


400 128 6709

行业新闻
 发布时间:2024-03-01
发布时间:2024-03-01 点击次数:
点击次数: 大型语言模型 (llm) 被广泛应用于需要多个链式生成调用、高级提示技术、控制流以及与外部环境交互的复杂任务。尽管如此,目前用于编程和执行这些应用程序的高效系统却存在明显的不足之处。
研究人员最近提出了一种新的结构化生成语言(Structured Generation Language),称为SGLang,旨在改进与LLM的交互性。通过整合后端运行时系统和前端语言的设计,SGLang使得LLM的性能更高、更易控制。这项研究也获得了机器学习领域的知名学者、CMU助理教授陈天奇的转发。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
总的来说,SGLang 的贡献主要包括:
在后端,研究团队提出了 RadixAttention,这是一种跨多个 LLM 生成调用的 KV 缓存(KV cache)复用技术,自动且高效。
在前端开发中,团队研究出一种灵活的域特定语言,可嵌入Python,用于控制生成过程。这种语言可以在解释器模式或编译器模式下执行。
后端前端组件协同工作,可提高复杂 LLM 程序的执行和编程效率。
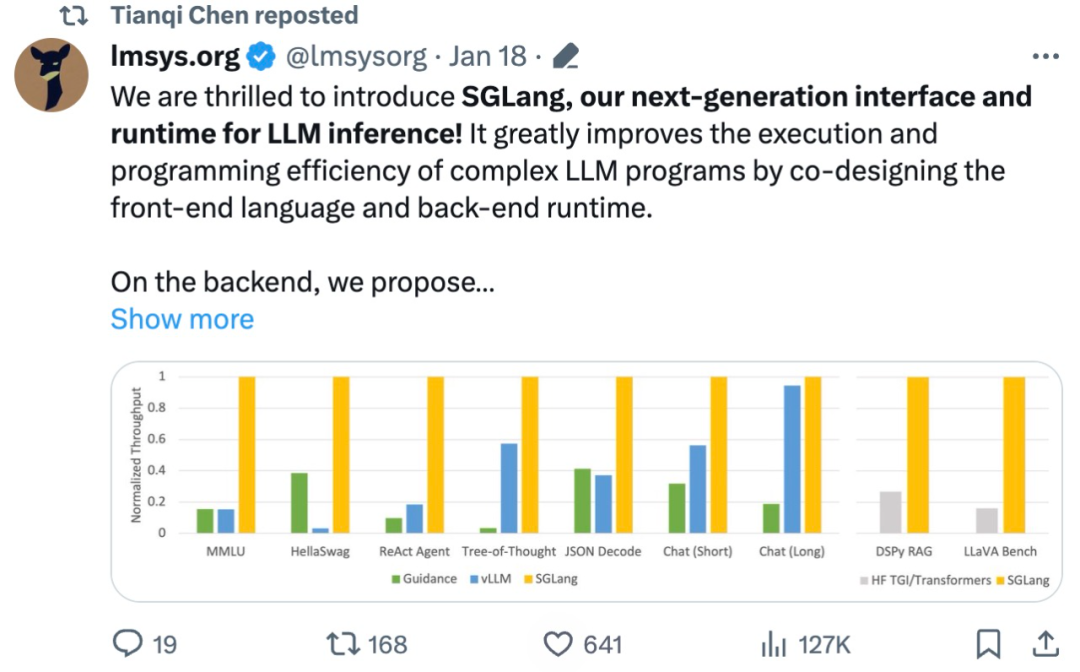
该研究使用 SGLang 实现了常见的 LLM 工作负载,包括智能体、推理、提取、对话和小样本学习任务,并在 NVIDIA A10G GPU 上采用 Llama-7B 和 Mixtral-8x7B 模型。如下图 1 、图 2 表明,与现有系统(即 Guidance 和 vLLM)相比,SGLang 的吞吐量提高了 5 倍。

图 1:不同系统在 LLM 任务上的吞吐量(A10G、FP16 上的 Llama-7B、张量并行度 = 1)
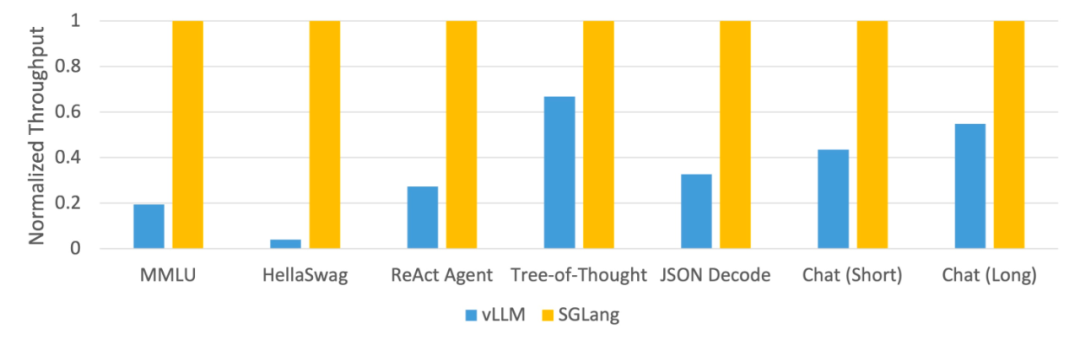
图 2:不同系统在 LLM 任务上的吞吐量(A10G、FP16 上的 Mixtral-8x7B,张量并行度 = 8)
后端:使用 RadixAttention 自动 KV 缓存复用
在 SGLang 运行时的开发过程中,该研究发现了复杂 LLM 程序的优化关键 ——KV 缓存复用,当前系统对此处理不佳。KV 缓存复用意味着具有相同前缀的不同 prompt 可以共享中间 KV 缓存,避免冗余的内存和计算。在涉及多个 LLM 调用的复杂程序中,可能存在各种 KV 缓存复用模式。下图 3 说明了 LLM 工作负载中常见的四种此类模式。虽然某些系统能够在某些场景下处理 KV 缓存复用,但通常需要手动配置和临时调整。此外,由于可能的复用模式的多样性,即使通过手动配置,现有系统也无法自动适应所有场景。
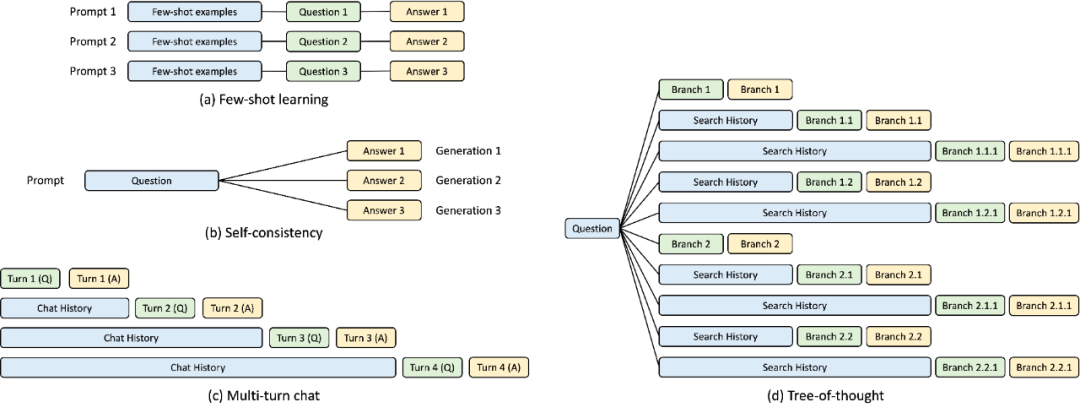
图 3:KV 缓存共享示例。蓝色框是可共享的 prompt 部分,绿色框是不可共享的部分,黄色框是不可共享的模型输出。可共享的部分包括小样本学习示例、自洽(self-consistency)问题、多轮对话中的对话历史以及思维树(tree-of-thought)中的搜索历史。
为了系统地利用这些复用机会,该研究提出了一种在运行时自动 KV 缓存复用的新方法 —— RadixAttention。该方法不是在完成生成请求后丢弃 KV 缓存,而是在基数树(radix tree)中保留 prompt 和生成结果的 KV 缓存。这种数据结构可以实现高效的前缀搜索、插入和驱逐。该研究实现了最近最少使用(LRU)驱逐策略,并辅以缓存感知调度策略,以提高缓存命中率。
基数树可作为 trie(前缀树)节省空间的替代方案。与典型的树不同,基数树的边缘不仅可以用单个元素来标记,还可以用不同长度的元素序列来标记,这提高了基数树的效率。
该研究利用基数树来管理映射,这种映射是在充当键的 token 序列和充当值的相应 KV 缓存张量之间进行的。这些 KV 缓存张量以分页布局存储在 GPU 上,其中每个页的大小相当于一个 token。
 Machine Translation
Machine Translation
聚合多个来源的AI翻译
 49
查看详情
49
查看详情

考虑到 GPU 内存容量有限,无法重新训练无限的 KV 缓存张量,这就需要驱逐策略。该研究采用 LRU 驱逐策略,递归地驱逐叶节点。此外,RadixAttention 与连续批处理和分页注意力等现有技术兼 容。对于多模态模型,RadixAttention 可以轻松扩展以处理图像 token。
容。对于多模态模型,RadixAttention 可以轻松扩展以处理图像 token。
下图说明了在处理多个传入请求时如何维护基数树。前端总是向运行时发送完整的 prompt,运行时会自动进行前缀匹配、复用和缓存。树形结构存储在 CPU 上,维护开销较小。
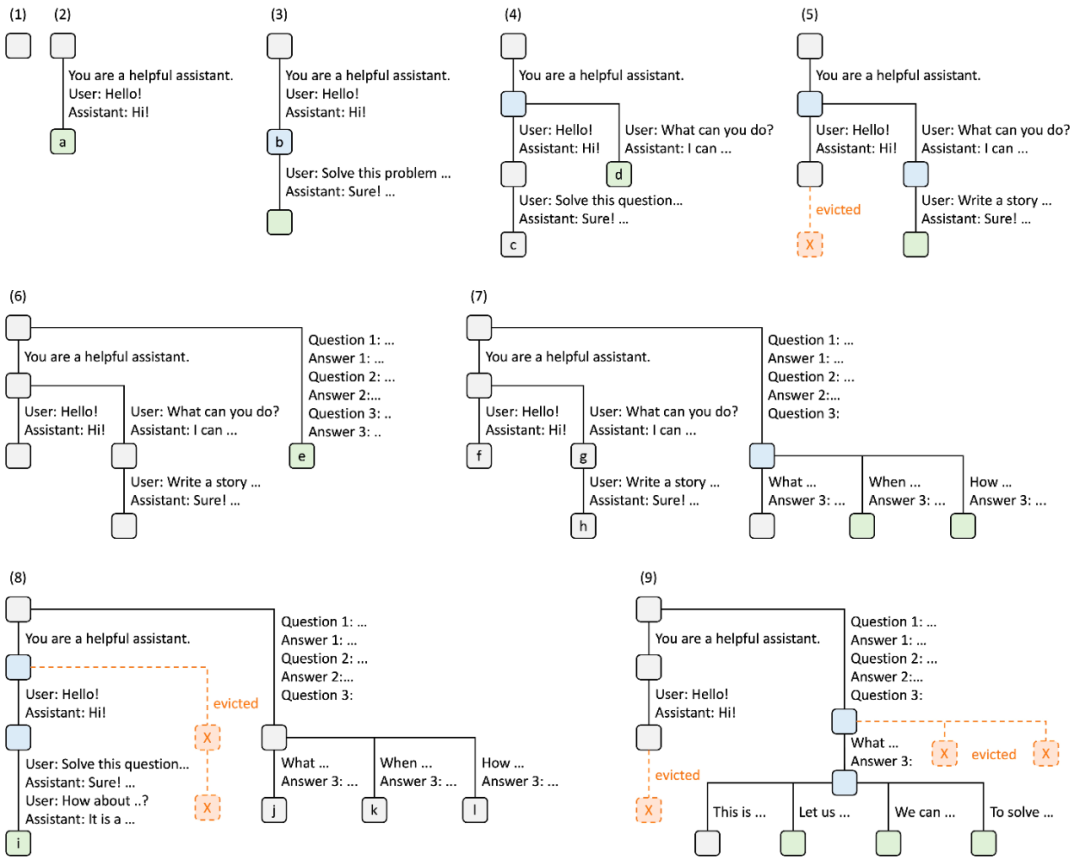
图 4. 采用 LRU 驱逐策略的 RadixAttention 操作示例,分九个步骤进行说明。
图 4 演示了基数树响应各种请求的动态演变。这些请求包括两个聊天会话、一批小样本学习查询和自洽性抽样。每个树边缘都带有一个标签,表示子字符串或 token 序列。节点采用颜色编码以反映不同的状态:绿色表示新添加的节点,蓝色表示在该时间点访问的缓存节点,红色表示已被驱逐的节点。
前端:使用 SGLang 轻松进行 LLM 编程
在前端,该研究提出了 SGLang,一种嵌入在 Python 中的特定于领域的语言,允许表达高级 prompt 技术、控制流、多模态、解码约束和外部交互。SGLang 函数可以通过各种后端运行,例如 OpenAI、Anthropic、Gemini 和本地模型。
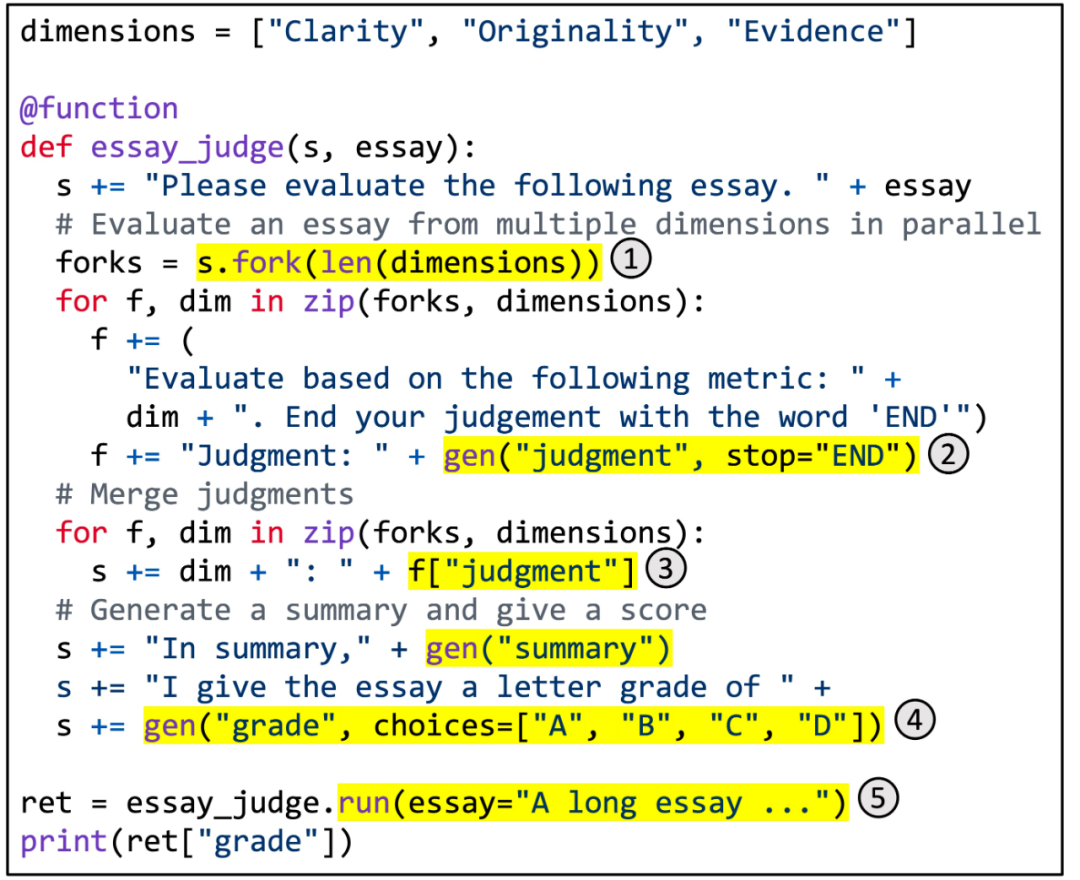
图 5. 用 SGLang 实现多维文章评分。
图 5 显示了一个具体示例。它利用分支 - 解决 - 合并 prompt 技术实现多维文章评分。该函数使用 LLM 从多个维度评估文章的质量,合并判断,生成摘要,并分配最终等级。突出显示的区域说明了 SGLang API 的使用。(1) fork 创建 prompt 的多个并行副本。(2) gen 调用 LLM 生成并将结果存储在变量中。该调用是非阻塞的,因此它允许多个生成调用在后台同时运行。(3) [variable_name] 检索生成的结果。(4) 选择对生成施加约束。(5) run 使用其参数执行 SGLang 函数。
给定这样一个 SGLang 程序,我们可以通过解释器执行它,也可以将其跟踪为数据流图并使用图执行器运行它。后一种情况为一些潜在的编译器优化开辟了空间,例如代码移动、指令选择和自动调整。
SGLang 的语法很大程度上受到 Guidance 的启发,并引入了新的原语,还处理程序内并行性和批处理。所有这些新功能都有助于 SGLang 的出色性能。
基准测试
研究团队在常见的 LLM 工作负载上测试了其系统,并报告了所实现的吞吐量。
具体来说,该研究在 1 个 NVIDIA A10G GPU (24GB) 上测试了 Llama-7B,在 8 个具有张量并行性的 NVIDIA A10G GPU 上使用 FP16 精度测试了 Mixtral-8x7B,并使用 vllm v0.2.5、指导 v0.1.8 和 Hugging Face TGI v1.3.0 作为基准系统。
如图 1 和图 2 所示,SGLang 在所有基准测试中均优于基准系统,吞吐量提高了 5 倍。它在延迟方面也表现出色,特别是对于第一个 token 延迟,其中前缀缓存命中可以带来显著的好处。这些改进归功于 RadixAttention 的自动 KV 缓存复用、解释器实现的程序内并行性以及前端和后端系统的协同设计。此外,消融研究表明,即使没有缓存命中,也没有明显的开销,这会导致在运行时始终启用 RadixAttention。
参考链接:https://lmsys.org/blog/2025-01-17-sglang/
以上就是吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了的详细内容,更多请关注其它相关文章!
# sglang
# 工程
# 递归
# 复用
# 多个
# 后端
# 来了
# llama
# gemini
# hugging face
# 莱芜正宗网站优化价格
# 海豚知道网站推广
# 旅游网站建设地方
# 背景视频模板网站推广
# 长春优化推广网站
# 域名关键词排名查询工具
# 网站外链出去seo
# 触屏网站建设
# 拼多多网站的推广过程
# 国内快速网站建设设计
# 中国科学院
# 数据结构
# 多维
# 是在
# 提出了
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
厂商陆续公布AI进展 完美世界游戏展示复合应用AI in GamePlay
微软bing聊天推出AI购物工具 可进行比价并查看历史最低价
AI浪潮席卷,时空壶为何能成为AI翻译时代的破局者
全新升级的广州麦当劳:面积最大餐厅正式引入智慧机器人
直击上影节 | 光线传媒董事长王长田谈新技术:未来VR放映效果可能媲美影院
Snow Kylin登陆中国列车,打造全球首条元宇宙专列
看似低调,实则稳健:字节在AI路上会遇到什么?
热点 | 人工智能黄金时代开启
赋能选题探索:AI助手在经济学专业中的应用指南
以计算机视觉技术为基础的库存管理如何改革零售行业
“五年内人类程序员将消失”预言引争议,AI真的那么强大了吗?
国产工业机器人领域“暗潮涌动”,即将迎来新一轮复苏
研究表明 GPT-4 模型具备自我纠错能力,有望推动 AI 代码进一步商业化
郭帆谈ChatGPT:电影行业需要创新,否则人工智能将让电影变得平庸
人工智能和神经网络有什么联系与区别?
人工智能的变革之路:通过OpenAI的GPT-4漫游
两小时就能超过人类!DeepMind最新AI速通26款雅达利游戏
AI生成会议纪要 百度如流升级推出超级助手、智能编码等功能
DreamAvatar数字人使用教程
微软推出 LLaVA-Med AI 模型,可对医学病理案例进行分析
跑不动的元宇宙,虚拟世界比现实更冷酷
你大脑中的画面,现在可以高清还原了
看了天美对AI的布局,我感觉它想得是真明白
pixivFANBOX 更新运营规则,禁止通过外链绕开 AI 生成禁令
可按用户语气自动回复消息,Zoom 推出基于生成式 AI 的新功能
数据科学,解码智能未来——Altair首次提出“Frictionless AI”概念
谷歌推出 SAIF 框架,倡导安全环境下探索和发展人工智能
击败LLaMA?史上超强「猎鹰」排行存疑,符尧7行代码亲测,LeCun转赞
中国移动副总经理高同庆:打造人工智能时代的智能服务运营新范式
在这里见未来!杭州未来科技城全球AI盛会邀您共探最前沿
一公司推出喷火机器狗,可喷出 9 米长火焰
尼康尼克尔 Z 180-600mm f/5.6-6.3 VR 镜头发布,12499 元
羚客系统即将升级,推出全新的AI数字化工具
全球首款AI裸眼3D平板 国产的售价破万
零AI含量!纯随机数学无限生成逼真3D世界火了,普林斯顿华人一作
月薪6万,哪些AI岗位在抢人?
游族AI创新院揭牌成立 推进AI赋能游戏业务
优地网络助力新媒体拥抱人工智能时代
时间、空间可控的视频生成走进现实,阿里大模型新作VideoComposer火了
【机智云物联网低功耗转接板】远程环境数据采集探索
人工智能在交通领域的革新:智能解决方案彻底改变交通方式
Zoom远程会议应用:AI培训需经用户授权
AI新视野,增长新势能,伙伴云受邀出席笔记侠创业讲真话AI峰会
360发布认知型通用大模型“360智脑4.0” 全面接入360全家桶
AI 冥想应用 Ogimi.ai 推出,可为用户提供教练级个性化指导
泗洪:畅通城市“血管” ,管下机器人来帮忙
大疆 DJI Mini 4 Pro 无人机曝光:流线设计,有望迎来功能性提升
午报 | 字节跳动要造机器人;东方甄选首次启动自有APP|直播|
网易云音乐和小冰推出AI歌手音乐创作软件,首发内置12名AI歌手
学而思推出AI第一课:基于自研大模型的AIGC课程
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

