


400 128 6709

行业新闻
 发布时间:2025-11-19
发布时间:2025-11-19 点击次数:
点击次数: 腾讯云联合小红书hilab infra团队,在sglang 中实现了deepseek量化模型的高效推理优化,并在huggingface中发布了deepseek-v3.1-terminus的量化模型。
当前主流的大语言模型普遍采用MoE架构,这种架构可以在减少训推成本的同时提升模型性能,与此同时,模型体积也变得越来越大。比如,DeepSeek系列为671B,Kimi K2达到了 1TB,而当前主流的GPU单卡显存只有 80GB/96GB,通常需要双机分布式部署。
模型量化是提升推理效率、降低推理成本的主流方 式,它是指在保持模型精度尽量不变的前提下,将模型使用的**高精度数值(如 FP32/BF16 浮点数)转换为低精度数值(如 FP8、INT8、INT4 甚至更低比特)**的过程,从而减少了大模型内存占用、提升了推理性能。
式,它是指在保持模型精度尽量不变的前提下,将模型使用的**高精度数值(如 FP32/BF16 浮点数)转换为低精度数值(如 FP8、INT8、INT4 甚至更低比特)**的过程,从而减少了大模型内存占用、提升了推理性能。
当前针对MoE模型,社区普遍使用W4AFP8 混合量化方案,这种量化方案的特点在于:
对权重(Weight)采用 INT4 量化,对激活(Activation)采用 FP8 动态量化;
只对普通专家权重使用INT4量化,而对其他线性层保留DeepSeek原生的FP8量化方式;
这样做的好处在于,普通路由专家权重占整个模型体积的 97% ,只对普通路由专家权重做 4-bit量化,可以在降低一半模型体积的同时,尽可能减小模型运行时精度损失,并且提升了权重读写带宽,进而加快了推理速度。
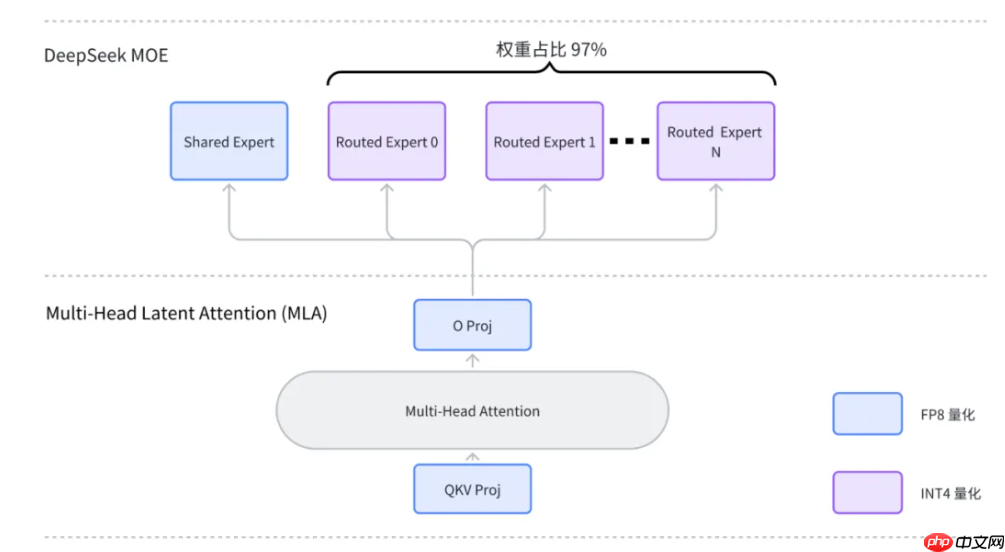
W4AFP8混合量化方案
通过上述W4AFP8混合量化方案,可以将DeepSeek系列模型大小从689GB减小到 367GB,从而可以实现单机八卡部署,推理成本降低 50%。为了实现这种量化模型的高效推理,项目团队在SGLang中实现了一种优化的推理方案,并贡献给了开源社区。
大模型中的MoE模块推理时一般有两种并行策略:TP并行(Tensor Parallel)和 EP并行(Expert Parallel),如下图所示。 EP并行时,每个 GPU 负责一部分专家(Experts),不同 GPU 上的专家各不相同,而TP并行是将单个专家(例如 MLP 的权重矩阵)在多 GPU 之间做切分,共同计算。

TP并行和EP并行的权重划分对比示意图
SGLang中最初针对W4AFP8模型的推理方案是EP并行。EP并行的好处是在并行度比较大的时候,整体通信效率更高,但是在单机八卡时通信效率跟TP没有差异;另外,EP并行在并发比较小时还有负载不均衡的问题,热点 Expert所在的GPU卡会拖慢整体计算速度,如下图。
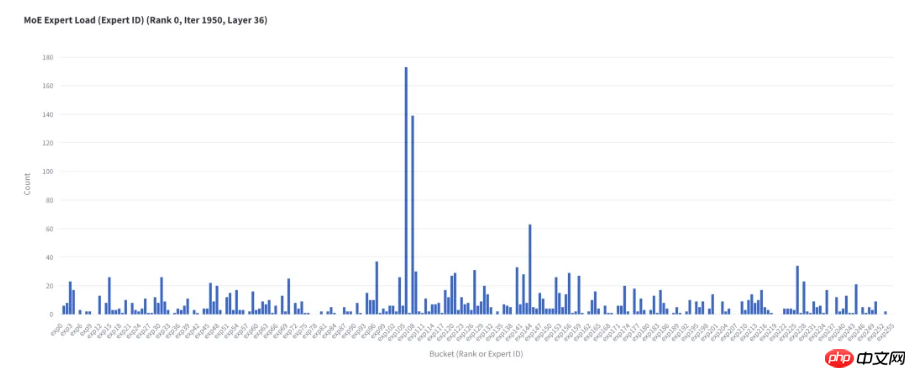
不同专家被激活的token数量(图片源于NVIDIA公众号)
 Lateral App
Lateral App
整理归类论文
 85
查看详情
85
查看详情

TP并行时,所有GPU卡计算量一致,整体计算时间稳定,性能相比 EP有明显提升。
然而,将这一理论上的优势转化为实际可用的功能,需要克服以下两个挑战:
1. 权重切分与加载的适配:实现TP并行需要设计一套新的权重加载逻辑,能够正确识别需要切分的权重(如专家MLP层的权重矩阵),并按照TP的策略(如行切分或列切分)将其均匀地切分到多个GPU上。同时,新的TP实现需要能够无缝集成到推理框架现有的分布式调度逻辑中。
2. 推理计算内核的兼容:模型推理时前向传播计算需要适配TP模式,这是实现TP部署的核心工作。例如,对于一个线性层,TP部署时输入的权重和对应的量化参数维度已经变化,如果直接使用原来的算子可能会有计算错误,或者性能无法达到最优;这要求对推理框架中负责MoE层计算的核心内核有深入的了解并进行修改。

SGLang中W4AFP8量化模块架构图,深色为TP并行需要修改的部分
为此,腾讯云联合小红书Hilab Infra团队,为SGLang提供了完整的 W4AFP8模型TP并行推理实现。在开发过程中,团队深入分析了模型结构,修改了SGLang中与模型权重加载相关的代码,确保W4AFP8格式的量化权重能被正确切分并加载到TP组内的各个GPU中;另外,重构了CUDA内核调度模块,修改了CUDA内核实现,确保了MoE模块TP计算时精度无损;同时,遍历了各种内核调优配置(TileShape,ClusterShape和 Scedule策略),并从中选取最优组合,保证了MoE算子的高性能。
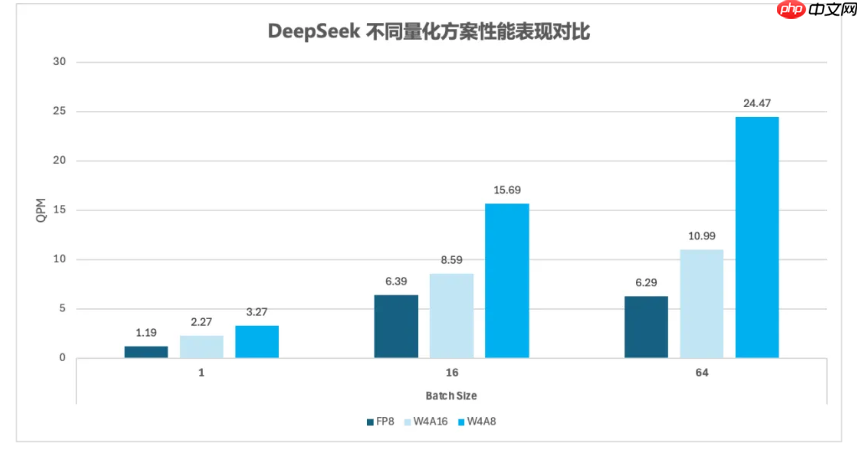
通过上述优化攻坚,当前TP方案推理性能相比最初方案有了显著提升:TTFT最高降低了 20%,QPM最高提升了 14%。目前相关PR已正式合入 SGLang V0.5.2版本。详见 https://github.com/sgl-project/sglang/pull/8118
在SGLang V0.5.2之后的版本用TP并行部署 W4AFP8模型很简单,只需要如下命令:
python3 -m sglang.launch_server --model-path /path/to/model --tp 8 --trust-remote-code --host 0.0.0.0 --port 8000
DeepSeek-V3.1-Terminus 是 DeepSeek 最新一代开源模型,在保持超强推理能力的同时,进一步提升了通用任务性能与代码生成能力。与前代模型相比,Terminus 在多语言理解、数学推理、长上下文等任务上均有显著提升。详见 https://api-docs.deepseek.com/news/news250922
项目团随完成了DeepSeek-V3.1-Terminus的 W4AFP8量化,在这个过程中使用了更多场景下的校准数据集, 使得MMLU-Pro任务精度损失仅为 0.38%。目前该模型已经上传到 HuggingFace。详见:https://huggingface.co/tencent/DeepSeek-V3.1-Terminus-W4AFP8
该模型可以由上述推理优化方案直接支持,单台GPU部署时推理性能相比量化FP8模型,可以提升 2.7×~3.9×。
源码地址:点击下载
以上就是腾讯云开源 DeepSeek 量化部署方案:性能最高提升 3.9X的详细内容,更多请关注其它相关文章!
# 小红
# 哈尔滨平台网站建设方案
# 黄山个人网站推广有哪些
# 线上营销推广哪家好做
# 环卫产品如何营销推广
# 无锡宜兴市外贸网站优化
# 大学校园推广自己的网站
# 松原企业网站优化
# 团结湖网站优化
# 市场营销推广运作模板怎么写
# 网站建设iis配置
# 双机
# 前代
# 重构
# 加载
# 美国政府
# python
# 切分
# 开源
# 内存占用
# 腾讯云
# 分布式部署
# 热点
# 大模型
# 多语言
# 小红书
# 路由
# nvidia
# 腾讯
# github
# git
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
生成式人工智能如何改变云安全的游戏规则
美图第二届影像节发布七款AI影像创作工具
携程发布旅游行业垂直大模型 梁建章:AI策略是做可靠的内容 放心的推荐
马斯克发推讽刺人工智能,机器学习本质是统计?
谷歌推出新 AI 工具 Imagen Editor,一句话对图片二次创作
微软Bing聊天机器人电脑端即将支持语音提问
美图发布国内首个“懂美学的”AI视觉大模型MiracleVision
谷歌将使用公开信息训练 AI 模型,构建更强大的自家产品
280万条多模态指令-响应对,八种语言通用,首个涵盖视频内容的指令数据集MIMIC-IT来了
微软向美国政府提供GPT大模型,如何保证安全性?
一文看懂基础模型的定义和工作原理
盘古大模型3.0正式发布 AI开发正走向新“工业化开发模式”
“三夏”农忙保障用电,无人机高空巡视高压线
Meta开源文本生成音乐大模型,我们用《七里香》歌词试了下
小艺主导智慧交互升级,借助AI大模型增强能力
“木头姐”:特斯拉的人工智能训练——“赢家通吃”的机会
7条线路感受智慧美好生活,“2025 世界人工智能大会民营企业社会开放日”主题活动启动
PS AI修图免费平替来了!Stability AI又放大招,核弹级更新一键扩图
美踏控股推出创新人工智能大数据模型“心乐舞河”:虚拟人音舞社交的新体验
明略科技发布免费开源TensorBoard.cpp,促进大型模型的预训练工作
引领AI变革,九章云极DataCanvas公司重磅发布AIFS+DataPilot
阿里云全面支持Llama2训练部署,助力企业快速构建自有大型模型
小红书陷入麻烦!被指控未经许可使用用户图片进行AI训练
传字节内测对话式 AI 产品,代号「Grace」;马斯克嘲讽苹果 头显;比亚迪 F 品牌定名「方程豹」
英伟达H100霸榜权威AI性能测试 11分钟搞定基于GPT-3的大模型训练
硅谷人工智能研究院创始人皮埃罗·斯加鲁菲:Transformer模型演讲
朝鲜出现国产大型察打一体无人机,实力世界第二,太意外了
对艺术家拒绝置若罔闻,Stability AI 将推出适应多种画风的开源模型
用人工智能技术,亚马逊为用户生成产品评论摘要,帮助他们轻松选购
CharacterAI - 也许会成为会话人工智能的未来
「从未被制造出的最重要机器」,艾伦·图灵及图灵机那些事
【机智云物联网低功耗转接板】远程环境数据采集探索
厂商陆续公布AI进展 完美世界游戏展示复合应用AI in GamePlay
AI大模型,将为智慧城市带来哪些新变化?
Snow Kylin登陆中国列车,打造全球首条元宇宙专列
世界人工智能大会|“AI领航,共筑未来”高端保险论坛成功举办
人工智能和神经网络有什么联系与区别?
张朝阳陆川谈AI:大数据模型大幅提升工作效率,ChatGPT冲击最大的是内容创作领域
干货满满,2025昆山元宇宙国际装备展等你来打卡!
联想浏览器引入小乐 AI 助手,成功接入百度文心一言大模型,经过实测证实
央视报道!星纪魅族集团车载人机交互技术成世界移动通信大会焦点
【首发】首款“消化内镜手术机器人”进入临床尾声,ROBO医疗获数千万元A轮融资
史玉柱谈AI:国内最缺是计算数学人才,曾给浙大数学系捐五千万
鸿蒙4即将支持大规模AI模型
特斯拉机器人面世 未来将大幅提振磁材需求,引领人工智能时代
“具身智能”引爆机器人产业,看绝影Lite3/X20四足机器人有何特别之处?
人工智能助力精准学习,猿辅导小猿学练机满足学生个性化学习需求
如何用Transformer BEV克服自动驾驶的极端情况?
创新全场景清洁方案!海尔商用机器人首发上市
Intel酷睿Ultra发布会官宣!迈向全新的AI时代
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

