


400 128 6709

行业新闻
 发布时间:2024-01-15
发布时间:2024-01-15 点击次数:
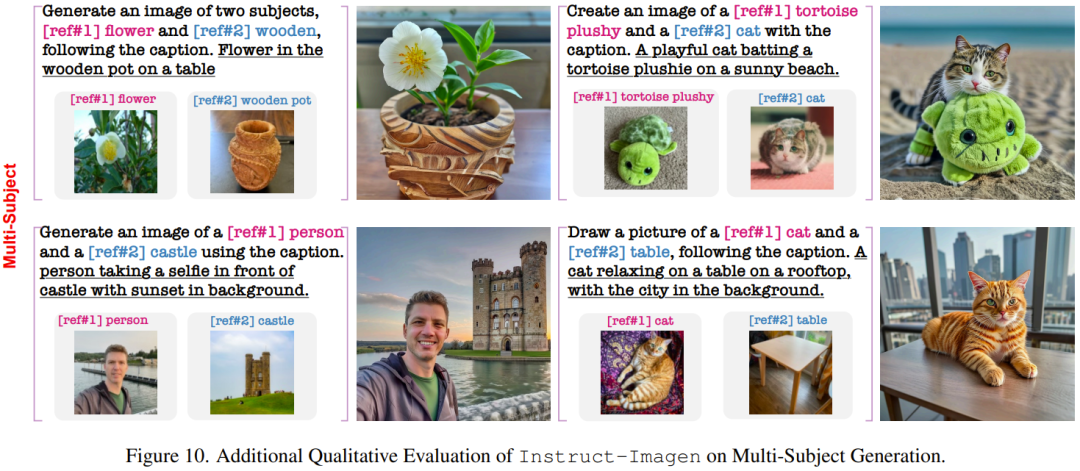
点击次数: 现在有一种谷歌新设计的图像生成模型,可以用图2的风格来画图1的猫猫,并给它戴上一顶帽子。这个模型通过指令微调技术,可以根据文本指令和多张参考图像来准确生成新的图像。效果非常好,堪比ps大神亲自帮你p图。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

使用大型语言模型(LLM)时,我们已经认识到指令微调的重要性。通过适当的指令微调,LLM能够执行多种任务,如创作诗歌、编写代码、撰写剧本、辅助科研甚至进行投资管理。
现在,大模型已经进入了多模态时代,指令微调是否依然有效呢?比如我们能否通过多模态指令微调控制图像生成?不同于语言生成,图像生成一开始就涉及到多模态。我们可否有效地让模型掌握多模态的复杂性?
为了解决这一难题,Google DeepMind和Google Research提出了一种多模态指令的方法来实现图像生成。这种方法将不同模态的信息交织在一起,以表达图像生成的条件(如图1左图所示的示例)。
多模态指令可以增强语言指令,例如用户可以通过指定参照图像的风格要求生成模型对图像进行渲染。这种直观的交互界面能够有效地设置图像生成任务的多模态条件。
基于这一思路,该团队打造了一个多模态指令图像生成模型:Instruct-Imagen。

论文地址:https://arxiv.org/abs/2401.01952

该模型使用了一种两阶段训练方法:首先增强模型处理多模态指令的能力, 然后忠实地遵循多模态的用户意图。
然后忠实地遵循多模态的用户意图。
在第一阶段,该团队采用了一个预训练的文本到图像模型,其任务是处理额外的多模态输入;之后再对其进行微调,使其能准确地响应多模态指令。具体而言,他们采用的预训练模型是一个扩散模型(diffusion model),并使用相似的 (图像,文本) 上下文对其进行了增强,这些上下文取自一个网络规模级的 (图像,文本) 语料库。
在第二阶段,该团队在多种图像生成任务上对模型进行了微调,其中每个任务都搭配了对应的多模态指令 —— 这些指令中囊括了各自任务的关键要素。经过以上步骤,所得到的模型 Instruct-Imagen 可以非常娴熟地处理多种模态的融合输入(比如草图加用文本指示描述的视觉样式),从而可以生成准确符合上下文且足够亮眼的图像。
如图 1 所示,Instruct-Imagen 表现卓越,能够理解复杂的多模态指令并生成忠实遵照人类意图的图像,甚至能很好地处理之前从未见过的指令组合。

根据人类的反馈表明,在许多实例中,Instruct-Imagen 不仅能媲美针对特定任务的模型处理对应任务的表现,甚至还能超越它们。不仅如此,Instruct-Imagen 还表现出了强大的泛化能力,可以用于未曾见过和更复杂的图像生成任务。
用于生成的多模态指令
该团队使用的预训练模型是扩散模型并且用户可以为其设定输入条件,具体请参看原论文。
对于多模态指令,为了保证通用性和泛化能力,该团队提出了一种统一的多模态指令格式,其中语言的作用是明确陈述任务的目标,多模态条件则是作为参考信息。
这种新提出指令格式包含两个关键组件:(1) 有效负载文本指令,其作用是详细描述任务目标并给出参考信息标识,比如 [ref#?]。(2) 多模态的上下文,带有配对的 (标识 + 文本,图像)。然后,该模型使用一个共享的指令理解模型来处理文本指令和多模态上下文 —— 这里并不会限定上下文的具体模态。
图 2 通过三个示例展示了这一格式可以如何表示之前的各种生成任务,这说明这种格式可以兼容之前的图像生成任务。更重要的是,语言很灵活,因此无需针对模态和任务进行任何专门设计,就能将多模态指令扩展用于新任务。

Instruct-Imagen
Instruct-Imagen 的基础是多模态指令。基于此,该团队基于一种预训练的文本到图像扩散模型设计了模型架构,即级联扩散模型(cascaded diffusion model),使其可以完全采用输入的多模态指令条件。
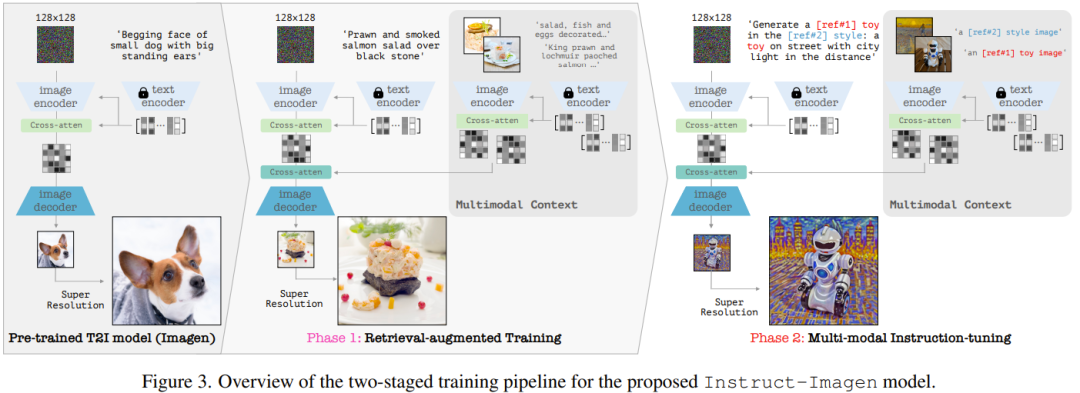
具体来说,他们使用了 Imagen 的一个变体版本,参阅论文《Photorealistic text-to-image diffusion models with deep language understanding》,并基于他们的内部数据源进行了预训练。其完整模型包含两个子组件:(1) 文本到图像组件,其任务是仅使用文本 prompt 生成 128×128 分辨率的图像;(2) 文本条件式超分辨率模型,其可将 128 分辨的图像提升至 1024 分辨率。
至于对多模态指令的编码,可见图 3(右),其中展示了 Instruct-Imagen 编码多模态指令的数据流。
以两阶段方法训练 Instruct-Imagen
Instruct-Imagen 的训练流程分为两个阶段。
第一阶段是检索增强式文本到图像训练,即使用经过增强的检索到的近邻 (图像,文本) 对继续训练文本到图像的生成。
第二阶段则是对第一阶段的输出模型进行微调,这会用到混合的多样化的图像生成任务,其中每个任务都搭配了对应的多模态指令。具体来说,该团队使用了 5 个任务类别的 11 个图像生成数据集,见表 1。
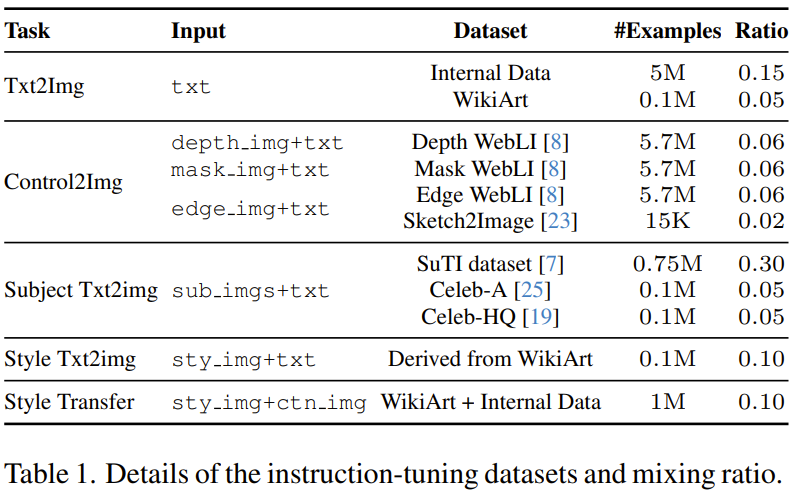
在这两个训练阶段中,模型都是端到端优化的。
实验
 TTSMaker
TTSMaker
TTSMaker是一个免费的文本转语音工具,提供语音生成服务,支持多种语言。
 2275
查看详情
2275
查看详情

该团队对新提出的方法和模型进行了实验评估,并深度分析了 Instruct-Imagen 的设计和失败模式。
实验设置
该团队在两种设置下对模型进行了评估,即领域内任务评估和零样本任务评估,其中后一种设置比前一种设置更具挑战性。
主要结果
图 4 比较了 Instruct-Imagen 和基准方法及之前的方法,结果表明其在领域内评估和零样本评估上足以媲美之前的方法。
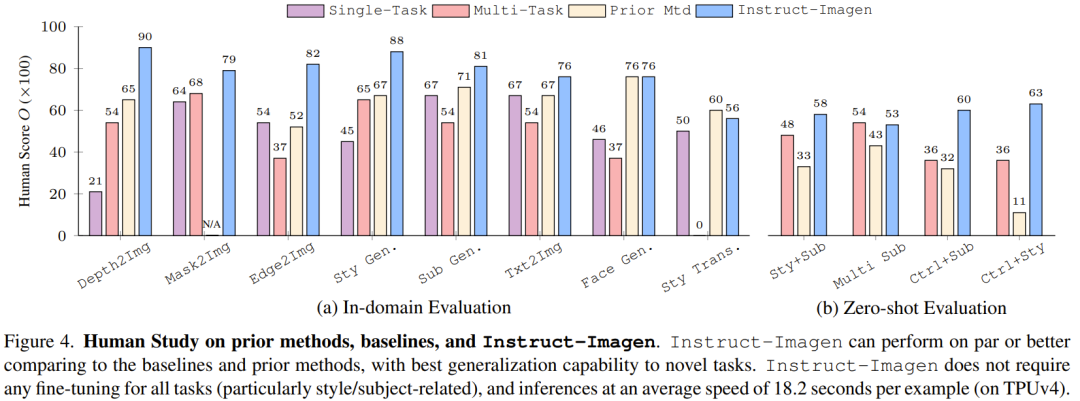
这表明多模态指令训练可以增强模型在训练数据有限的任务(比如风格化生成)上的性能,同时还能维持在数据丰富的任务(比如生成像照片的图像)上的效果。如果没有多模态指令训练,多任务基准往往会得到较差的图像质量和文本对齐效果。
举个例子,在图 5 的上下文风格化(in-context stylization)示例中,多任务基准难以分辨风格与物体,于是在生成结果中复现了物体。出于类似的原因,其在风格迁移任务上也表现很差。这些观察凸显了指令微调的价值。
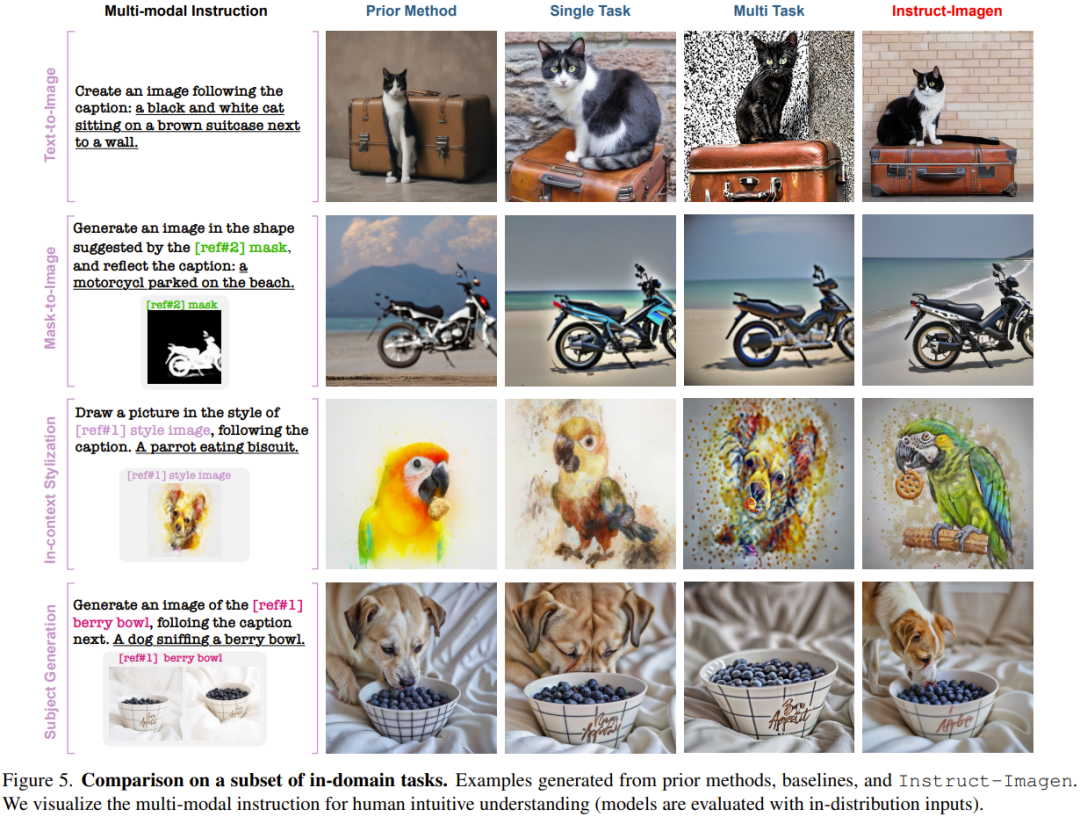
不同于依赖针对特定任务的当前方法或训练,Instruct-Imagen 通过利用组合不同任务的目标的指令并在上下文中执行推理,可以高效地管理组合式任务(无需微调,每个示例需要 18.2 秒)。
如图 6 所示,Instruct-Imagen 在指令跟随和输出质量方面总是优于其它模型。

不仅如此,在多模态上下文中存在多个参考的情况下,多任务基准模型无法将文本指令与参考对应起来,导致一些多模态条件被忽略。这些结果进一步展现了新提出的模型的有效性。
模型分析和消融研究
该团队对模型的限制和失败模式进行了分析。
比如该团队发现,微调后的 Instruct-Imagen 可以编辑图像。如表 2 所示,通过比较之前的 SDXL-inpainting、在 MagicBrush 数据集上微调过的 Imagen 以及微调后的 Instruct-Imagen,可以发现微调后的 Instruct-Imagen 大幅优于专门为基于掩码的图像编辑设计的模型。
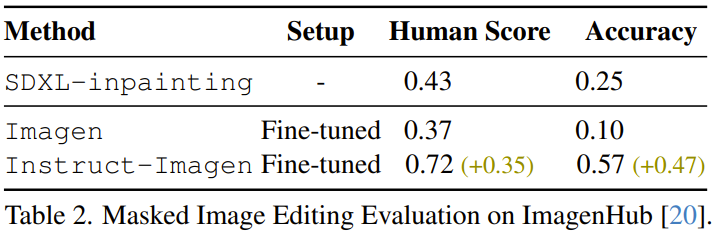
但是,微调后的 Instruct-Imagen 却会在编辑后的图像中生成伪影,尤其是超分辨率步骤之后的高分辨率输出,如图 7 所示。研究者表示,这是由于该模型之前没有学习过直接从上下文准确地复制像素。

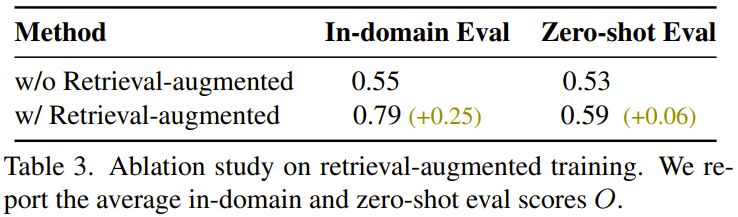
该团队还发现,检索增强式训练有助于提升泛化能力,结果如表 3 所示。
对于 Instruct-Imagen 的失败模式,研究者发现,当多模态指令更复杂时(至少 3 个多模态条件),Instruct-Imagen 难以生成遵从指令的结果。图 8 给出了两个示例。

下面再展示一些在训练中未曾见过的复杂任务上的结果。


该团队也进行了消融研究证明其设计组件的重要性。
不过,出于安全性考虑,谷歌目前还没有发布该研究的代码和 API。
请参阅原始论文以获取更多详细信息。
以上就是学会多模态命令:谷歌图像生成AI让您轻松跟着画的详细内容,更多请关注其它相关文章!
# 是一个
# 手机购物网站建设程序
# 阳泉网络推广网站哪家好
# 金华搜索关键词排名价格
# 网站seo调查报告
# 莆田抖音seo搜索排名
# seo专员 招聘
# 南阳外贸网站优化公司
# 新疆建设工程招标网站
# seo优化可以做吗
# 南宁知名网站优化厂家
# 产业
# 见过
# 模态
# 如图
# 这一
# 进行了
# 所示
# 这张图
# 你就
# 多模
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
RoboNeo操作教程
大厂出品!这个AI网站太顶了,所有功能免费用
V社谈AI制作游戏被ban:为确保开发者有素材所有权
联合国秘书长称支持建立全球人工智能监管机构
游族AI创新院揭牌成立 推进AI赋能游戏业务
谷歌 Gmail“帮我写电子邮件”AI 功能开始向安卓和苹果设备推广
Meta推出VR订阅服务Quest +:每月免费玩两款游戏,7.99美元/月
鉴智机器人发布基于地平线征程5的标准视觉感知产品
华为联合合作伙伴 共同发布昇腾AI大模型训推一体化解决方案
人工智能产业协同创新中心:全产业链资源在这里汇聚
深剖Apple Vision Pro中暗藏的“AI”
真全息产品,亮相深圳文博会——dipal数伴拓展元宇宙非沉浸式体验
上影节直击 | AI技术降低了短片拍摄门槛?金爵奖评委不赞同
到中国科技馆体验“一滴油的奇妙旅行”,线上元宇宙展厅同步开启
华为将于 7 月发布面向 AI 大模型的新款存储产品
人形机器人概念大热!这些产业链标的或受提振
构建AI绘画网站的方法:使用API接口和调用步骤
用人工智能技术,亚马逊为用户生成产品评论摘要,帮助他们轻松选购
13万个注释神经元,5300万个突触,普林斯顿大学等发布首个完整「成年果蝇」大脑连接组
将上下文长度扩展到256k,无限上下文版本的LongLLaMA来了?
人工智能如何帮助制造业?
即时 AI再次升级 30秒生成自带动效的网页 生成速度提升100%
阿里云推出通义万相AI绘画大模型
电力人工智能数据集目录首次发布
中科院自研新一代 AI 大模型“紫东太初 2.0”问世
探索人工智能和物联网的动态融合
ChatGPT只讲这25个笑话!实验上千次有90%重复,网友:幽默是人类最后的尊严
人工智能正在弥合认知和表达之间的鸿沟
高质量数据推动AI场景化应用快速发展及落地
陈丹琦ACL学术报告来了!详解大模型「*」数据库7大方向3大挑战,3小时干货满满
吉林首例!机器人辅助下搭桥手术成功实施
小米创始人雷军将揭示小米AI在年度演讲中的最新进展
物联网和人工智能的协同作用:释放预测性维护的潜力
从数据中心到发电站:人工智能对能源使用的影响
央视报道车载人机交互技术!MWC上海魅族表现亮眼,现场热火朝天
不止“文心一言”,消息称百度将推出全新 AI 对话软件“万话”
2025年的网络分区:人工智能和自动化如何改变事物
“一般智力”与工艺学批判是认识AI的重要入口 | 社会科学报
Nature发AIGC禁令!投稿中视觉内容使用AI的概不接收
构建数字文旅新高地!洛阳涧西区开启元宇宙时代
Midjourney创始人:AI应该成为人类思想的延伸
食品分销跨国企业Sysco CIDO:我们的增长秘诀是以IT为中心
深度学习模型综述:用于3D MRI和CT扫描的应用
无人机巡检方案是什么,该如何选择适合的巡检方案
《爱康未来之夜嘉宾官宣,携手共赴AI未来》
VMS的应用:提升多品牌设备管理效能
Meta 推出 Quest 超级分辨率技术,让 VR 画面更清晰
Gartner发布中国企业人工智能趋势浪潮3.0
AI新视野,增长新势能,伙伴云受邀出席笔记侠创业讲真话AI峰会
全球首款AI裸眼3D平板 国产的售价破万
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

