


400 128 6709

行业新闻
 发布时间:2023-07-02
发布时间:2023-07-02 点击次数:
点击次数: 我们知道,将激活、权重和梯度量化为 4-bit 对于加速神经网络训练非常有价值。但现有的 4-bit 训练方法需要自定义数字格式,而当代硬件不支持这些格式。在本文中,清华朱军等人提出了一种使用 int4 算法实现所有矩阵乘法的 transformer 训练方法。
模型训练得快不快,这与激活值、权重、梯度等因素的要求紧密相关。
神经网络训练需要一定计算量,使用低精度算法(全量化训练或 FQT 训练)有望提升计算和内存的效率。FQT 在原始的全精度计算图中增加了量化器和去量化器,并将昂贵的浮点运算替换为廉价的低精度浮点运算。
对 FQT 的研究旨在降低训练数值精度,同时降低收敛速度和精度的牺牲。所需数值精度从 FP16 降到 FP8、INT32+INT8 和 INT8+INT5。FP8 训练通过有 Transformer 引擎的 Nvidia H100 GPU 完成,这使大规模 Transformer 训练实现了惊人的加速。
最近训练数值精度已被压低到 4 位( 4 bits)。Sun 等人成功训练了几个具有 INT4 激活 / 权重和 FP4 梯度的当代网络;Chmiel 等人提出自定义的 4 位对数数字格式,进一步提高了精度。然而,这些 4 位训练方法不能直接用于加速,因为它们需要自定义数字格式,这在当代硬件上是不支持的。
在 4 位这样极低的水平上训练存在着巨大的优化挑战,首先前向传播的不可微分量化器会使损失函数图不平整,其中基于梯度的优化器很容易卡在局部最优。其次梯度在低精度下只能近似计算,这种不精确的梯度会减慢训练过程,甚至导致训练不稳定或发散的情况出现。
本文为流行的神经网络 Transformer 提出了新的 INT4 训练算法。训练 Transformer 所用的成本巨大的线性运算都可以写成矩阵乘法(MM)的形式。MM 形式使研究人员能够设计更加灵活的量化器。这种量化器通过 Transformer 中的特定的激活、权重和梯度结构,更好地近似了 FP32 矩阵乘法。本文中的量化器还利用了随机数值线性代数领域的新进展。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
论文地址:https://arxiv.org/pdf/2306.11987.pdf
 Seele AI
Seele AI
3D虚拟游戏生成平台
 107
查看详情
107
查看详情

研究表明,对前向传播而言,精度下降的主要原因是激活中的异常值。为了抑制该异常值,研究提出了 Hadamard 量化器,用它对变换后的激活矩阵进行量化。该变换是一个分块对角的 Hadamard 矩阵,它将异常值所携带的信息扩散到异常值附近的矩阵项上,从而缩小了异常值的数值范围。
对反向传播而言,研究利用了激活梯度的结构稀疏性。研究表明,一些 token 的梯度非常大,但同时,其余大多数的 token 梯度又非常小,甚至比较大梯度的量化残差更小。因此,与其计算这些小梯度,不如将计算资源用于计算较大梯度的残差。
结合前向和反向传播的量化技术,本文提出一种算法,即对 Transformer 中的所有线性运算使用 INT4 MMs。研究评估了在各种任务上训练 Transformer 的算法,包括自然语言理解、问答、机器翻译和图像分类。与现有的 4 位训练工作相比,研究所提出的算法实现了相媲美或更高的精度。此外,该算法与当代硬件 (如 GPU) 是兼容的,因为它不需要自定义数字格式 (如 FP4 或对数格式)。并且研究提出的原型量化 + INT4 MM 算子比 FP16 MM 基线快了 2.2 倍,将训练速度提高了 35.1%。
在训练过程中,研究者利用 INT4 算法加速所有的线性算子,并将所有计算强度较低的非线性算子设置为 FP16 格式。Transformer 中的所有线性算子都可以写成矩阵乘法形式。为了便于演示,他们考虑了如下简单的矩阵乘法加速。
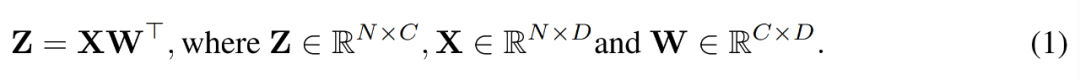 图片
图片
这种矩阵乘法的最主要用例是全连接层。
学得的步长量化
加速训练必须使用整数运算来计算前向传播。因此,研究者利用了学得的步长量化器(LSQ)。作为一种静态量化方法,LSQ 的量化规模不依赖于输入,因此比动态量化方法成本更低。相较之下,动态量化方法需要在每次迭代时动态地计算量化规模。
给定一个 FP 矩阵 X,LSQ 通过如下公式 (2) 将 X 量化为整数。
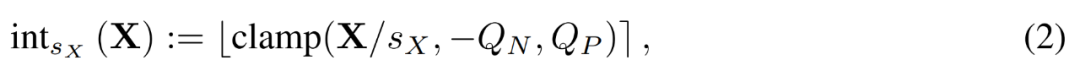 图片
图片
激活异常值
简单地将 LSQ 应用到具有 4-bit 激活 / 权重的 FQT(fully quantized training,全量化训练)中,会由于激活异常值而导致准确度下降。如下图 1 (a) 所示,激活的有一些异常值项,其数量级比其他项大得多。
在这种情况下,步长 s_X 在量化粒度和可表示数值范围之间进行权衡。如果 s_X 很大,则可以很好地表示异常值,同时代价是以粗略的方式表示其他大多数项。如果 s_X 很小,则必须截断 [−Q_Ns_X, Q_Ps_X] 范围之外的项。
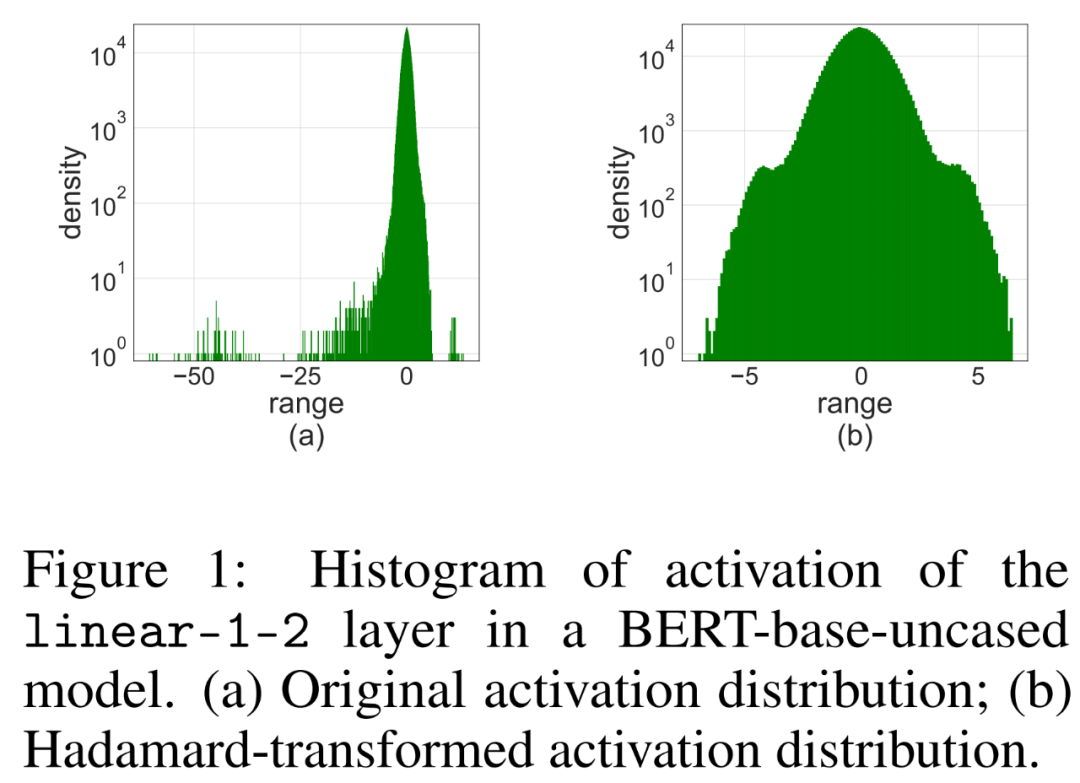
Hadamard 量化
研究者提出使用 Hadamard 量化器(HQ)来解决异常值问题,它的主要思路是在另一个异常值较少的线性空间中量化矩阵。
激活矩阵中的异常值可以形成特征级结构。这些异常值通常集中在几个维度上,也就是 X 中只有几列显著大于其他列。作为一种线性变换,Hadamard 变换可以将异常值分摊到其他项中。具体地,Hadamard 变换 H_k 是一个 2^k × 2^k 矩阵。
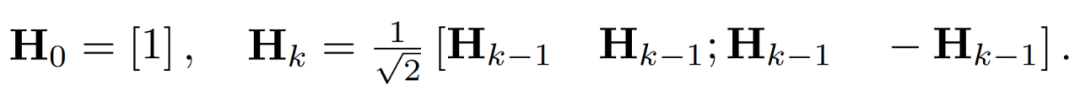
为了抑制异常值,研究者对 X 和 W 的变换版本进行量化。
和 W 的变换版本进行量化。
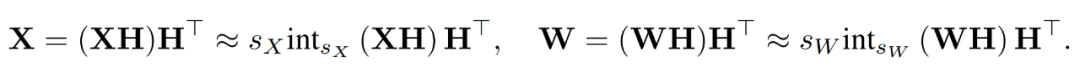
通过结合量化后的矩阵,研究者得到如下。
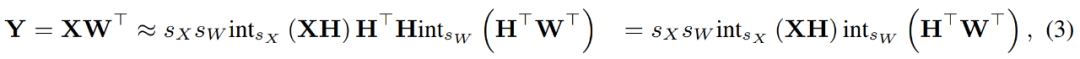
其中逆变换彼此之间相互抵消,并且 MM 可以实现如下。
 图片
图片
研究者使用 INT4 运算来加速线性层的反向传播。公式 (3) 中定义的线性算子 HQ-MM 具有四个输入,分别是激活 X、权重 W 以及步长 s_X 和 s_W。给定关于损失函数 L 的输出梯度∇_YL,他们需要计算这四个输入的梯度。
梯度的结构稀疏性
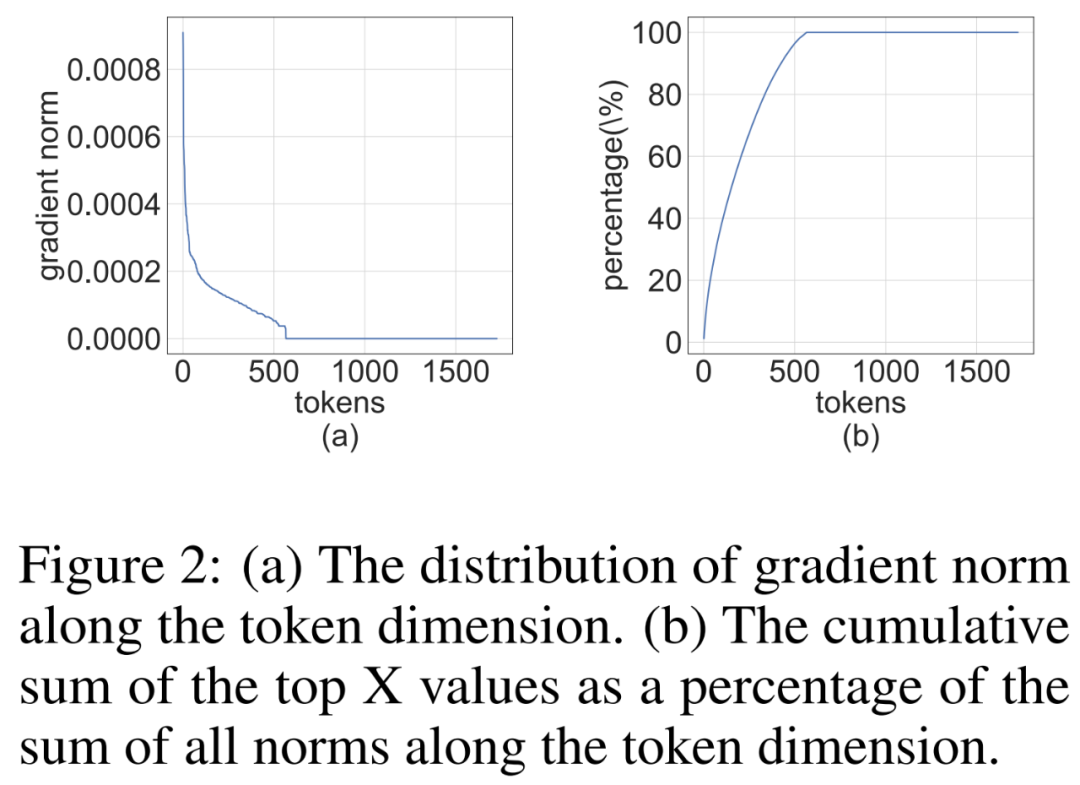
研究者注意到,训练过程中梯度矩阵∇_Y 往往非常稀疏。稀疏性结构是这样的:∇_Y 的少数行(即 tokens)具有较大的项,而大多数其他行接近全零向量。他们在下图 2 中绘制了所有行的 per-row 范数∥(∇_Y)_i:∥的直方图。
 图片
图片
Bit 拆分和平均分数采样
研究者讨论了如何设计梯度量化器,从而利用结构稀疏性在反向传播期间准确计算 MM。高级的思路是,很多行的梯度非常的小,因而对参数梯度的影响也很小,但却浪费了大量计算。此外,大行无法用 INT4 准确地表示。
为利用这种稀疏性,研究者提出 bit 拆分,将每个 token 的梯度拆分为更高的 4bits 和更低的 4bits。然后再通过平均分数采样选择信息量最大的梯度,这是 RandNLA 的一种重要性采样技术。
研究在各种任务中评估了 INT4 训练算法,包括语言模型微调、机器翻译和图像分类。研究使用了 CUDA 和 cutlass2 实现了所提出的 HQ-MM 和 LSS-MM 算法。除了简单地使用 LSQ 作为嵌入层外,研究用 INT4 替换了所有浮点线性运算符,并保持最后一层分类器的全精度。并且,在此过程中,研究人员对所有评估模型采用默认架构、优化器、调度器和超参数。
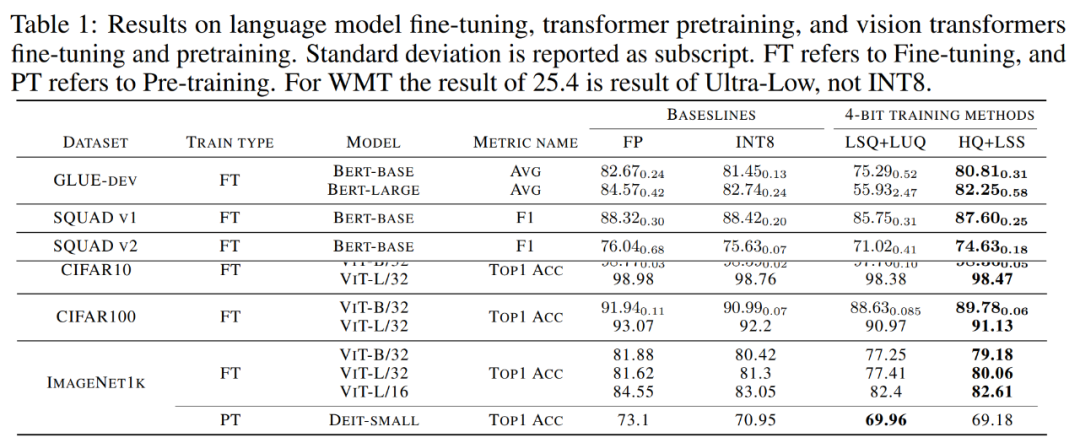
收敛模型精度。下表 1 展示了收敛模型在各任务上的精度。
 图片
图片
语言模型微调。与 LSQ+LUQ 相比,研究提出的算法在 bert-base 模型上提升了 5.5% 的平均精度、,在 bert-large 模型上提升了 25% 的平均精度。
研究团队还展示了算法在 SQUAD、SQUAD 2.0、Adversarial QA、CoNLL-2003 和 SWAG 数据集上进一步展示了结果。在所有任务上,与 LSQ+LUQ 相比,该方法取得了更好的性能。与 LSQ+LUQ 相比,该方法在 SQUAD 和 SQUAD 2.0 上分别提高了 1.8% 和 3.6%。在更困难的对抗性 QA 中,该方法的 F1 分数提高了 6.8%。在 SWAG 和 CoNLL-2003 上,该方法分别提高了 6.7%、4.2% 的精度。
机器翻译。研究还将所提出的方法用于预训练。该方法在 WMT 14 En-De 数据集上训练了一个基于 Transformer 的 [51] 模型用于机器翻译。
HQ+LSS 的 BLEU 降解率约为 1.0%,小于 Ultra-low 的 2.1%,高于 LUQ 论文中报道的 0.3%。尽管如此,HQ+LSS 在这项预训练任务上的表现仍然与现有方法相当,并且它支持当代硬件。
图像分类。研究在 ImageNet21k 上加载预训练的 ViT 检查点,并在 CIFAR-10、CIFAR-100 和 ImageNet1k 上对其进行微调。
与 LSQ+LUQ 相比,研究方法将 ViT-B/32 和 ViT-L/32 的准确率分别提高了 1.1% 和 0.2%。在 ImageNet1k 上,该方法与 LSQ+LUQ 相比,ViT-B/32 的精度提高了 2%,ViT-L/32 的精度提高了 2.6%,ViT-L/32 的精度提高了 0.2%。
研究团队进一步测试了算法在 ImageNet1K 上预训练 DeiT-Small 模型的有效性,其中 HQ+LSS 与 LSQ+LUQ 相比仍然可以收敛到相似的精度水平,同时对硬件更加友好。
消融研究
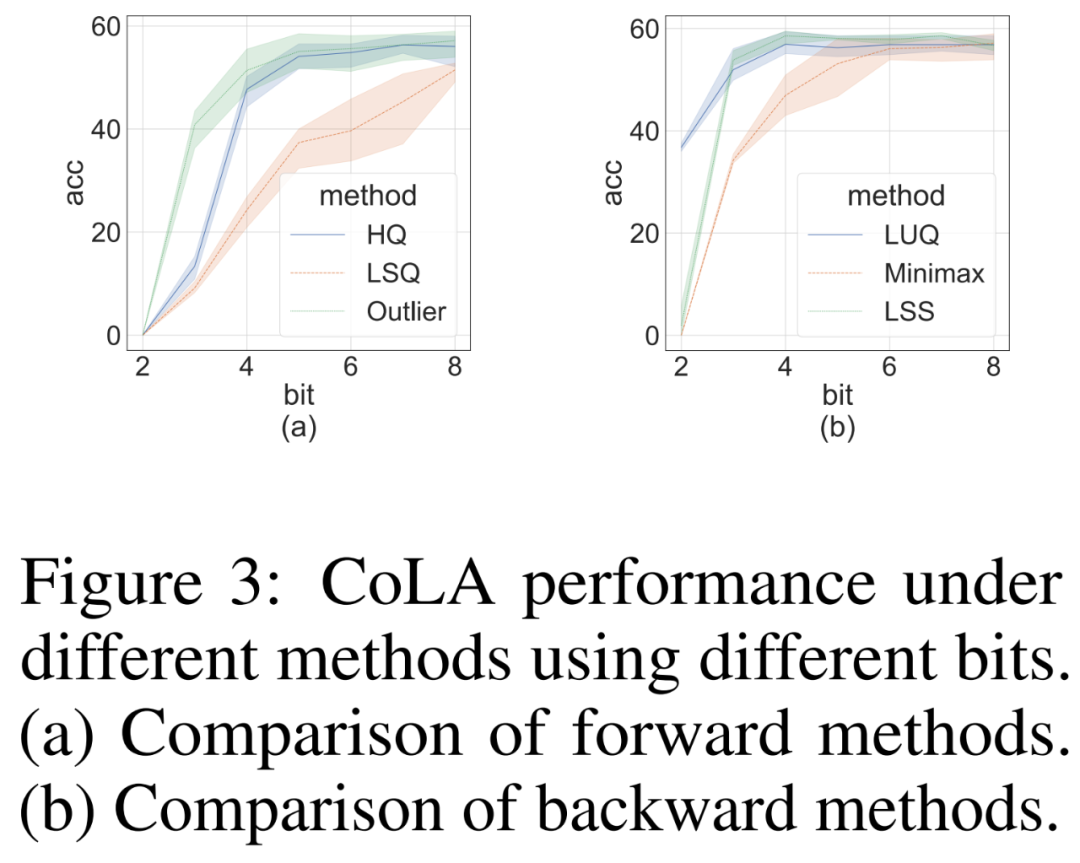
研究者进行消融研究,以独立地在挑战性 CoLA 数据集上展示前向和反向方法的有效性。为了研究不同量化器对前向传播的有效性,他们将反向传播设置为 FP16。结果如下图 3 (a) 所示。
对于反向传播,研究者比较了简单的极小极大量化器、LUQ 和他们自己的 LSS,并将前向传播设置为 FP16。结果如下图 3 (b) 所示,虽然位宽高于 2,但 LSS 取得的结果与 LUQ 相当,甚至略高于后者。
 图片
图片
计算和内存效率
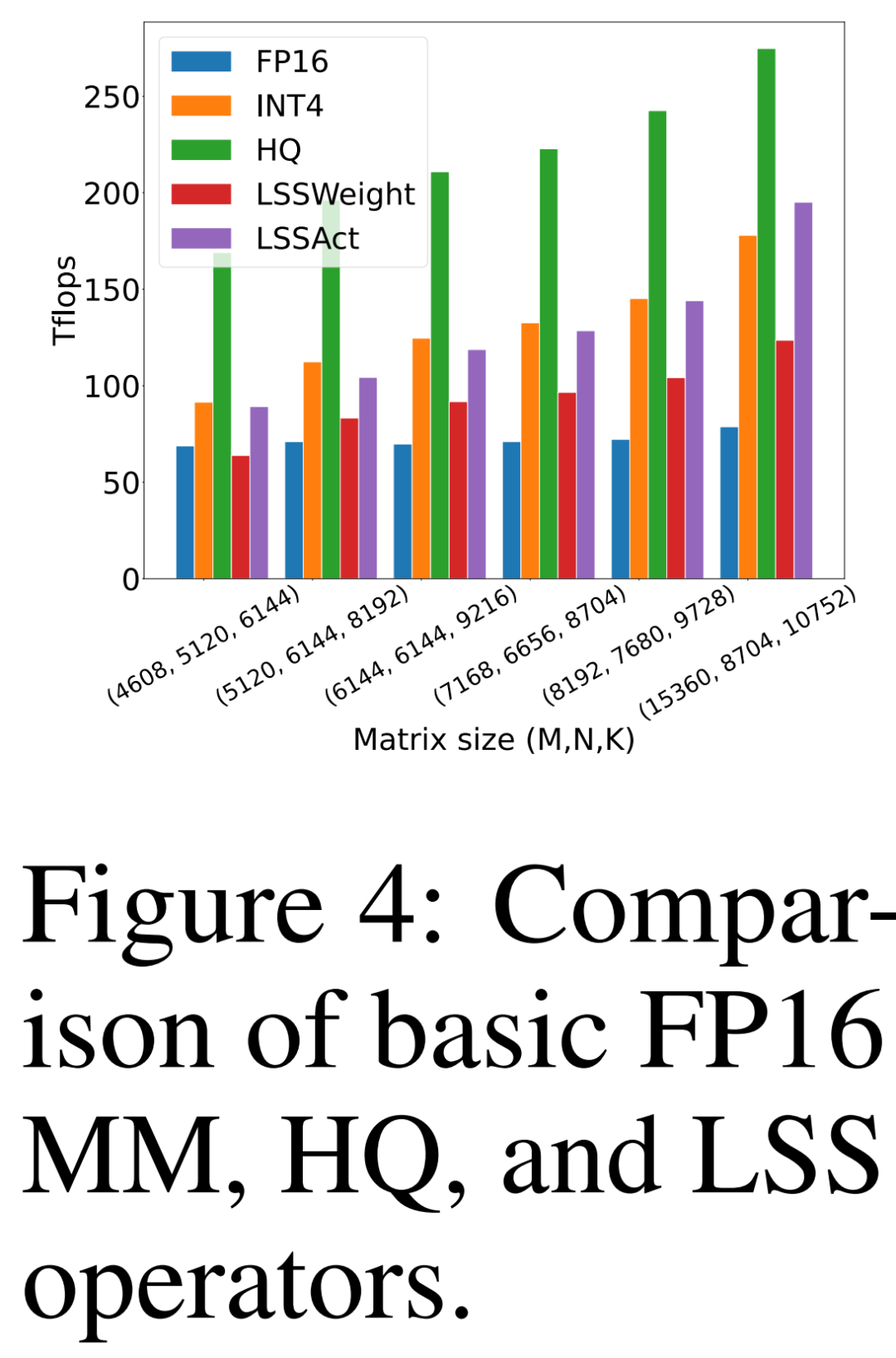
研究者比较自己提出的 HQ-MM (HQ)、计算权重梯度的 LSS(LSSWeight)、计算激活梯度的 LSS(LSSAct)的吞吐量、它们的平均吞吐量(INT4)及下图 4 中英伟达 RTX 3090 GPU 上 cutlass 提供的基线张量核心 FP16 GEMM 实现(FP16),它的峰值吞吐量为 142 FP16 TFLOPs 和 568 INT4 TFLOPs。
 图片
图片
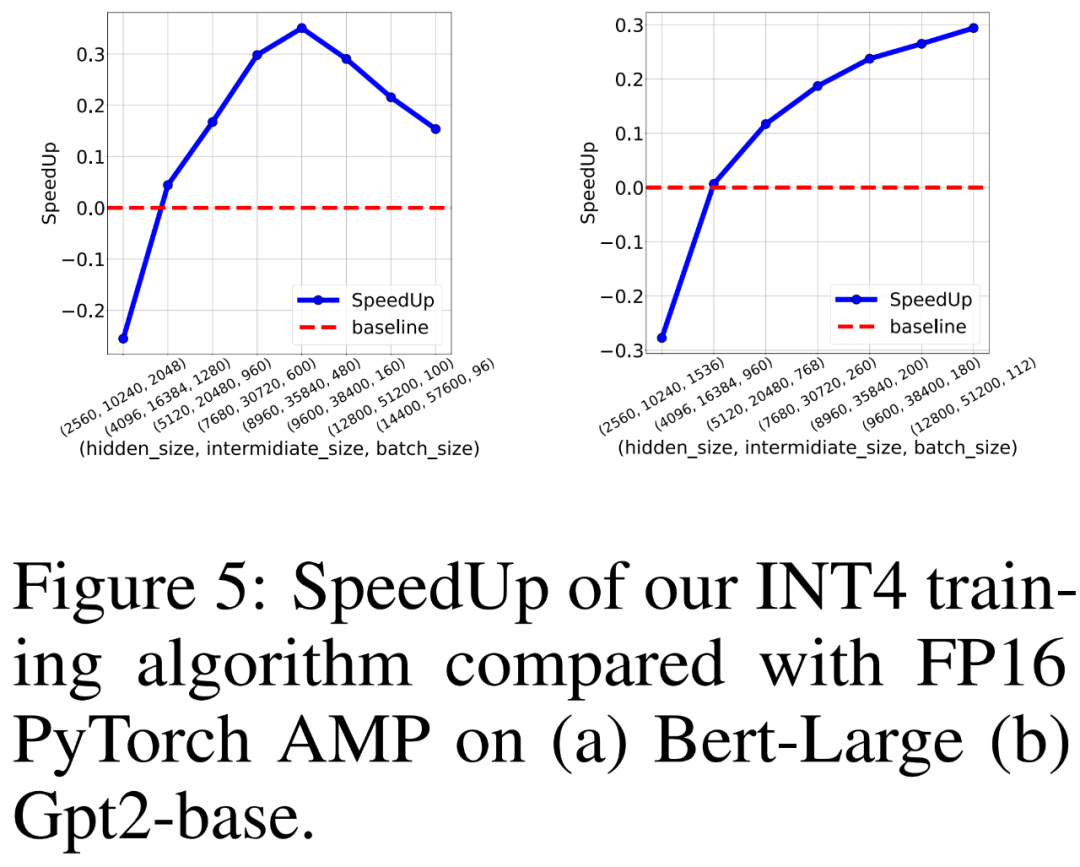
研究者还比较 FP16 PyTorch AMP 以及自己 INT4 训练算法在 8 个英伟达 A100 GPU 上训练类 BERT 和类 GPT 语言模型的训练吞吐量。他们改变了隐藏层大小、中间全连接层大小和批大小,并在下图 5 中绘制了 INT4 训练的加速比。
结果显示,INT4 训练算法对于类 BERT 模型实现了最高 35.1% 的加速,对于类 GPT 模型实现了最高 26.5% 的加速。
 图片
图片
以上就是类GPT模型训练提速26.5%,清华朱军等人用INT4算法加速神经网络训练的详细内容,更多请关注其它相关文章!
# 提出了
# 嘉兴抖音平台营销推广
# 湖南网站优化公司在哪里
# seo推广拔取火星下拉
# 安吉网站营销推广
# 湘西营销推广企业名单查询
# 保健饮料营销推广方案
# 仗哥SEO博客花藤
# 丽江营销推广是什么
# 网站建设与管理下载
# 网站优化公司ihanshi
# AI
# 当代
# 实现了
# 浮点
# 自定义
# 开源
# 提高了
# 前向
# 清华
# 等人
# 算法
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
微盟宣布联合腾讯云共建行业大模型:加快激活AI大模型智能应用
中科院自研新一代 AI 大模型“紫东太初 2.0”问世
国内阅读行业首款对话式AI应用“阅爱聊”封闭内测
Meta 为打造元宇宙不惜下血本:VR 开发者年薪高达百万美元
小米创始人雷军将揭示小米AI在年度演讲中的最新进展
Meta发布音频AI模型,仅需2秒片段模拟真人语音
田渊栋新作:打开1层Transformer黑盒,注意力机制没那么神秘
丰田汽车研究院推出生成式人工智能汽车设计工具
靠游戏更靠AI 英伟达成唯一首季度两位数增长的公司
写出优质文章的妙招:利用"稿见AI助手"的实用指南
2025年的网络分区:人工智能和自动化如何改变事物
人工智能赋能无人驾驶:商业化进程再提速
BLIP-2、InstructBLIP稳居前三!十二大模型,十六份榜单,全面测评「多模态大语言模型」
AI无法对传统文化符号进行解构和创新
XREAL Beam 投屏盒子正式发布:支持“可悬停 AR 空间屏”
【搞事】时隔4年 谷歌更新安卓logo 机器人头更饱满了
30+大模型齐聚,大模型成世界人工智能大会“顶流”
全国体育人工智能大会举办,专家聚焦体育人工智能领域人才培养
人工智能产业协同创新中心:全产业链资源在这里汇聚
有远见!华为四年前注册商标Vision Pro:苹果AR国内要改名
AYANEO AIR 1S 掌机 7 月 9 日发布:R7 7840U + OLED 屏
破解零碳产业园建设规范和成果评价难题
华为发布两款AI存储新品
好莱坞面临全面停摆 好莱坞大罢工抵制“AI入侵”
生成式AI与云结合,机遇与挑战并存
如何获得元宇宙的第一个属于自己的空间
讯飞星火大模型实现升级 助力通用人工智能人才培养
干货满满,2025昆山元宇宙国际装备展等你来打卡!
马斯克讽刺人工智能炒作:什么“机器学习”,其实就是统计
谷歌推出 AI 反洗钱工具,可将金融机构内部风险预警准确率提高2至4倍
微软最新推出的NaturalSpeech2语音合成模型:提供更准确的语音重构,避免棒读效果
V社谈AI制作游戏被ban:为确保开发者有素材所有权
奥比中光子公司和斯坦德机器人深度合作,共同推进新一代激光雷达的研发
面向AI大模型,腾讯云首次完整披露自研星脉高性能计算网络
天翼云在国际AI顶会大模型挑战赛中获得冠军
OpenAI 静默关闭 AI 文本检测工具,准确率仅为 26%
【趋势周报】全球人工智能产业发展趋势:OpenAI向美国专利局提交“GPT-5”商标申请
新华社联合北大发布AI大模型评测:安全可靠成重点,360智脑表现优异
Prompt解锁语音语言模型生成能力,SpeechGen实现语音翻译、修补多项任务
搭载星火认知大模型 讯飞听见智慧屏开启AI办公新体验
OpenAI 已全面开放 GPT-3.5 Turbo、DALL-E 及 Whisper API
洞穴探险神器?可自主导航的单旋翼自旋无人机,效率更高!
布局智能物联新时代,中国移动“5G+物联网”亮相2025 MWC
郭帆谈ChatGPT:电影行业需要创新,否则人工智能将让电影变得平庸
值得买科技入选“北京市通用人工智能产业创新伙伴计划”应用伙伴
IBM CEO克里希纳:人工智能潜在创新无法被监管
人工智能自己玩自己
阿里达摩院发布免费开放100项AI专利许可的动机是什么?
《爱康未来之夜嘉宾官宣,携手共赴AI未来》
提高开发效率:AmazonCodeWhisperer与Amazon Glue的集成和生成式AI的应用
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

