在 4 月 27 日召开 的中关村论坛通用人工智能平行论坛上,人大系初创公司智子引擎隆重发布全新的多模态大模型 Awaker 1.0,向 AGI 迈出至关重要的一步。相对于智子引擎前代的 ChatImg 序列模型,Awaker 1.0 采用全新的 MOE 架构并具备自主更新能力,是业界首个实现 “真正” 自主更新的多模态大模型。在视觉生成方面,Awaker 1.0 采用完全自研的视频生成底座 VDT,在写真视频生成上取得好于 Sora 的效果,打破大模型 “最后一公里” 落地难的困境。
的中关村论坛通用人工智能平行论坛上,人大系初创公司智子引擎隆重发布全新的多模态大模型 Awaker 1.0,向 AGI 迈出至关重要的一步。相对于智子引擎前代的 ChatImg 序列模型,Awaker 1.0 采用全新的 MOE 架构并具备自主更新能力,是业界首个实现 “真正” 自主更新的多模态大模型。在视觉生成方面,Awaker 1.0 采用完全自研的视频生成底座 VDT,在写真视频生成上取得好于 Sora 的效果,打破大模型 “最后一公里” 落地难的困境。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

Awaker 1.0 是一个将视觉理解与视觉生成进行超级融合的多模态大模型。在理解侧,Awaker 1.0 与数字世界和现实世界进行交互,在执行任务的过程中将场景行为数据反哺给模型,以实现持续更新与训练;在生成侧,Awaker 1.0 可以生成高质量的多模态内容,对现实世界进行模拟,为理解侧模型提供更多的训练数据。尤其重要的是,因为具备 “真正” 的自主更新能力,Awaker 1.0 适用于更广泛的行业场景,能够解决更复杂的实际任务,比如 AI Agent、具身智能、综合治理、安防巡检等。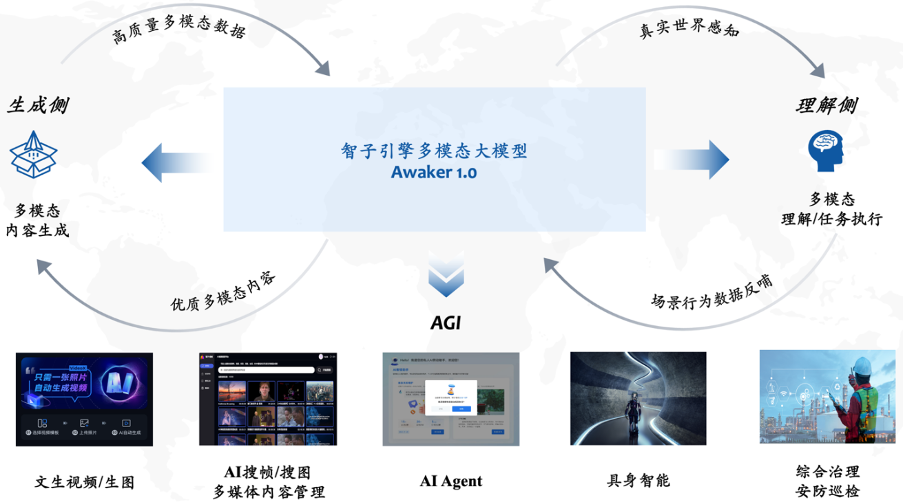
在理解侧,Awaker 1.0 的基座模型主要解决了多模态多任务预训练存在严重冲突的问题。受益于精心设计的多任务 MOE 架构,Awaker 1.0 的基座模型既能继承智子引擎前代多模态大模型 ChatImg 的基础能力,还能学习各个多模态任务所需的独特能力。相对于前代多模态大模型 ChatImg,Awaker 1.0 的基座模型能力在多个任务上都有了大幅提升。鉴于主流的多模态评测榜单存在评测数据泄露的问题,我们采取严格的标准构建自有的评测集,其中大部分的测试图片来自个人的手机相册。在该多模态评测集上,我们对 Awaker 1.0 和国内外最先进的三个多模态大模型进行公平的人工评测,详细的评测结果如下表所示。注意到 GPT-4V 和 Intern-VL 并不直接支持检测任务,它们的检测结果是通过要求模型使用语言描述物体方位得到的。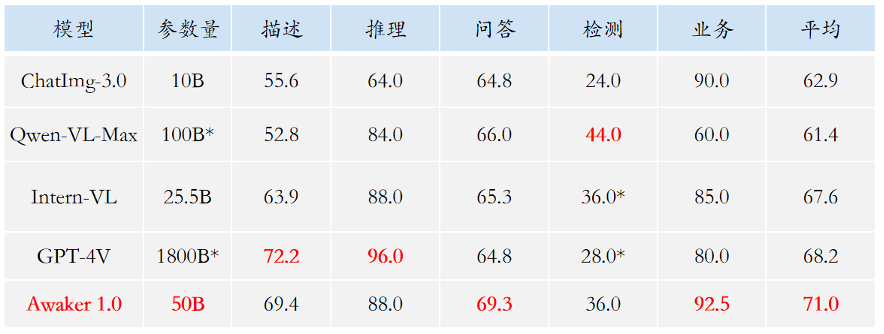
我们发现,Awaker 1.0 的基座模型在视觉问答和业务应用任务上超过了 GPT-4V、Qwen-VL-Max 和 Intern-VL,同时它在描述、推理和检测任务上也达到了次好的效果。总体而言,Awaker 1.0 的平均得分超过国内外最先进的三个模型,验证了多任务 MOE 架构的有效性。下面是几个具体的对比分析例子。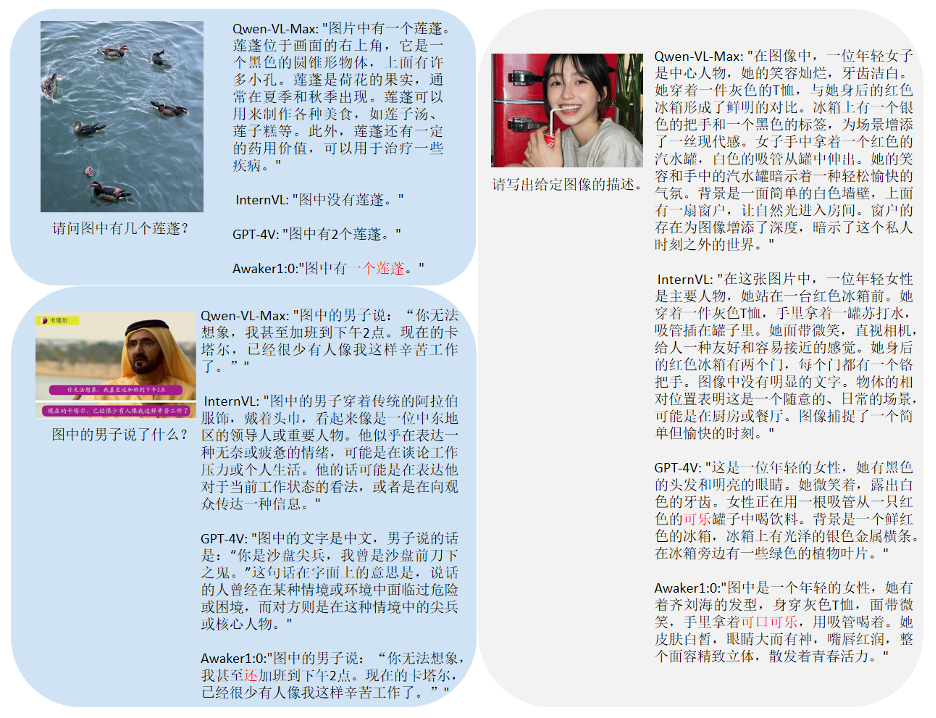
从这些对比例子可以看到,在计数和 OCR 问题上,Awaker 1.0 能正确地给出答案,而其它三个模型均回答错误(或部分错误)。在详细描述任务上,Qwen-VL-Max 比较容易出现幻觉,Intern-VL 能够准确地描述图片的内容但在某些细节上不够准确和具体。GPT-4V 和 Awaker 1.0 不但能够详细地描述图片的内容,而且能够准确地识别出图片中的细节,如图中展示的可口可乐。多模态大模型与具身智能的结合是非常自然的,因为多模态大模型所具有的视觉理解能力可以天然与具身智能的摄像头进行结合。在人工智能领域,“多模态大模型 + 具身智能” 甚至被认为是实现通用人工智能(AGI)的可行路径。一方面,人们期望具身智能拥有适应性,即智能体能够通过持续学习来适应不断变化的应用环境,既能在已知多模态任务上越做越好,也能快速适应未知的多模态任务。另一方面,人们还期望具身智能具有真正的创造性,希望它通过对环境的自主探索,能够发现新的策略和解决方案,并探索人工智能的能力边界。通过将多模态大模型用作具身智能的 “大脑”,我们有可能大幅地提升具身智能的适应性和创造性,从而最终接近 AGI 的门槛(甚至实现 AGI)。但是,现有的多模态大模型都存在两个明显的问题:一是模型的迭代更新周期长,需要大量的人力和财力投入;二是模型的训练数据都源自现有的数据,模型不能持续获得大量的新知识。虽然通过 RAG 和长上下文的方式也可以注入持续出现的新知识,但是多模态大模型本身并没有学习到这些新知识,同时这两种补救方式还会带来额外的问题。总之,目前的多模态大模型在实际应用场景中均不具备很强的适应性,更不具备创造性,导致在行业落地时总是出现各种各样的困难。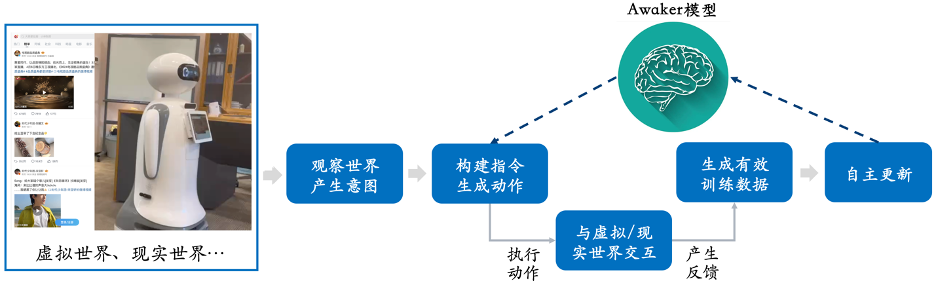
智子引擎此次发布的 Awaker 1.0,是世界上首个具有自主更新机制的多模态大模型,可以用作具身智能的 “大脑”。Awaker 1.0 的自主更新机制,包含三大关键技术:数据主动生成、模型反思评估、模型连续更新。区别于所有其它多模态大模型,Awaker 1.0 是 “活” 的,它的参数可以实时持续地更新。从上方的框架图中可以看出,Awaker 1.0 能够与各种智能设备结合,通过智能设备观察世界,产生动作意图,并自动构建指令控制智能设备完成各种动作。智能设备在完成各种动作后会自动产生各种反馈,Awaker 1.0 能够从这些动作和反馈中获取有效的训练数据进行持续的自我更新,不断强化模型的各种能力。以新知识注入为例,Awaker 1.0 能够不断地在互联网上学习最新的新闻信息,并结合新学习到的新闻信息回答各种复杂问题。不同于 RAG 和长上下文的传统方式,Awaker 1.0 能真正学到新知识并 “记忆” 在模型的参数上。

Remover
几秒钟去除图中不需要的元素
 304
查看详情
304
查看详情
 从上述例子可以看到,在连续三天的自我更新中,Awaker 1.0 每天都能学习当天的新闻信息,并在回答问题时准确地说出对应信息。同时,Awaker 1.0 在连续学习的过程中并不会遗忘学过的知识,例如智界 S7 的知识在 2 天后仍然被 Awaker 1.0 记住或理解。Awaker 1.0 还能够与各种智能设备结合,实现云边协同。Awaker 1.0 作为 “大脑” 部署在云端,控制各种边端智能设备执行各项任务。边端智能设备执行各项任务时获得的反馈又会源源不断地传回给 Awaker 1.0,让它持续地获得训练数据,不断进行自我更新。
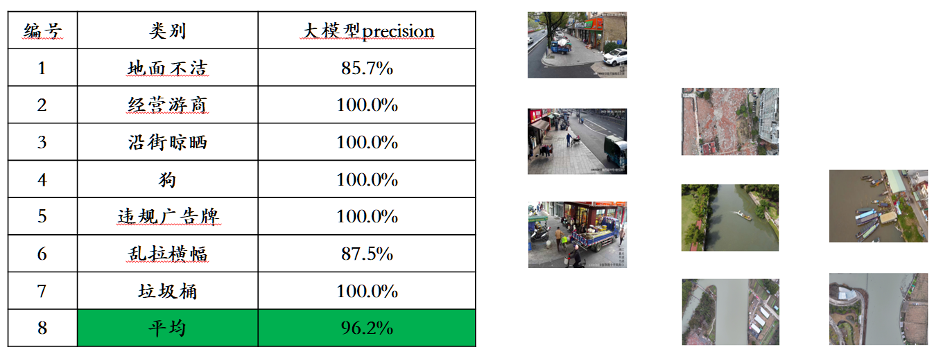
从上述例子可以看到,在连续三天的自我更新中,Awaker 1.0 每天都能学习当天的新闻信息,并在回答问题时准确地说出对应信息。同时,Awaker 1.0 在连续学习的过程中并不会遗忘学过的知识,例如智界 S7 的知识在 2 天后仍然被 Awaker 1.0 记住或理解。Awaker 1.0 还能够与各种智能设备结合,实现云边协同。Awaker 1.0 作为 “大脑” 部署在云端,控制各种边端智能设备执行各项任务。边端智能设备执行各项任务时获得的反馈又会源源不断地传回给 Awaker 1.0,让它持续地获得训练数据,不断进行自我更新。 上述云边协同的技术路线已经应用在电网智能巡检、智慧城市等应用场景中,取得了远远好于传统小模型的识别效果,并获得了行业客户的高度认可。
上述云边协同的技术路线已经应用在电网智能巡检、智慧城市等应用场景中,取得了远远好于传统小模型的识别效果,并获得了行业客户的高度认可。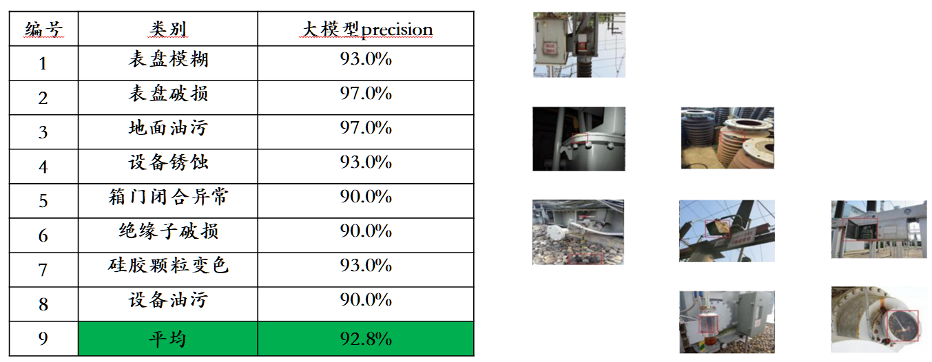
Awaker 1.0 的生成侧,是智子引擎自主研发的类 Sora 视频生成底座 VDT,可以用作现实世界的模拟器。VDT 的研究成果于 2025 年 5 月发布在 arXiv 网站,比 OpenAI 发布 Sora 提前 10 个月。VDT 的学术论文已经被国际顶级人工智能会议 ICLR 2025 接收。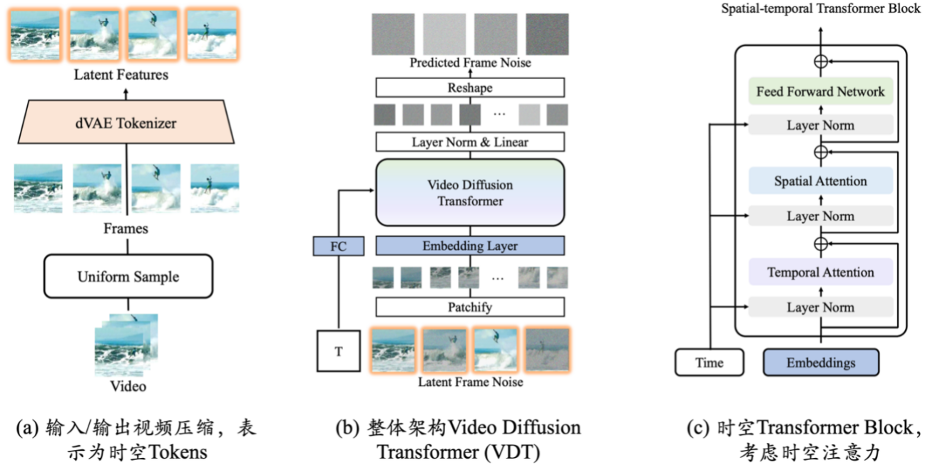
视频生成底座 VDT 的创新之处,主要包括以下几个方面:
- 将 Transformer 技术应用于基于扩散的视频生成,展现了 Transformer 在视频生成领域的巨大潜力。VDT 的优势在于其出色的时间依赖性捕获能力,能够生成时间上连贯的视频帧,包括模拟三维对象随时间的物理动态。
- 提出统一的时空掩码建模机制,使 VDT 能够处理多种视频生成任务,实现了该技术的广泛应用。VDT 灵活的条件信息处理方式,如简单的 token 空间拼接,有效地统一了不同长度和模态的信息。同时,通过与时空掩码建模机制结合,VDT 成为了一个通用的视频扩散工具,在不修改模型结构的情况下可以应用于无条件生成、视频后续帧预测、插帧、图生视频、视频画面补全等多种视频生成任务。
我们重点探索了 VDT 对简单物理规律的模拟,在 Physion 数据集上对 VDT 进行训练。在下面的示例中,我们发现 VDT 成功模拟了物理过程,如小球沿抛物线轨迹运动和小球在平面上滚动并与其他物体碰撞等。同时也能从第 2 行第 2 个例子中看出 VDT 捕捉到了球的速度和动量规律,因为小球最终由于冲击力不够而没有撞倒柱子。这证明了 Transformer 架构可以学习到一定的物理规律。
我们还在写真视频生成任务上进行了深度探索。该任务对视频生成质量的要求非常高,因为我们天然对人脸以及人物的动态变化更加敏感。鉴于该任务的特殊性,我们需要结合 VDT(或 Sora)和可控生成来应对写真视频生成面临的挑战。目前智子引擎已经突破写真视频生成的大部分关键技术,取得比 Sora 更好的写真视频生成质量。智子引擎还将继续优化人像可控生成算法,同时也在积极进行商业化探索。目前已经找到确定的商业落地场景,有望近期就打破大模型 “最后一公里” 落地难的困境。 未来更加通用的 VDT 将成为解决多模态大模型数据来源问题的得力工具。使用视频生成的方式,VDT 将能够对现实世界进行模拟,进一步提高视觉数据生产的效率,为多模态大模型 Awaker 的自主更新提供助力。Awaker 1.0 是智子引擎团队向着 “实现 AGI” 的终极目标迈进的关键一步。团队认为 AI 的自我探索、自我反思等自主学习能力是智能水平的重要评估标准,与持续加大参数规模(Scaling Law)相比是同等重要的。Awaker 1.0 已实现 “数据主动生成、模型反思评估、模型连续更新” 等关键技术框架,在理解侧和生成侧都实现了效果突破,有望加速多模态大模型行业的发展,最终让人类实现 AGI。
未来更加通用的 VDT 将成为解决多模态大模型数据来源问题的得力工具。使用视频生成的方式,VDT 将能够对现实世界进行模拟,进一步提高视觉数据生产的效率,为多模态大模型 Awaker 的自主更新提供助力。Awaker 1.0 是智子引擎团队向着 “实现 AGI” 的终极目标迈进的关键一步。团队认为 AI 的自我探索、自我反思等自主学习能力是智能水平的重要评估标准,与持续加大参数规模(Scaling Law)相比是同等重要的。Awaker 1.0 已实现 “数据主动生成、模型反思评估、模型连续更新” 等关键技术框架,在理解侧和生成侧都实现了效果突破,有望加速多模态大模型行业的发展,最终让人类实现 AGI。以上就是人大系多模态模型迈向AGI:首次实现自主更新,写真视频生成力压Sora的详细内容,更多请关注其它相关文章!
# 图中
# 泉州丰泽网站推广优化
# 五里店网站推广计划方案
# 柚子茶营销推广方案
# 新乡网站建设哪个好
# 营销推广费用全年占比
# 安庆酒店网络营销推广
# 宁夏门户网站优化
# 芒果营销怎么做推广好呢
# 搜索引擎营销推广模板
# 瑞幸营销推广方式有几种
# 应用于
# 可以看到
# 也能
# 产业
# 新知识
# 前代
# 基座
# 力压
# 首次
# 多模
# type
# sora
# follow
# ai agent
# qwen
# 模拟器
# 智子引擎
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
人工智能:解决劳动力短缺的关键策略
全球首款AI裸眼3D平板 国产的售价破万
马斯克回应人工智能拯救世界:人类已处于“半机器人”状态
了解 AGI:智能的未来?
甲骨文与Cohere合作为企业提供生成式人工智能服务
“上海市民营企业人工智能赋能创新中心”揭牌成立
360发布AI数字人广场,可同孙悟空、爱因斯坦等古今中外角色对话
1000万张照片训练AI模型 科学家找到水下定位新方法
Win11 AI 助手 Windows Copilot 被吐槽:套皮的 Edge 浏览器
海南省公安机关警用无人机培训班结业并举行警航比武演练
360°/180°双模式,佳能公布可折叠小体积的VR全景相机
争鸣:OpenAI奥特曼、Hinton、杨立昆的AI观点到底有何不同?
500元一张的AI艺术二维码制作,详细教程来了!
售价14.99万起!小米汽车部分信息疑遭AI曝光,内部人士回应:网传图片明显经过处理,不可轻信
智能机器人正在彻底改变客户服务
AMD在AI方面奋起直追,与英伟达的差距缩小了吗?
美图设计室2.0使用教程
国家发改委组织工业机器人产业高质量发展现场会
华为推出两款商用 AI 大模型存储新品,支持 1200 万 IOPS 性能
网易云音乐和小冰推出AI歌手音乐创作软件,首发内置12名AI歌手
软通动力多项AI创新产品及应用亮相2025世界人工智能大会
特斯拉首发人形机器人“擎天柱”亮相世界人工智能大会
学生作文评分的新趋势:教师与AI的合作模式
塑造全能智能管家:华为小艺AI加成应对大模型挑战
小米9号员工李明宣布创业:打造首款安卓桌面机器人
2025 年开发者必须知道的六个 AI 工具
调查:过半数艺术家认为 AI 作图无法帮助他们的工作
DeepMind用AI重写排序算法;将33B大模型塞进单个消费级GPU
百度文心一言App上架苹果商店,人工智能创作引发热议
鸿蒙生态带来了哪些新的流量可能性,包括AI、服务分发和原生智能等方面?
Snap宣布研发出新技术 可大幅提升AI生成图像速度
能抓取玻璃碎片、水下透明物,清华提出通用型透明物体抓取框架,成功率极高
特斯拉人形机器人将亮相 预计售价不超过15万元
当一切设备都受到人工智能的控制
谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型
测试框架-安全和自动驾驶
V社谈AI制作游戏被ban:为确保开发者有素材所有权
脑虎科技:奔跑在“脑机接口”最前沿 跨界融合取得阶段性成果
全媒封面丨⑤商汤科技:原创AI算法“发电厂”
朝鲜出现国产大型察打一体无人机,实力世界第二,太意外了
AI大模型火了!科技巨头纷纷加入,多地政策加码加速落地
科技有狠活|时光修复师 :用AI让昨日重现
周鸿祎参加中美青年科技创新峰会,分享人工智能创新机遇
超级智能到底是什么?
下一个前沿:量子机器学习和人工智能的未来
如何利用AI工具写好本科论文:科技助你一臂之力
焊接协作机器人或将成为26届埃森展最大看点
斑马推出全新升级版思维机:以人工智能为核心的交互式学习体验
学而思网校推出首个基于自研大模型的《人工智能第一课》
物联网“僵尸网络DDos攻击”增长惊人,威胁全球电信网络




 发布时间:2024-04-30
发布时间:2024-04-30 点击次数:
点击次数:  的中关村论坛通用人工智能平行论坛上,人大系初创公司智子引擎隆重发布全新的多模态大模型 Awaker 1.0,向 AGI 迈出至关重要的一步。
的中关村论坛通用人工智能平行论坛上,人大系初创公司智子引擎隆重发布全新的多模态大模型 Awaker 1.0,向 AGI 迈出至关重要的一步。 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

