


400 128 6709

行业新闻
 发布时间:2024-10-21
发布时间:2024-10-21 点击次数:
点击次数: ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
论文第一作者张金涛来自清华大学计算机系,论文通讯作者陈键飞副教授及其他合作作者均来自清华大学计算机系。
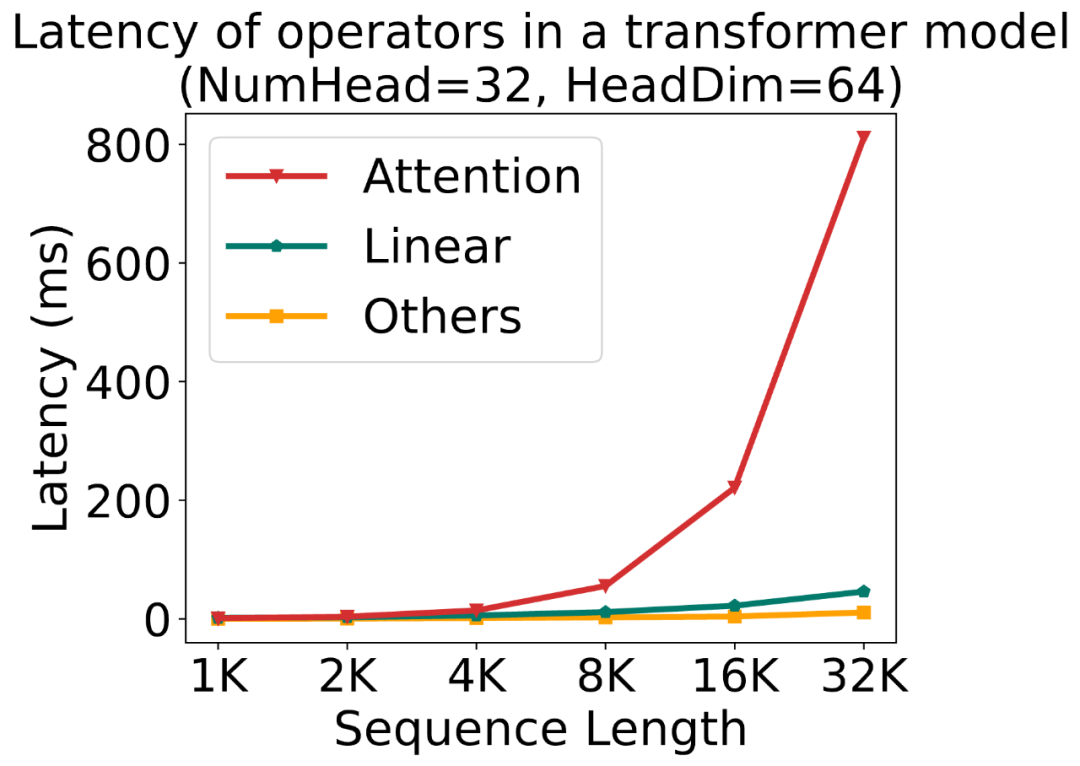
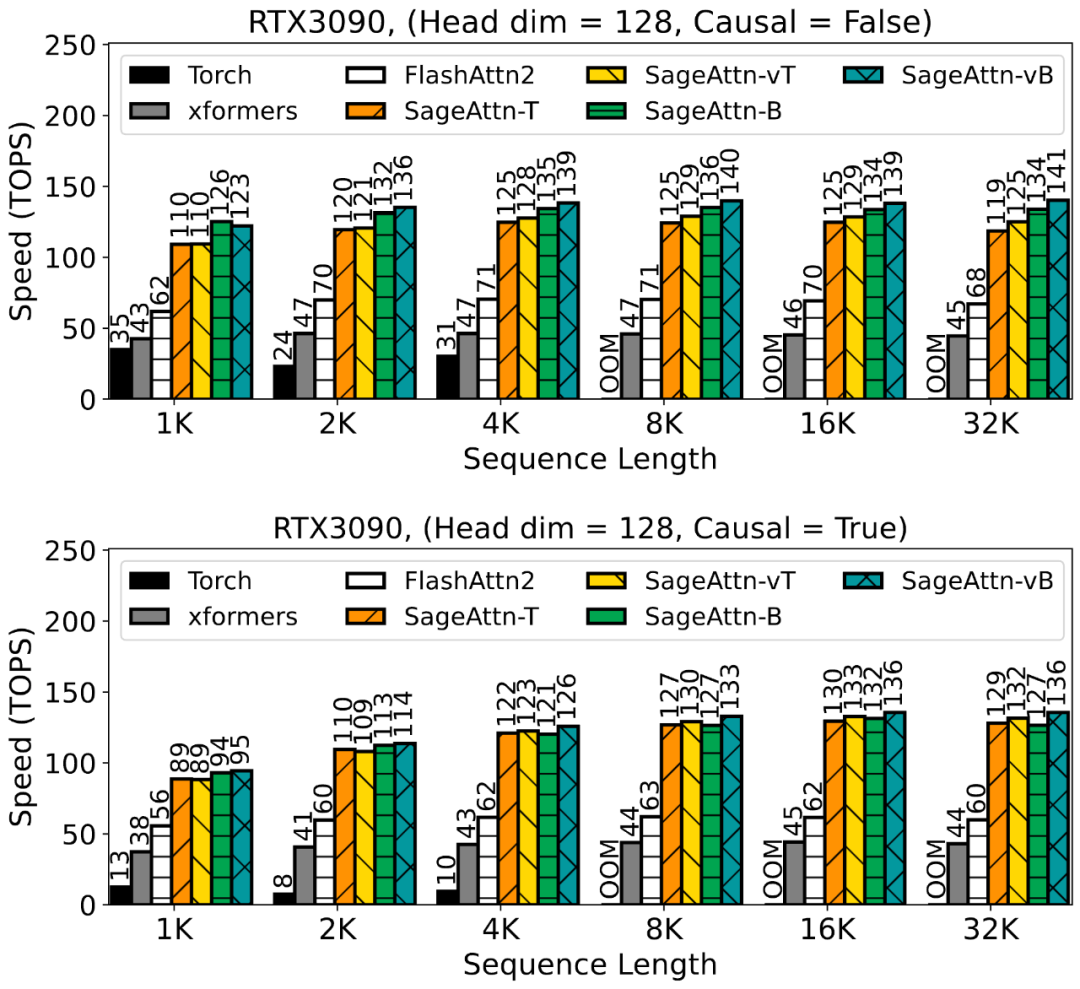
大模型中,线性层的低比特量化(例如 INT8, INT4)已经逐步落地;对于注意力模块,目前几乎各个模型都还在用高精度(例如 FP16 或 FP32)的注意力运算进行训练和推理。然而,随着大型模型需要处理的序列长度不断增加,Attention(注意力运算)的时间开销逐渐成为网络优化的主要瓶颈。
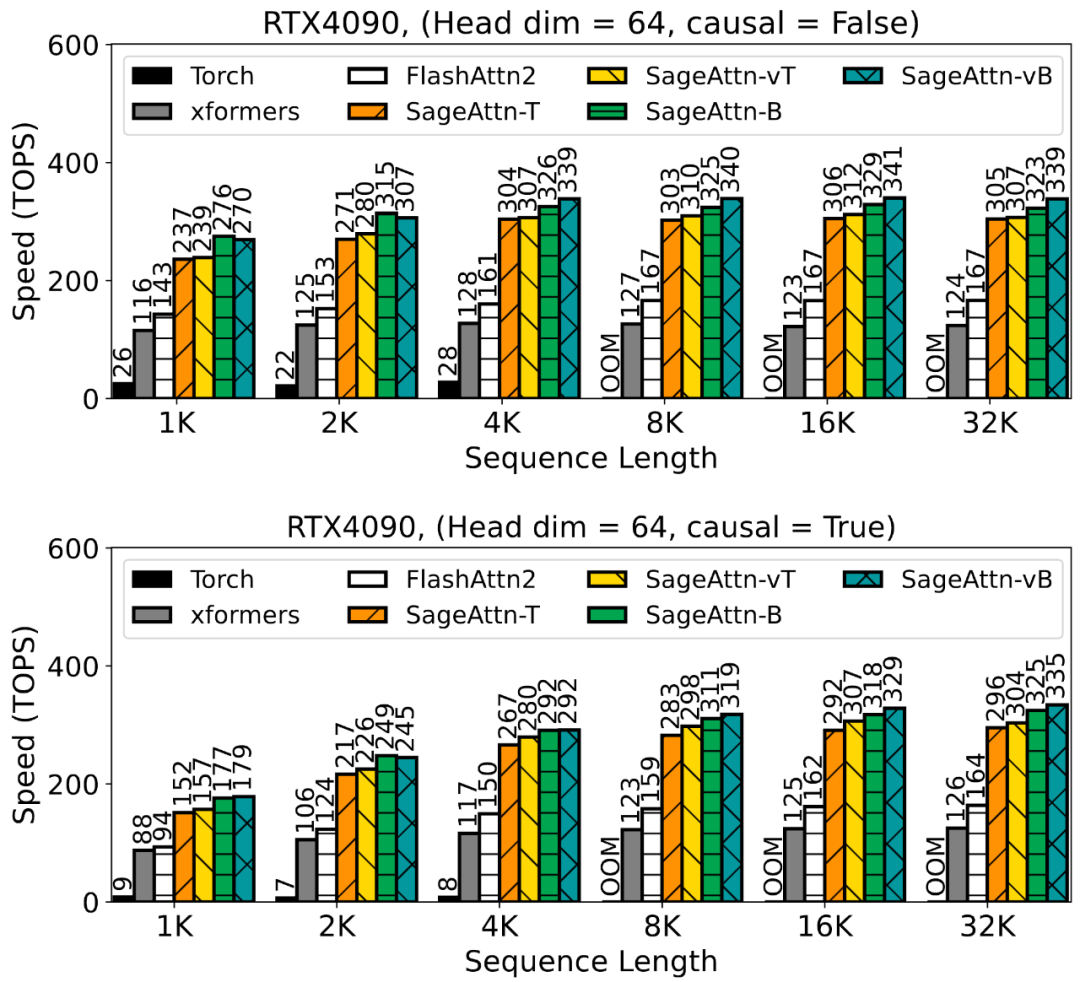
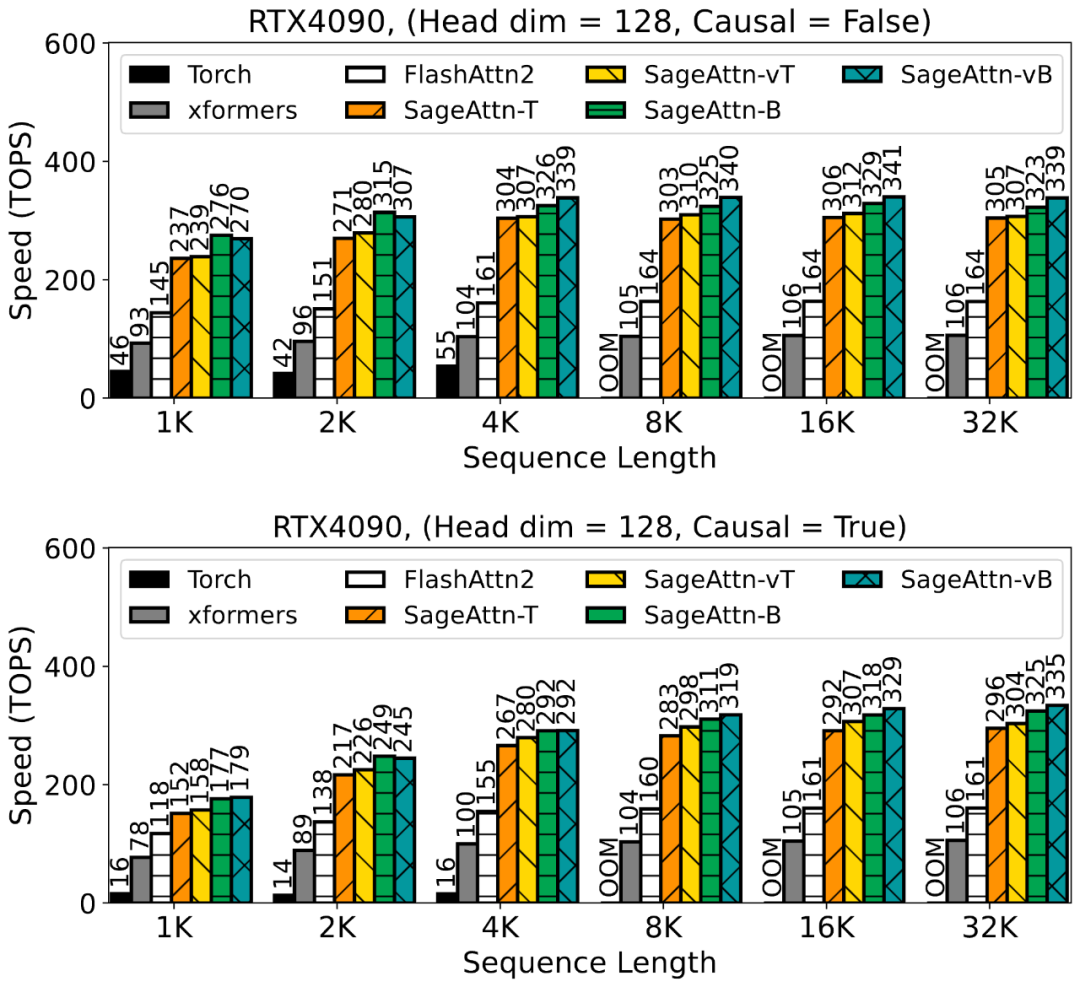
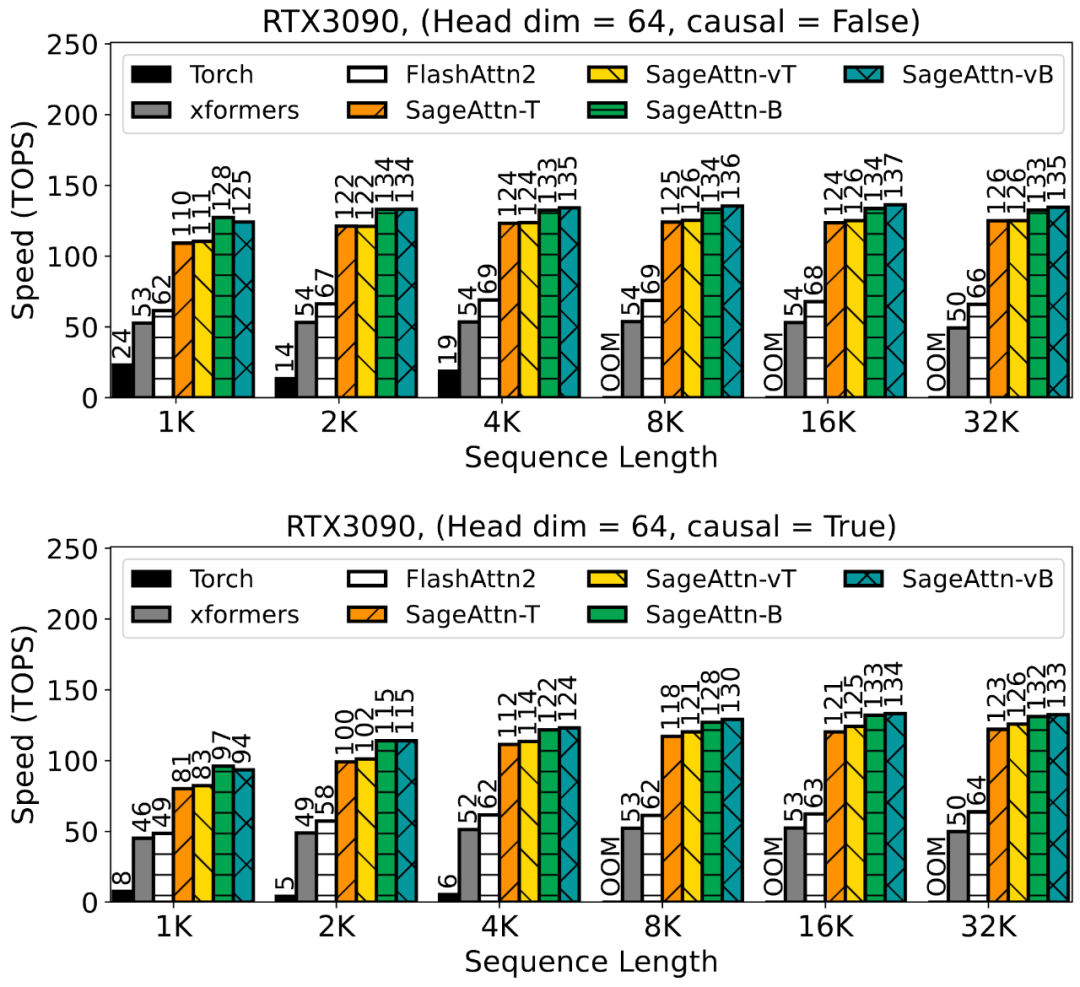
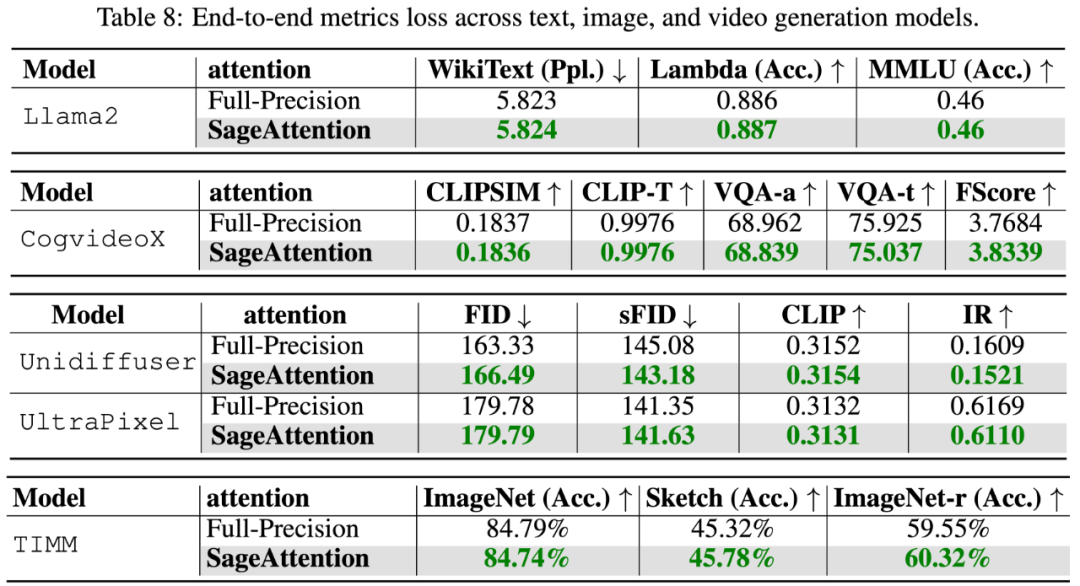
为了提高注意力运算的效率,清华大学陈键飞团队提出了 8Bit 的 Attention(SageAttention)。实现了 2 倍以及 2.7 倍相比于 FlashAttention2 和 xformers 的即插即用的推理加速,且在视频、图像、文本生成等大模型上均没有端到端的精度损失。

论文标题:SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration
论文链接:https://arxiv.org/abs/2410.02367
开源代码:https://github.com/thu-ml/SageAttention
 Remover
Remover
几秒钟去除图中不需要的 元素
元素
 304
查看详情
304
查看详情



 全精度 Attention
全精度 Attention 
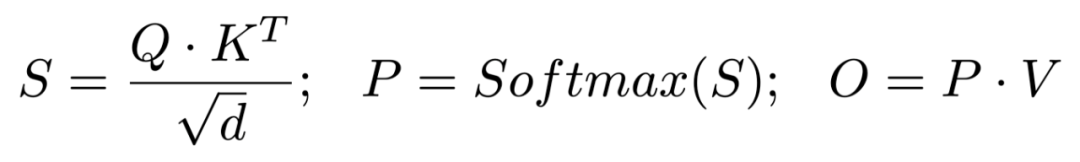

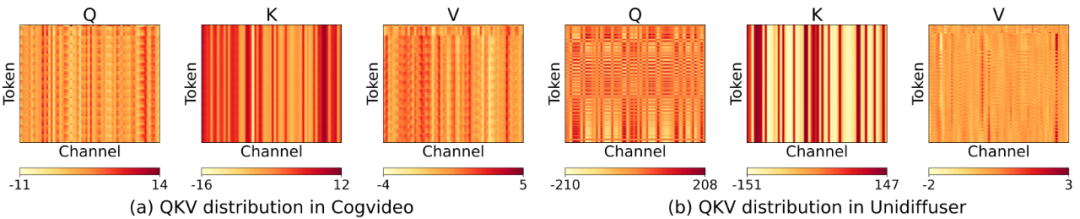
大多视频、图像生成模型中,矩阵 K 表现出了极强的通道维度的异常值分布,直接使用 INT8 或者 FP8 数据类型对其进行量化会导致巨大的误差。
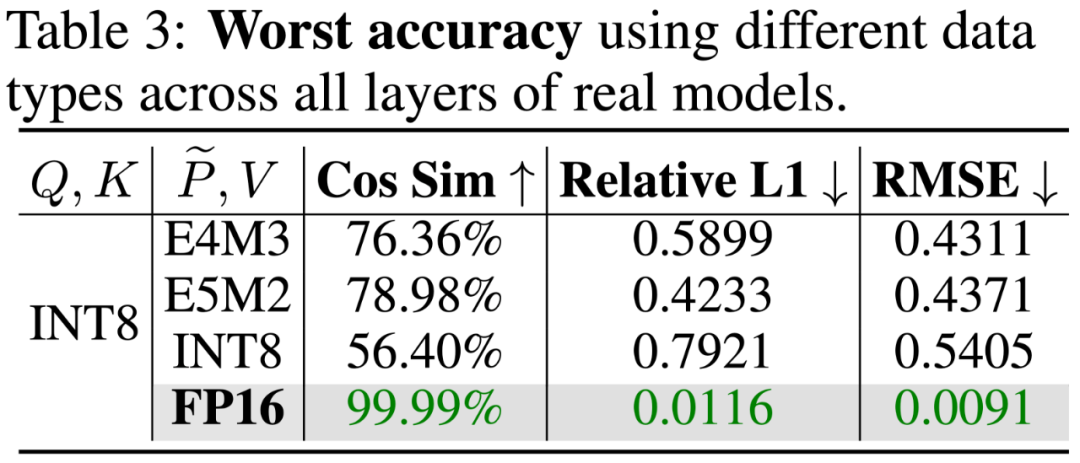
在所有模型中,对矩阵 P, V 进行量化不能保证一个模型中所有层的精度。下表展示了对 P, V 量化后,Llama2-7B 和 Unidiffuser 模型所有层中,最差情况的层对应的量化注意力的准确度,(该准确度为量化注意力相比全精度注意力的误差),可以发现不管对 P, V 矩阵进行何种 8Bit (INT8,E4M3,E5M2)量化,总有些层的准确率非常差,导致了端到端效果的下降。
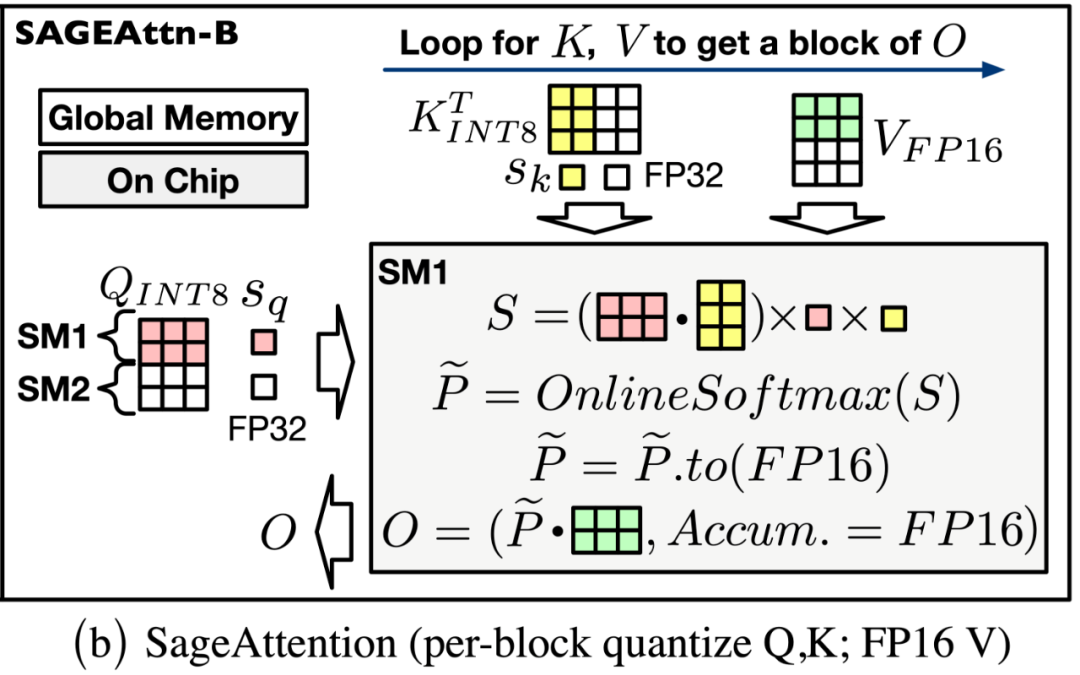
对 K 进行平滑处理。SageAttention 采用了一个简单但非常实用的方法来消除矩阵 K 的异常值:K = K – mean (K) 其中 mean (K) 是沿着通道维度求平均值。这个简单的做法不仅不会影响注意力计算的正确性 Softmax (QK^T) = Softmax (Q (K-mean (K))^T) ;且对整个 Attention 速度的影响只有 0.2%;同时还保证了量化后的注意力运算的精度:

对 Q, K 进行分块 INT8 量化。对于矩阵 Q, K,SageAttention 采用了以 FlashAttention 的分块大小为粒度的 INT8 量化。这是因为:1. 对 Q, K 矩阵进行 INT8 量化相比于进行 FP8 量化,注意力的精度更高。2. 在一些常用卡上,比如 RTX4090,INT8 矩阵乘法(INT32 为累加器)的速度是 FP8(FP32 为累加器)的两倍。
对 P, V 采用 FP16 数据类型的矩阵乘法累加器。对于矩阵 P, V,SageAttention 采用了保留 P, V 为 FP16 的类型,但进行矩阵乘法时采用 FP16 数据类型的累加器。这是因为:1. PV 矩阵乘法的数值范围始终在 FP16 的表示范围内,且经过大量实验验证,FP16 作为累加器的数据类型不会带来任何精度损失(见下表)。2. 在一些常用卡上,比如 RTX4090,以 FP16 为累加器数据类型的矩阵乘法的速度是 FP32 作为累加器的两倍。



以上就是又快又准,即插即用!清华8比特量化Attention,两倍加速于FlashAttention2,各端到端任务均不掉点!的详细内容,更多请关注其它相关文章!
# 累加器
# 兴安盟网站优化
# 公文评论网站排名优化
# 杭州seo软件专注乐云seo
# 重庆策划型seo代运营
# 买seo推广靠谱吗
# 产品推广话题营销方案
# 常州产品网站建设哪家好
# 昌平网站推广的平台
# seo求职总结
# 卫生产品网站排名优化
# 展示了
# 清华大学
# 工程
# 快又准
# 即插
# 均不
# 端到
# 两倍
# 即用
# 清华
# type
# follow
# llama
# 邮箱
# git
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
构建AI绘画网站的方法:使用API接口和调用步骤
如何利用物联网技术提高企业生产线智能化水平,提升生产效率
学而思推出AI第一课:基于自研大模型的AIGC课程
阿里大文娱CTO郑勇:生成式AI将引发内容行业巨变,*制作机会挑战并存
人工智能大胆预测:银河系至少有2万个地球,36种外星文明
城市在采用人工智能方面进展如何?
微软宣布为 Azure AI 添加男性声线,增强文本转语音功能
pixivFANBOX 更新运营规则,禁止通过外链绕开 AI 生成禁令
陈根:ChatGPT和人类合作开发机器人
读创正式上线“读创AI聊”功能
构建人机交互创新模式,微美全息研究AIGC智能交互界面生成技术
WHEE功能介绍
令人惊叹!AI模型能够以iPhone照片为基础创作诗歌
社区里,孩子们体验“机器人竞技”
世界人工智能大会中西部县域数字就业中心组团亮相
DreamAvatar数字人在哪里下载
亚马逊确认今年不会举办 re:MARS 机器人和人工智能大会
企业软件行业更将被AI全面重构!Moka李国兴:未来优秀组织和个人将一定是善于使用AI生产力的
甲骨文与Cohere合作为企业提供生成式人工智能服务
PS AI修图免费平替来了!Stability AI又放大招,核弹级更新一键扩图
人工智能驱动艺术,打开达利的超现实想象
干货满满,2025昆山元宇宙国际装备展等你来打卡!
陈丹琦ACL学术报告来了!详解大模型「*」数据库7大方向3大挑战,3小时干货满满
探展WAIC | 第四范式“式说”聚焦toB大模型,布局生成式AI重构企业软件
三个全球首创,青岛西海岸新区“海元宇宙”亮相世界人工智能大会
音乐制作元工具AudioCraft发布开源AI工具
MiracleVision视觉大模型
华为4G5G通信物联网收费标准公布,多年研发成果,十年花费近万亿
北京市元宇宙产业创新中心筹建工作正式启动
消息称字节机器人团队已有约50人,计划年底扩充到上百人
视觉中国推出付费AI绘图功能:无版权可用
上海发布大模型政策 打造AI“模”都
布局智能物联新时代,中国移动“5G+物联网”亮相2025 MWC
中国联通发布图文AI大模型,可实现以文生图、视频剪辑
Moka AI产品后观察:HR SaaS迈进AGI时代
美图设计室2.0新增哪些功能
人工智能加速走进百姓生活:从2025全球人工智能技术大会看行业新趋势
探索人工智能和物联网的动态融合
苹果AI战略与微软谷歌大相径庭,到底是领先还是落后?
物联网和人工智能的协同作用:释放预测性维护的潜力
鉴智机器人发布基于地平线征程5的标准视觉感知产品
借力AI!PCB全球巨头,有爆发潜质吗?
2025WRC世界机器人大赛锦标赛(烟台)收官!斯坦星球勇夺VEX赛项冠亚军!
人工智能在重症监护室的未来
人工智能助力林草行业高质量发展
世界人工智能大会(WAIC 2025)点燃魔都,博尔捷数字科技携前沿技术产品亮相
人工智能:解决劳动力短缺的关键策略
华为推出两款商用 AI 大模型存储新品,支持 1200 万 IOPS 性能
Meta推出VR订阅服务Quest +:每月免费玩两款游戏,7.99美元/月
1分钟做出苹果Vision Pro「官网」?上班8小时搞出480个网页,同事被卷疯了
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

