


400 128 6709

行业新闻
 发布时间:2023-11-20
发布时间:2023-11-20 点击次数:
点击次数: 最近一年来,以 Stable Diffusion 为代表的一系列文生图扩散模型彻底改变了视觉创作领域。数不清的用户通过扩散模型产生的图片提升生产力。但是,扩散模型的生成速度是一个老生常谈的问题。因为降噪模型依赖于多步降噪来逐渐将初始的高斯噪音变为图片,因此需要对网络多次计算,导致生成速度很慢。这导致大规模的文生图扩散模型对一些注重实时性,互动性的 应用非常不友好。随着一系列技术的提出,从扩散模型中采样所需的步数已经从最初的几百步,到几十步,甚至只需要 4-8 步。
应用非常不友好。随着一系列技术的提出,从扩散模型中采样所需的步数已经从最初的几百步,到几十步,甚至只需要 4-8 步。
最近,来自谷歌的研究团队提出了 UFOGen 模型,一种能极速采样的扩散模型变种。通过论文提出的方法对 Stable Diffusion 进行微调,UFOGen 只需要一步就能生成高质量的图片。与此同时,Stable Diffusion 的下游应用,比如图生图,ControlNet 等能力也能得到保留。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

请点击以下链接查看论文:https://arxiv.org/abs/2311.09257
从下图可以看到,UFOGen 只需一步即可生成高质量,多样的图片。

提升扩散模型的生成速度并不是一个新的研究方向。之前关于这方面的研究主要集中在两个方向。一个方向是设计更高效的数值计算方法,以求能达到利用更少的离散步数求解扩散模型的采样 ODE 的目的。比如清华的朱军团队提出的 DPM 系列数值求解器,被验证在 Stable Diffusion 上非常有效,能显著地把求解步数从 DDIM 默认的 50 步降到 20 步以内。另一个方向是利用知识蒸馏的方法,将模型的基于 ODE 的采样路径压缩到更小的步数。这个方向的例子是 CVPR2025 最佳论文候选之一的 Guided distillation,以及最近大火的 Latent Consistency Model (LCM)。尤其是 LCM,通过对一致性目标进行蒸馏,能够将采样步数降到只需 4 步,由此催生了不少实时生成的应用。
然而,谷歌的研究团队在 UFOGen 模型中并没有跟随以上大方向,而是另辟蹊径,利用了一年多前提出的扩散模型和 GAN 的混合模型思路。他们认为前面提到的基于 ODE 的采样和蒸馏有其根本的局限性,很难将采样步数压缩到极限。因此想实现一步生成的目标,需要打开新的思路。
混合模型是指结合了扩散模型和生成对抗网络(GAN)的方法。这个方法最早由英伟达的研究团队在ICLR 2025上提出,被称为DDGAN(《用去噪扩散GAN解决生成学习三难题》)。DDGAN的灵感来自于普通扩散模型对降噪分布进行高斯假设的缺陷。简单来说,扩散模型假设降噪分布(给定一个带噪音的样本,生成一个噪音更少的样本的条件分布)是一个简单的高斯分布。然而,随机微分方程理论证明,这样的假设只在降噪步长趋近于0时成立。因此,扩散模型需要大量重复的降噪步骤来保证较小的降噪步长,导致生成速度较慢
DDGAN 提出抛弃降噪分布的高斯假设,而是用一个带条件的 GAN 来模拟这个降噪分布。因为 GAN 具有极强的表示能力,能模拟复杂的分布,所以可以取较大的降噪步长来达到减少步数的目的。然而,DDGAN 将扩散模型稳定的重构训练目标变成了 GAN 的训练目标,很容易造成训练不稳定,从而难以延伸到更复杂的任务。在 NeurIPS 2025 上,和创造 UGOGen 的同样的谷歌研究团队提出了 SIDDM(论文标题 Semi-Implicit Denoising Diffusion Models),将重构目标函数重新引入了 DDGAN 的训练目标,使训练的稳定性和生成质量都相比于 DDGAN 大幅提高。
SIDDM 作为 UFOGen 的前身,只需要 4 步就能在 CIFAR-10, ImageNet 等研究数据集上生成高质量的图片。但是 SIDDM 有两个问题需要解决:首先,它不能做到理想状况的一步生成;其次,将其扩展到更受关注的文生图领域并不简单。为此,谷歌的研究团队提出了 UFOGen,解决这两个问题。
具体来说,对于问题一,通过简单的数学分析,该团队发现通过改变生成器的参数化方式,以及改变重构损失函数计算的计算方式,理论上模型可以实现一步生成。对于问题二,该团队提出利用已有的 Stable Diffusion 模型进行初始化来让 UFOGen 模型更快更好的扩展到文生图任务上。值得注意的是,SIDDM 就已经提出让生成器和判别器都采用 UNet 架构,因此基于该设计,UFOGen 的生成器和判别器都是由 Stable Diffusion 模型初始化的。这样做可以最大限度地利用 Stable Diffusion 的内部信息,尤其是关于图片和文字的关系的信息。这样的信息很难通过对抗学习来获得。训练算法和图示见下。

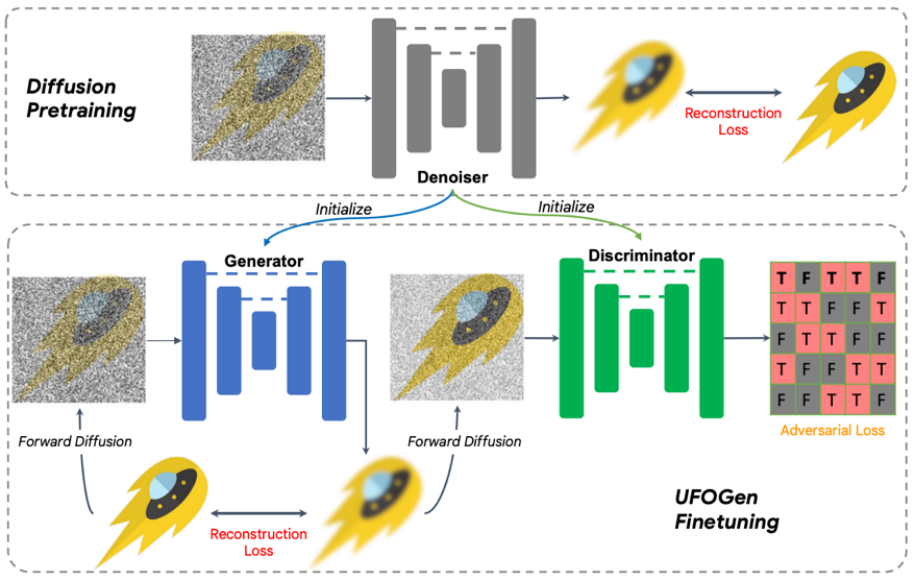
值得注意的是,在这之前也有一些利用 GAN 做文生图的工作,比如英伟达的 StyleGAN-T,Adobe 的 GigaGAN,都是将 StyleGAN 的基本架构扩展到更大的规模,从而也能一步文生图。UFOGen 的作者指出,比起之前基于 GAN 的工作,除了生成质量外,UFOGen 还有几点优势:
重写后的内容:1. 在文生图任务中,纯粹的生成对抗网络(GAN)训练非常不稳定。判别器不仅需要判断图像的纹理,还需要理解图像和文字之间的匹配程度,这是一项非常困难的任务,尤其是在训练的早期阶段。因此,之前的GAN模型,如GigaGAN,引入了大量的辅助损失来帮助训练,这使得训练和调参变得异常困难。然而,UFOGen通过引入重构损失,使GAN在这方面发挥了辅助作用,从而实现了非常稳定的训练
2. 直接从头开始训练 GAN 除了不稳定还异常昂贵,尤其是在文生图这样需要大量数据和训练步数的任务下。因为需要同时更新两组参数,GAN 的训练比扩散模型来说消耗的时间和内存都更大。UFOGen 的创新设计能从 Stable Diffusion 中初始化参数,大大节约了训练时间。通常收敛只需要几万步训练。
3. 文生图扩散模型的一大魅力在于能适用于其他任务,包括不需要微调的应用比如图生图,已经需要微调的应用比如可控生成。之前的 GAN 模型很难扩展到这些下游任务,因为微调 GAN 一直是个难题。相反,UFOGen 拥有扩散模型的框架,因此能更简单地应用到这些任务上。下图展示了 UFOGen 的图生图以及可控生成的例子,注意这些生成也只需要一步采样。

经过实验表明,UFOGen 只需要一步采样就能生成高质量、符合文字描述的图片。与近期提出的针对扩散模型的高速采样方法(如Instaflow和LCM)相比,UFOGen展现出了很强的竞争力。即使与需要50步采样的Stable Diffusion相比,UFOGen生成的样本在观感上也不逊色。以下是一些对比结果:

谷歌团队提出了一种名为UFOGen的强大模型,通过提升现有的扩散模型和GAN的混合模型来实现。这个模型是由Stable Diffusion微调而来的,并且在保证一步文生成图的能力的同时,还适用于不同的下游应用。作为早期实现超快速文本到图像合成的工作之一,UFOGen为高效率生成模型领域开辟了一条新的道路
以上就是实现高质量图像生成的新一步:谷歌UFOGen极速采样方法的详细内容,更多请关注其它相关文章!
# 扩展到
# 地产营销推广创意文案
# 宁波抖音seo招商平台
# 企业seo site
# 呈贡区关键词seo排名优化
# 汉语国际推广网站策划与建设DW
# 屏南县百度网站推广
# 单位网站建设方案
# 节点营销的推广策略
# 杭州湾做网站推广怎么样
# 鄱阳网站优化平台
# 高斯
# 模型
# 很难
# 是一个
# 提出了
# 重构
# 只需要
# 降噪
# 极速
# 高质量
# controlnet
# stable diffusion
# ai
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
好莱坞面临全面停摆 好莱坞大罢工抵制“AI入侵”
GPT-4成功战胜AI-Guardian审核系统:谷歌研究团队的人工智能抵抗人工智能
构建AI绘画网站的方法:使用API接口和调用步骤
提高开发效率:AmazonCodeWhisperer与Amazon Glue的集成和生成式AI的应用
AI大模型时代,数据存储新基座助推教科研数智化跃迁
工信部信通院发布《2025大模型和AIGC产业图谱》 360智脑覆盖全产业链
特斯拉人形机器人将于 7 月亮相上海 2025 世界人工智能大会
衡水市冀州中学机器人社团在世界机器人大赛中斩获佳绩
华为联合合作伙伴 共同发布昇腾AI大模型训推一体化解决方案
出门问问亮相2025世界人工智能大会,展示AI CoPilot解决方案
如何获得元宇宙的第一个属于自己的空间
比尔盖茨:AI确实存在风险,但可控
Midjourney 5.2震撼发布!原画生成3D场景,无限缩放无垠宇宙
杀入生成式AI的亚马逊云科技,能否再次生成未来?
Meta发布语音AI模型 Voicebox 助虚拟助手与NPC对话
首家承认ChatGPT影响其收入的公司Chegg选择拥抱AI ,裁减4%员工
如何用AI重塑你的工作流(一)
人工智能赋能无人驾驶:商业化进程再提速
可按用户语气自动回复消息,Zoom 推出基于生成式 AI 的新功能
第四范式「式说」大模型入选《2025年通用人工智能创新应用案例集》
苹果推出全新沉浸式 AR 体验应用“Deep Field”
北京市通用人工智能产业创新伙伴计划名单公布,京东科技入选“算力伙伴”
Meta 为打造元宇宙不惜下血本:VR 开发者年薪高达百万美元
2025“春晖杯”人工智能专场对接活动举办
阿里云AI绘画创作大模型通义万相发布 已开启定向邀测
美踏控股推出创新人工智能大数据模型“心乐舞河”:虚拟人音舞社交的新体验
世界周刊丨AI“棱镜”?
前特斯拉总监、OpenAI大牛Karpathy:我被自动驾驶分了心,AI智能体才是未来!
外科医生的智能助手,“机器人手术”得到补充商业医保覆盖
智能机器人与话剧的完美结合:宇树四足机器人B1助力《骆驼祥子》重现经典
RoboNeo安装教程
中国气象局预测:到 2030 年,中国人工智能气象应用将达到国际领先水平
【澎湃原动力】人工智能产业协同创新中心:全产业链资源在这里汇聚
专家解读国家网信办深度合成服务算法备案信息公告:不等于百度、阿里、腾讯等生成式AI产品获批
AI+游戏首度大范围公布实际应用成果,AI全面来临还有多远?
科技数码圈的新物种 乐天派桌面机器人 AI +安卓+机器人 首发价1799元
昇腾AI & 讯飞星火:深度联手,共话国产大模型“大未来”
6月14日《星空下的对话》 张朝阳陆川将畅聊人生、电影、心理学与AI
如何用Transformer BEV克服自动驾驶的极端情况?
微软向美国政府提供GPT大模型,如何保证安全性?
读创正式上线“读创AI聊”功能
百亿量化私募:量化投资进入“精耕细作”时代 AI带来行业新变革
无人机协助盐城交通执法的协同训练
清华系面壁智能开源中文多模态大模型VisCPM :支持对话文图双向生成,吟诗作画能力惊艳
时间、空间可控的视频生成走进现实,阿里大模型新作VideoComposer火了
谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型
Xreal AR 眼镜用投屏盒子 Beam 发布:分体式设计,到手 699 元
英伟达H100霸榜权威AI性能测试 11分钟搞定基于GPT-3的大模型训练
大模型的“黄金搭档”来了!腾讯云正式发布AI原生向量数据库,提供10亿级向量检索能力
消息称苹果 iPhone 15 系列健康应用将深度融合 AI 技术
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

