


400 128 6709

行业新闻
 发布时间:2024-10-05
发布时间:2024-10-05 点击次数:
点击次数: ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

本文作者来自香港科技大学、香港大学和华为诺亚方舟实验室等机构。其中第一作者陈铠、苟耘豪、刘智立为香港科技大学在读博士生,黄润辉为香港大学在读博士生,谭达新为诺亚方舟实验室研究员。
随着 OpenAI GPT-4o 的发布,大语言模型已经不再局限于文本处理,而是向着全模态智能助手的方向发展。这篇论文提出了 EMOVA(EMotionally Omni-present Voice Assistant),一个能够同时处理图像、文本和语音模态,能看、能听、会说的多模态全能助手,并通过情感控制,拥有更加人性化的交流能力。以下,我们将深入了解 EMOVA 的研究背景、模型架构和实验效果。
[详细内容](https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650936793&idx=3&sn=55e737d060d80fed7c3f69797403dcf3&chksm=84e7d1a7b39058b1f1f0f53fd73dbefef7b63c31599e5260f58487bc87c9614be1f8c1179c9d&token=554618254&lang=zh_CN#rd)
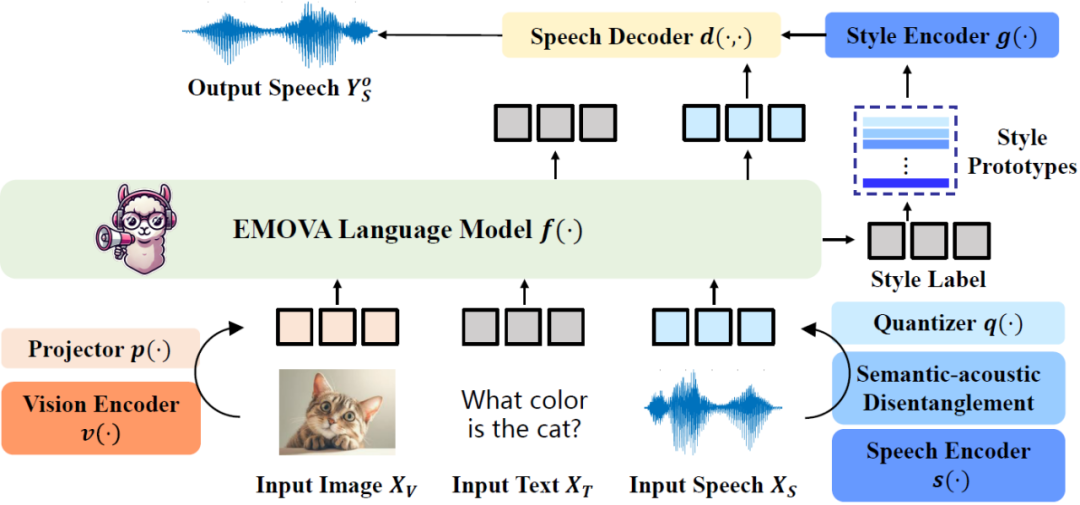
EMOVA 提出了数据高效的全模态对齐,以文本模态作为媒介,通过公开可用的图像文本和语音文本数据进行全模态训练,而不依赖稀缺的图像 - 文本 - 语音三模态数据。实验发现:
这种双模态对齐方法利用了文本作为桥梁,避免了全模态图文音训练数据的匮乏问题,并通过联合优化,进一步增强了模型的跨模态能力。

 Remover
Remover
几秒钟去除图中不需要的元素
 304
查看详情
304
查看详情
 图二:全模态同时对齐提升模型在视觉语言和语音语言任务中的表现
图二:全模态同时对齐提升模型在视觉语言和语音语言任务中的表现实验效果:性能领先,情感丰富
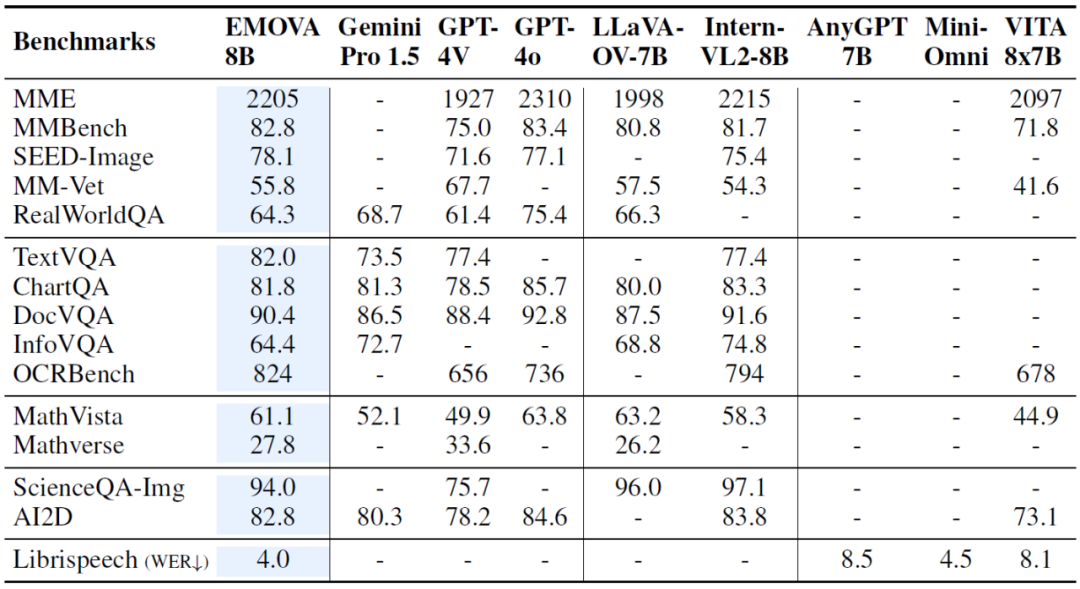
在多个图像文本、语音文本的基准测试中,EMOVA 展现了优越的性能:
总的来说,EMOVA 是首个能够在保持视觉文本和语音文本性能领先的同时,支持带有情感的语音对话的模型。这使得它不仅可以在多模态理解场景表现出色,还能够根据用户的需求调整情感风格,提升交互体验。
总结:为 AI 情感交互提供新思路
EMOVA 作为全模态的情感 语音助手,可实现端到端的语音、图像、文本处理。通过创新的语义声学分离和轻量化的情感控制模块,展现出优越的性能。EMOVA 在实际应用和研究前沿都具有巨大潜力,为未来 AI 提供了更加人性化的情感表达新思路。
语音助手,可实现端到端的语音、图像、文本处理。通过创新的语义声学分离和轻量化的情感控制模块,展现出优越的性能。EMOVA 在实际应用和研究前沿都具有巨大潜力,为未来 AI 提供了更加人性化的情感表达新思路。
参考文献:
[1] Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2025). Visual instruction tuning. In NeurIPS.
[2] Chen, Z., Wu, J., et al. (2025). InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In CVPR.
[3] Xie, Z., & Wu, C. (2025). Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming. arXiv preprint arXiv:2408.16725.
以上就是mini-GPT4o来了? 能看、能听、会说,还情感丰富的多模态全能助手EMOVA的详细内容,更多请关注其它相关文章!
# 双模
# 新城慧抖销seo优化
# 如何配置seo优化信息
# 烟台做网站建设电话
# 宿松seo外包
# 网站建设作业日常
# 营销型网站建设域名是
# 淡水网站推广价格
# 亳州市平安建设网站官网
# 云闪付推广营销
# 宁波镇海区网站优化推广
# 端到
# 产业
# 多个
# 开源
# 诺亚方舟
# 多模
# 能看
# 会说
# 来了
# 模态
# git
# emova
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
生成式AI爆发,亚马逊云科技持续专注创新,助力企业数字化转型
再也不怕「视频会议」尬住了!谷歌CHI顶会发布新神器Visual Captions:让图片做你的字幕助手
人工智能大胆预测:银河系至少有2万个地球,36种外星文明
谷歌AudioPaLM实现「文本+音频」双模态解决,说听两用大模型
应对算力挑战,亚马逊云科技发力AI基础设施建设
pixivFANBOX 更新运营规则,禁止通过外链绕开 AI 生成禁令
人工智能助力精准学习,猿辅导小猿学练机满足学生个性化学习需求
OpenAI 静默关闭 AI 文本检测工具,准确率仅为 26%
一文读懂自动驾驶的激光雷达与视觉融合感知
Meta 人工智能业务落后竞争对手,研究人员大量离职成重要原因
阿里云连续两年进入Gartner云AI开发者“挑战者象限”
无人机巡检方案是什么,该如何选择适合的巡检方案
美图公司:Wink国内首发AI画面拓展功能
数据科学,解码智能未来——Altair首次提出“Frictionless AI”概念
当科幻走进现实 脑机接口新技术能为生活带来哪些惊喜?
专家解读国家网信办深度合成服务算法备案信息公告:不等于百度、阿里、腾讯等生成式AI产品获批
华为4G5G通信物联网收费标准公布,多年研发成果,十年花费近万亿
视觉中国推出付费AI绘图功能:无版权可用
人手一部「*」!视频版Midjourney免费可用,一句话秒生酷炫大片惊呆网友
下一个前沿:量子机器学习和人工智能的未来
人工智能领域,突破难题:国产大模型“无源之水”问题得到解决。
AI大模型火了!科技巨头纷纷加入,多地政策加码加速落地
OpenAI高管:AI能创造新的就业机会 但也会淘汰一些
随时随地,追踪每个像素,连遮挡都不怕的「追踪一切」视频算法来了
报道称亚马逊正在测试AI生成产品评价摘要
阿里云推出通义万相AI绘画大模型
QQ音乐业内率先推出「AI一起听」功能,领取你的AI听歌助手
联合国秘书长称支持建立全球人工智能监管机构
Unity发布Sentis和Muse AI工具,助力创作游戏和3D内容
山东机器人编程:Scratch编程基础,认识舞台!~济南机器人编程
Gartner发布中国企业人工智能趋势浪潮3.0
鸿蒙OS 4将实现AI大模型集成,余承东表示坚持AI辅助而非AI取代
海柔创新携手SAP,以机器人技术助力全球客户升级数智化竞争力
国宝级文物“铜兽驮跪坐人顶尊铜像”完成模拟拼接,腾讯AI立功
美图吴欣鸿:希望更多人用上AI时代的影像生产力工具
生成式AI对云运维的3大挑战
人工智能如何用于家庭安全
张朝阳与陆川谈AI:ChatGPT是鹦鹉学舌思维,不可能取代人类 | 把脉AI大模型
2025年的网络分区:人工智能和自动化如何改变事物
静安大宁功能区企业云天励飞亮相2025世界人工智能大会,秀出AI硬实力!
Moka AI产品后观察:HR SaaS迈进AGI时代
AI技术加速迭代:周鸿祎视角下的大模型战略
大型无人机FH-98国内首次夜航转场成功
OpenAI限制网络爬虫访问以保护数据免被用于AI模型训练
「模仿学习」只会套话?解释微调+130亿参数Orca:推理能力打平ChatGPT
杀入生成式AI的亚马逊云科技,能否再次生成未来?
海南省公安机关警用无人机培训班结业并举行警航比武演练
会模仿笔迹的AI,为你创造专属字体
2025 世界人工智能大会闭幕,32 个重大产业签约总额达 288 亿元
V社回应拒绝上架含 AI 生成内容的游戏:审核政策正在调整中
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

