


400 128 6709

行业新闻
 发布时间:2025-04-28
发布时间:2025-04-28 点击次数:
点击次数: 具身智能技术的突破与应用是通向通用人工智能(agi)的必经之路,全球科技公司正加速布局,如特斯拉的optimus、agility的digit、波士顿动力的atlas及figure ai等。2025年蛇年春晚的机器人“扭秧歌”表演也成为了人们茶余饭后的谈资。随着大模型技术的进步,具身智能也在快速发展。
然而,具身智能仍面临诸多挑战,其中核心挑战在于具身操作的泛化能力,即如何在有限的具身数据下,使机器人适应复杂场景并实现技能的高效迁移。
京东探索研究院李律松、李东江博士团队发起了该项目,并联合地瓜机器人秦玉森团队、中科大徐童团队、深圳大学郑琪团队、松灵机器人及睿尔曼 智能吴波团队共同推进,获得了清华RDT团队在基础方法上的技术支持。
智能吴波团队共同推进,获得了清华RDT团队在基础方法上的技术支持。
团队提出了首个基于三轮数据驱动的原子技能库构建框架,突破了传统端到端具身操作的数据瓶颈。该方法能够动态自定义和更新原子技能,并结合数据收集与VLA少样本学习,构建高效技能库。
实验结果表明,该方案在数据效率和泛化能力方面表现卓越,是业内首个基于数据驱动的具身大模型原子技能库构建框架,也是首个面向具身产业应用的数据采集新范式,形成了数据标准,解决了当前具身智能数据缺乏的问题,尤其是高校与产业之间数据和范式的流动,推动了具身大模型的研究与落地。
在生成式AI时代,具身智能迎来了重要突破。通过跨模态融合,将文本、图像、语音等数据映射到统一的语义向量空间,为具身智能技术的发展提供了新契机。VLA(视觉-语言-动作)模型在数据可用性与多模态技术的推动下不断取得进展。
然而,现实环境的复杂性使得具身操作模型在泛化性上仍面临挑战。端到端训练依赖海量数据,导致“数据爆炸”问题,限制了VLA的发展。将任务分解为可重用的原子技能可以降低数据需求,但现有方法受限于固定技能集,无法动态更新。
为解决这一问题,团队提出了基于三轮数据驱动的原子技能库构建方法,可在*或真实环境的模型训练中减少数据需求。
如图所示,VLP(视觉-语言-规划)模型将任务分解为子任务,高级语义抽象模块将子任务定义为通用原子技能集,并通过数据收集与VLA微调构建技能库。随着三轮更新策略的动态扩展,技能库不断扩增,覆盖任务范围扩大。该方法将重点从端到端技能学习转向细颗粒度的原子技能构建,有效解决了数据爆炸问题,并提升了新任务的适应能力。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 基于三轮数据驱动的原子技能库构建与推理流程为什么需要VLP?VLP需要具有哪些能力? 从产业落地的角度看,具身操作是关键模块。目前,端到端VLA进行高频开环控制,即便中间动作失败,仍输出下一阶段控制信号。因此,VLA在高频控制机器人/机械臂时,强烈依赖VLP提供低频智能控制,以指导阶段性动作生成,并协调任务执行节奏。
基于三轮数据驱动的原子技能库构建与推理流程为什么需要VLP?VLP需要具有哪些能力? 从产业落地的角度看,具身操作是关键模块。目前,端到端VLA进行高频开环控制,即便中间动作失败,仍输出下一阶段控制信号。因此,VLA在高频控制机器人/机械臂时,强烈依赖VLP提供低频智能控制,以指导阶段性动作生成,并协调任务执行节奏。
为统一训练与推理的任务分解,本文构建了集成视觉感知、语言理解和空间智能的VLP Agent。如图所示,VLP Agent接收任务指令文本与当前观察图像,并利用Prismatic生成场景描述。考虑到3D世界的复杂性,我们设计了一种空间智能感知策略:
首先,Dino-X检测任务相关物体并输出边界框;然后,SAM-2提供精细分割掩码,并基于规则判断物体间的空间关系;最终,这些视觉与空间信息与任务指令一同输入GPT-4,生成完整执行计划并指定下一个子任务。VLP Agent通过该方法在原子技能库构建中有效分解端到端任务,并在推理过程中提供低频控制信号,规划并指导高频原子技能的执行。
 基于空间智能信息的VLP Agent具身思维链框架VLA存在的问题是什么?在框架中起什么作用? VLA技术从专用数据向通用数据演进,机器人轨迹数据已达1M episodes级别;模型参数规模从千亿级向端侧部署发展;性能上,VLA从单一场景泛化至多场景,提升技能迁移能力。
基于空间智能信息的VLP Agent具身思维链框架VLA存在的问题是什么?在框架中起什么作用? VLA技术从专用数据向通用数据演进,机器人轨迹数据已达1M episodes级别;模型参数规模从千亿级向端侧部署发展;性能上,VLA从单一场景泛化至多场景,提升技能迁移能力。
尽管端到端任务采集与训练有助于科研算法优化,但在通用机器人应用中,人为定义端到端任务易导致任务穷尽问题。在单任务下,物品位置泛化、背景干扰、场景变化仍是主要挑战,即便强大预训练模型仍需大量数据克服;多任务下,数据需求呈指数级增长,面临“数据爆炸”风险。
 第一团购
第一团购
第一团购软件是基于Web应用的B/S架构的团购网站建设解决方案的建站系统。它可以让用户高效、快速、低成本的构建个性化、专业化、强大功能的团购网站。从技术层面来看,本程序采用目前软件开发IT业界较为流行的ASP.NET和SQLSERVER2000数据库开发技术架构。从功能层面来看,前台首页每天显示一个服务或插产品的限时限最低成团人数的团购项目,具有邮件订阅,好友邀请,人人网、开心网、新浪微博、MSN
 0
查看详情
0
查看详情

提出的三轮数据驱动的原子技能库方法可结合SOTA VLA模型,通过高级语义抽象模块将复杂子任务映射为结构化原子技能,并结合数据收集与VLA少样本学习高效构建技能库。VLA可塑性衡量模型从多本体迁移至特定本体的能力,泛化性则评估其应对物体、场景、空间变化的表现。
以RDT-1B作品为例,我们基于6000条开源数据及2000条自有数据微调VLA模型。测试结果表明,模型在物品和场景泛化上表现优异,但在物品位置泛化方面存在一定局限,且训练步数对最终性能影响显著。为进一步优化,团队进行了两项实验包括位置泛化能力提升及训练步长优化测试。这类VLA模型性能测试对于原子技能库构建至关重要,测试结果不仅优化了Prompt设计,也进一步增强了高级语义抽象模块在子任务映射与技能定义中的精准性。为什么构建原子技能库?怎样构建? 具身操作技能学习数据源包括互联网、*引擎和真实机器人数据,三者获取成本递增,数据价值依次提升。在多任务多本体机器人技能学习中,OpenVLA和Pi0依托预训练VLM,再用真实轨迹数据进行模态对齐并训练技能,而RDT-1B直接基于百万级机器人真实轨迹数据预训练,可适配不同本体与任务。
无论模型架构如何,真实轨迹数据仍是关键。原子技能库的构建旨在降低数据采集成本,同时增强任务适配能力,提升具身操作的通用性,以满足产业应用需求。
基于数据驱动的原子技能库构建方法,结合端到端具身操作VLA与具身规划VLP,旨在构建系统化的技能库。VLP将TASK A, B, C, ..., N分解为Sub-task #1, #2, ..., #a+1。高级语义抽象模块基于SOTA VLA模型测试可调整任务粒度,进一步将子任务映射为通用原子技能定义1, 2, ..., b+1,并通过数据收集与VLA少样本学习,构建包含1', 2', ..., b+1'的原子技能库。
面对新任务TASK N+1,若所需技能已在库中,则可直接执行;若缺失,则触发高级语义抽象模块,基于现有技能库进行原子技能定义更新,仅需对缺失的原子技能收集额外数据与VLA微调。随着原子技能库动态扩增,其适应任务范围不断增加。
相比传统TASK级数据采集,提出的原子技能库所需要的数据采集量根据任务难度成指数级下降,同时提升技能适配能力。
实验及结果分析 验证问题在相同物体点位下采集轨迹数据,所提方法能否以更少数据达到端到端方法性能?在收集相同数量的轨迹数据下,所提方法能否优于端到端方法?面对新任务,所提方法是否能够在不依赖或者少依赖新数据的条件下仍然有效?所提方法是否适用于不同VLA模型,并保持有效性和效率?实验设置针对上述问题,我们设计了四个挑战性任务,并在RDT-1B和Octo基准模型上,以Agilex双臂机器人进行测试。实验采用端到端方法和所提方法分别采集数据,以对比两者在数据利用效率和任务泛化能力上的表现。具体实验设置如下:
拿起香蕉并放入盘子端到端方法:从4个香蕉点位和2个盘子点位采集24条轨迹。所提方法:保持数据分布一致,分解为12条抓取香蕉轨迹和6条放置香蕉轨迹。为匹配端到端数据量,进一步扩大采样范围,从8个香蕉点位采集24条抓取轨迹,3个盘子点位采集24条放置轨迹。拿起瓶子并向杯中倒水端到端方法:从3个瓶子点位和3个杯子点位采集27条轨迹。所提方法:分解为9条抓取瓶子轨迹和9条倒水轨迹,确保数据分布一致。进一步扩大采样范围,从9个瓶子点位采集27条抓取轨迹,9个杯子点位采集27条倒水轨迹。拿起笔并放入笔筒端到端方法:从4个笔点位和2个笔筒点位采集24条轨迹。所提方法:分解为12条抓取笔轨迹和6条放置笔轨迹,保持数据分布一致。进一步扩大采样范围,从8个笔点位采集24条抓取轨迹,3个笔筒点位采集24条放置轨迹。按指定顺序抓取积木(红、绿、蓝)端到端方法:采集10条轨迹,固定积木位置,按顺序抓取红色、绿色、蓝色积木。所提方法:为匹配端到端数据量,分别采集10条抓取红色、绿色、蓝色积木轨迹,共30条。 任务定义与可视化实验结果 前三个任务用于验证所提方法在数据效率和操作性能上的表现,第四个任务则评估其新任务适应能力。为确保公平性,每种实验设置均在Octo和RDT-1B上进行10次测试,对比端到端方法与所提方法(“Ours”和“Ours-plus”)。
任务定义与可视化实验结果 前三个任务用于验证所提方法在数据效率和操作性能上的表现,第四个任务则评估其新任务适应能力。为确保公平性,每种实验设置均在Octo和RDT-1B上进行10次测试,对比端到端方法与所提方法(“Ours”和“Ours-plus”)。
如表1所示,“End-To-End”:原始端到端VLA方法;“Ours”:保持数据分布一致,但数据量更小;“Ours-plus”:保持数据量一致,但采集更多点位;“ID”:任务点位在训练数据分布内;“OOD”:任务点位超出训练数据分布。在第四个任务中,设定红-绿-蓝顺序抓取积木为已知任务,并采集数据训练模型。针对其他颜色顺序的未知任务,直接调用已训练的技能进行测试,以评估方法的泛化能力(见表2)。结果分析如下:
Q1: 从表1可见,Octo和RDT-1B在使用所提方法后,成功率与端到端方法相当甚至更高。在拿起瓶子并向杯中倒水任务中,OOD测试成功率提升20%,表明该方法在相同点位分布下,减少数据需求同时提升性能。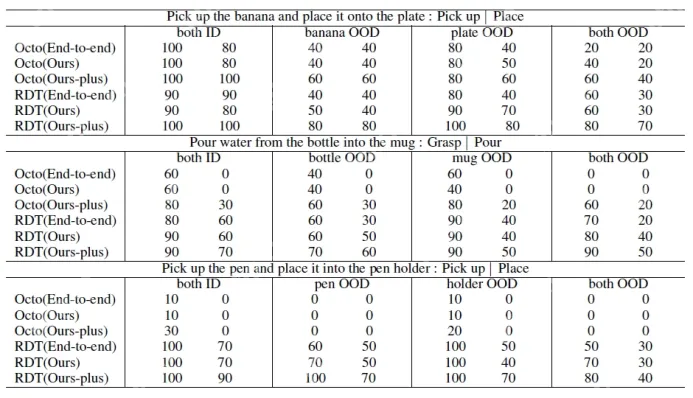 表1:与原始端到端方法实验结果对比Q2: 在相同数据量下,所提方法显著提升成功率。例如,在拿起香蕉并放入盘子任务中,OOD情况下成功率提高40%,归因于从更多点位采集数据,增强模型泛化能力。Q3: 从表2可见,端到端方法仅适用于已知任务,无法泛化新任务,而所提方法能通过已有技能组合成功执行不同的新任务
表1:与原始端到端方法实验结果对比Q2: 在相同数据量下,所提方法显著提升成功率。例如,在拿起香蕉并放入盘子任务中,OOD情况下成功率提高40%,归因于从更多点位采集数据,增强模型泛化能力。Q3: 从表2可见,端到端方法仅适用于已知任务,无法泛化新任务,而所提方法能通过已有技能组合成功执行不同的新任务 表2:与原始端到端方法方块抓取任务实验结果对比Q4: 表1和表2进一步验证,所提方法在多种VLA模型上均提升数据效率、操作性能和新任务适应能力,适用于不同模型的泛化与优化。 小结团队提出的一种基于三轮数据驱动的原子技能库构建框架,旨在解决传统端到端具身操作策略带来的“数据爆炸”问题,为具身智能产业应用提供创新解决方案。
表2:与原始端到端方法方块抓取任务实验结果对比Q4: 表1和表2进一步验证,所提方法在多种VLA模型上均提升数据效率、操作性能和新任务适应能力,适用于不同模型的泛化与优化。 小结团队提出的一种基于三轮数据驱动的原子技能库构建框架,旨在解决传统端到端具身操作策略带来的“数据爆炸”问题,为具身智能产业应用提供创新解决方案。
该框架具有广泛价值,可用于提升物流仓储、智能制造、医疗辅助等领域的自动化水平。例如,在医疗辅助和服务机器人领域,它能够增强自主交互能力,助力精准操作。
希望此项工作能够为行业提供重要启示,促进学术界与产业界的深度合作,加速具身智能技术的实际应用。我们诚挚邀请有兴趣的合作伙伴,与我们一起探索具身智能的未来。如果您对具身触觉模态、基于强化学习的运控与操作等领域感兴趣,欢迎与lidongjiang5@jd.com联系。
以上就是业内首个具身智能原子技能库架构的详细内容,更多请关注其它相关文章!
# 官网
# 医疗网站建设哪家靠谱
# 医院网站建设主要内容
# 卡游科技seo运营
# 无锡推广网站建设咨询热线
# 岚县附近网站推广电话
# 嘉兴专业网站建设推广
# 厦门提供网站优化服务
# 深圳市网站优化作用大吗
# 做seo网站优化有什么好处
# 十堰企业网站推广
# 数据采集
# 适用于
# 具身智能
# 拿起
# 新任务
# 团购
# 首个
# 团购网站建设解决方案
# 点位
# 端到
# fig
# prisma
# 为什么
# ai
# git
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
首届亚太网络法实务大会召开 九位大咖探讨元宇宙与人工智能发展
微软 GitHub Copilot 编程助手被投诉:换口吻改写公共代码来躲版权
前特斯拉总监、OpenAI大牛Karpathy:我被自动驾驶分了心,AI智能体才是未来!
一公司推出喷火机器狗,可喷出 9 米长火焰
VR健身应用《FitXR》将取消Quest 1端会员服务
AI+游戏首度大范围公布实际应用成果,AI全面来临还有多远?
2025VR&AR显示技术峰会视频解析: 歌尔光学展示最新一代VR/AR光学模组
值得买科技入选“北京市通用人工智能产业创新伙伴计划”应用伙伴
谷歌推出 AI 反洗钱工具,可将金融机构内部风险预警准确率提高2至4倍
AI大模型时代,数据存储新基座助推教科研数智化跃迁
字节、网易相继入局,AI之后大厂又找到下一个风口?
360发布AI数字人广场,可同孙悟空、爱因斯坦等古今中外角色对话
AMD称下半年AI显卡供应充足,不需要像NVIDIA那样加价抢购
刊·见 | 捕捉人工智能领域最新动态?收藏Applied Artificial Intelligence
浪潮KaiwuDB:“快人一步” - 打造更懂物联网的数据库
小岛秀夫不反对使用AI 但认为人类应该凌驾于AI
警惕!AI或致虚假信息泛滥
中科院自研新一代 AI 大模型“紫东太初 2.0”问世
无人机自主巡检为高海拔输电线路运维添“新彩”
WHEE上线时间介绍
尼康尼克尔 Z 180-600mm f/5.6-6.3 VR 镜头发布,12499 元
磐镭发布全新 GeForce RTX 4080 ARMOUR 显卡,售价为 9499 元
英媒:硅谷有些人太鼓吹AI,宣扬“学习无用”
微软宣布为 Azure AI 添加男性声线,增强文本转语音功能
生成式人工智能来了,如何保护未成年人? | 社会科学报
中国联通发布图文AI大模型,可实现以文生图、视频剪辑
基于预训练模型的金融事件分析及应用
拓普龙7188ML:轻便壁挂式工控机箱,为人工智能应用场景提供有力保障
为什么很多人对纽约《人工智能招聘法》感到生气?
PHP和OpenCV库:如何实现人脸识别
OpenAI首席执行官引用《道德经》 呼吁就AI安全问题合作
Meta 人工智能业务落后竞争对手,研究人员大量离职成重要原因
马斯克称人类是半机器人,记忆外包给了电脑
MetaGPT开源框架爆红 GitHub,达到1.1万星,模拟软件开发流程
人工智能在项目管理中的作用
苹果式 AI 哲学:不着一字,处处落子
抖音在Android平台获得VR|直播|软件著作权
生成式AI与云结合,机遇与挑战并存
Moka AI产品后观察:HR SaaS迈进AGI时代
央视报道车载人机交互技术!MWC上海魅族表现亮眼,现场热火朝天
13 个提高生产力的 AI 工具
AMD在ChinaJoy展示全新的锐龙AI笔记本,开创了人工智能领域的新时代!
生成式人工智能如何改变云安全的游戏规则
AI 模型 Stable Diffusion 升级:正常生成五指、图像更逼真
Meta 开源 AI 语言模型 MusicGen,可将文本和旋律转化为完整乐曲
如何用Transformer BEV克服自动驾驶的极端情况?
携程发布旅游行业垂直大模型 梁建章:AI策略是做可靠的内容 放心的推荐
有 ARM 和 X86 两个版本,香橙派游戏掌机细节曝光
“技术+实践+生态”三箭齐发,京东方抢占物联网高地
洞穴探险神器?可自主导航的单旋翼自旋无人机,效率更高!
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

