译立功
360°/180°双模式,佳能公布可折叠小体积的VR全景相机
大疆 Air 3 无人机售价和实物照片曝光
Adobe旗下Illustrator引入生成式AI工具Firefly
AI大模型产品集体奔赴高考考场,教育赛道的讯飞星火能赢吗?
华为云发布华为云盘古模型3.0和升腾AI云服务,亮点亮相2025华为开发者大会
OpenAI已向中国申请注册“GPT-5”商标,此前已在美国提交申请
物联网“僵尸网络DDos攻击”增长惊人,威胁全球电信网络
携程发布旅游行业垂直大模型 梁建章:AI策略是做可靠的内容 放心的推荐
2025 世界人工智能大会闭幕,32 个重大产业签约总额达 288 亿元
焊接协作机器人或将成为26届埃森展最大看点
Xbox游戏工作室负责人:VR/AR领域的用户规模还不足够
AMD称下半年AI显卡供应充足,不需要像NVIDIA那样加价抢购
脑机接口产业联盟发布十大脑机接口关键技术
LinkedIn 推出生成式 AI 辅助撰写帖文功能,将向所有用户开放
联想首发AI PC于今年秋季,英特尔CEO确认AI PC时代来临
AI工具助力公司实施每周4.5天工作制,带来巨大效益
PS AI修图免费平替来了!Stability AI又放大招,核弹级更新一键扩图
「社交达人」GPT-4!解读表情、揣测心理全都会
美图设计室2.0什么时候上线
微软在德国举办MR研讨会,向女性分享元宇宙潜力
联想浏览器引入小乐 AI 助手,成功接入百度文心一言大模型,经过实测证实
午报 | 字节跳动要造机器人;东方甄选首次启动自有APP|直播|
Nature发AIGC禁令!投稿中视觉内容使用AI的概不接收
AI成政客博弈工具,美国大选真假难辨,律师们的生意来了
日媒关注中国推进鸟类识别 AI 普及,除监测保护外还可预防传染性疾病
Unity发布Sentis和Muse AI工具,助力创作游戏和3D内容
Snow Kylin登陆中国列车,打造全球首条元宇宙专列
丰田汽车研究院推出生成式人工智能汽车设计工具
Meta 推出 Quest 超级分辨率技术,让 VR 画面更清晰
调查:过半数艺术家认为 AI 作图无法帮助他们的工作
华为云盘古大模型3.0发布 AI云服务同时上线:200亿亿次性能
陈根:AI冥想教练为用户提供个性化指导
开创全新虚拟现实体验的Pimax Crystal VR头显
赋能金融新生态,多家银行创新应用成果亮相世界人工智能大会
杀入生成式AI的亚马逊云科技,能否再次生成未来?
“可用”“有用”的讯飞星火认知大模型将亮相世界人工智能大会
映宇宙集团执行总编辑:元宇宙还是要以人为媒介
普林斯顿大学推出Infinigen AI模型 可生成真实自然环境 3D场景
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

