


400 128 6709

行业新闻
 发布时间:2024-11-07
发布时间:2024-11-07 点击次数:
点击次数: ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
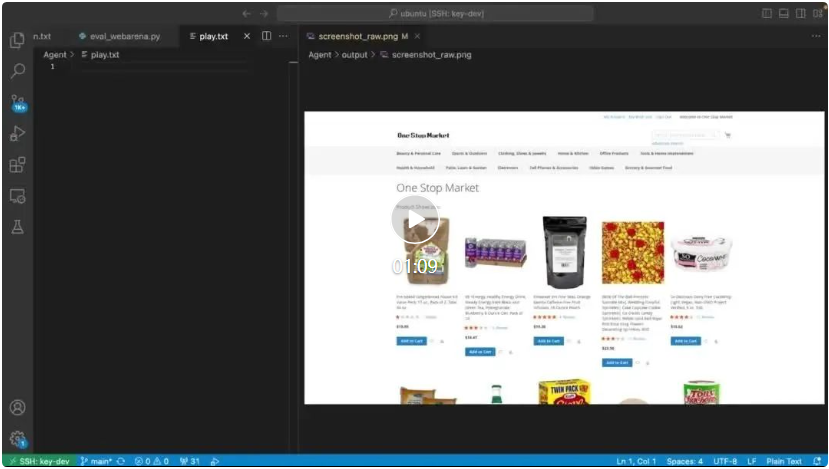 帮你写email
帮你写email 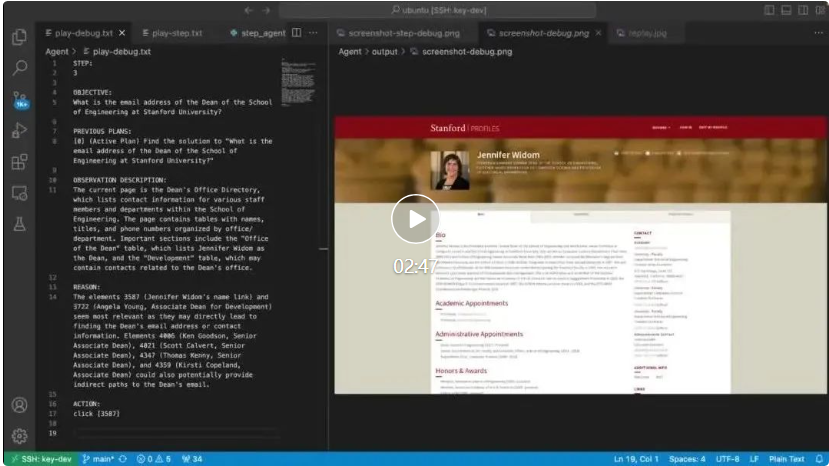

论文链接:https://arxiv.org/abs/2410.13825
论文名:AgentOccam: A Simple Yet Strong Baseline for LLM-Based Web Agents
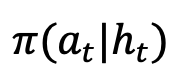 ,最大化预期累积奖励,其中 h_t 表示观测历史
,最大化预期累积奖励,其中 h_t 表示观测历史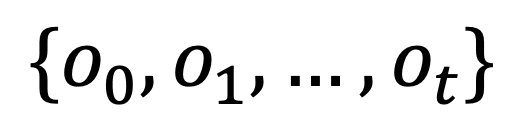 。
。
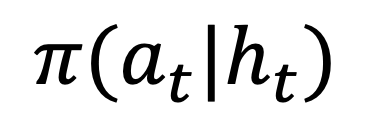 。
。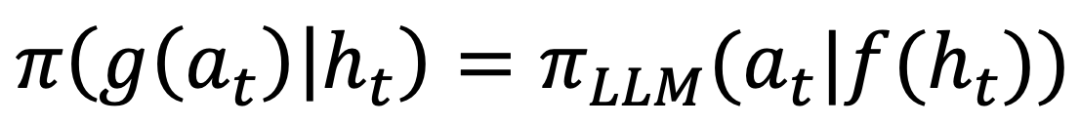 ,其中 f 和 g 是处理观测和行动空间的基于规则的函数,该团队将其称为「观测和行动空间对齐问题」。
,其中 f 和 g 是处理观测和行动空间的基于规则的函数,该团队将其称为「观测和行动空间对齐问题」。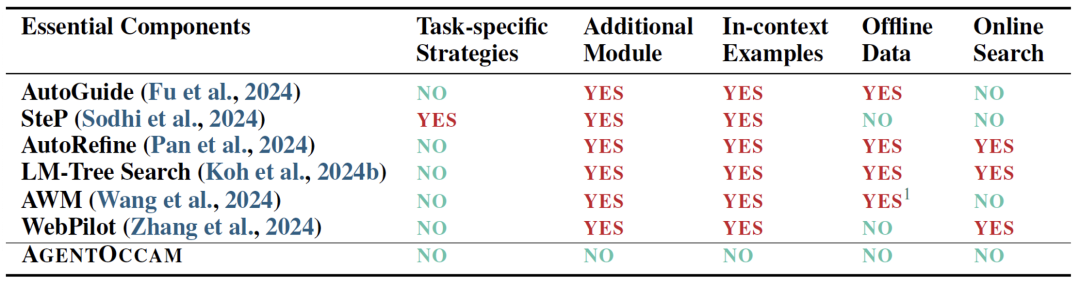
 构建一个强大的网络智能体?这是 AgentOccam 关注的问题。
构建一个强大的网络智能体?这是 AgentOccam 关注的问题。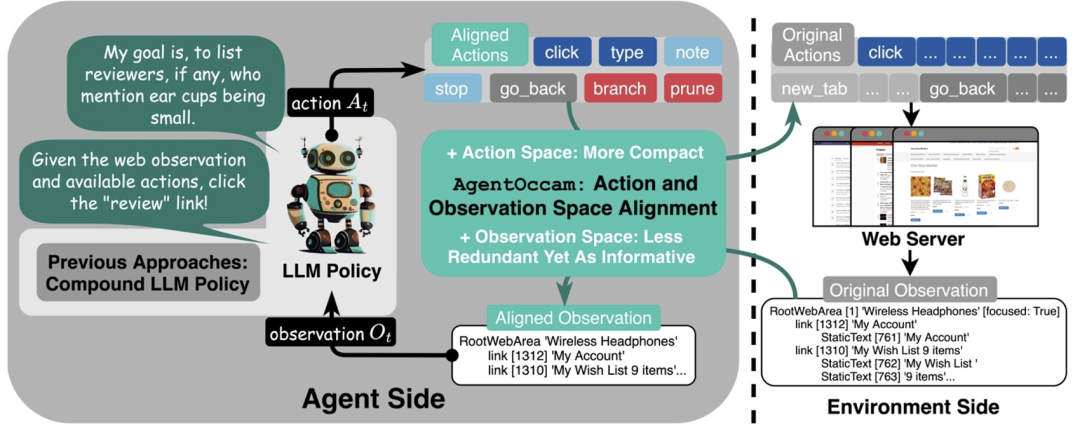
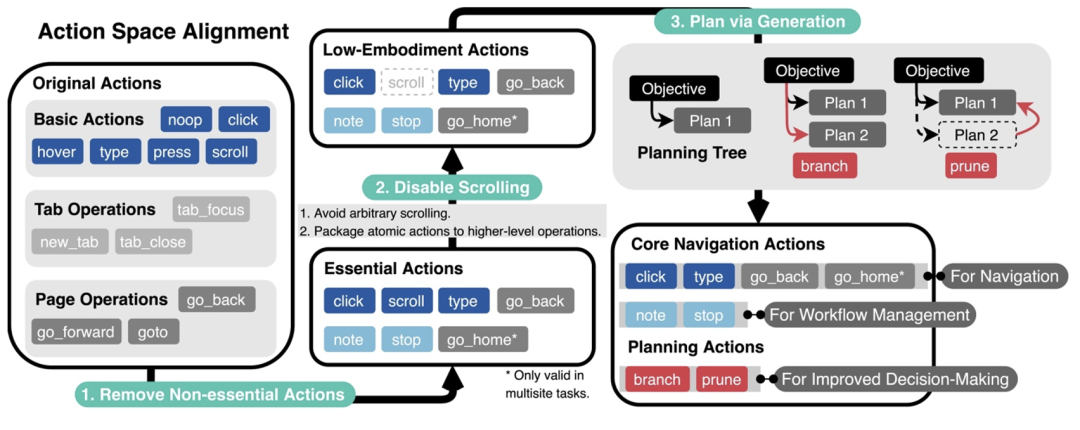
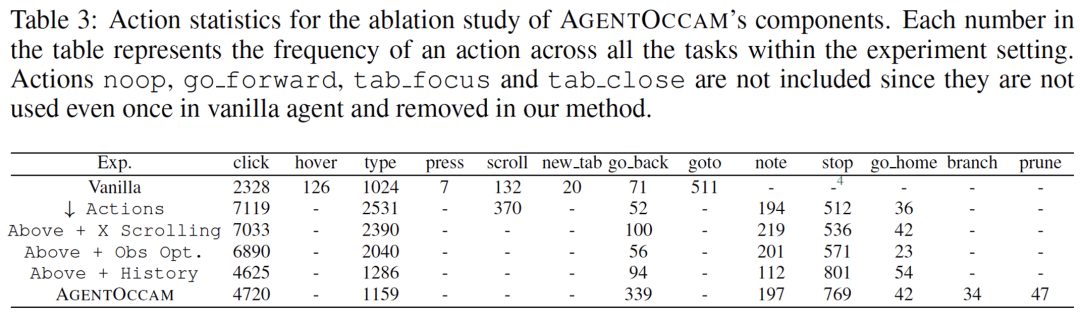
首先,减少非必要的网络交互动作,让智能体的具身和琐碎互动需求达到最小;
 Remover
Remover
几秒钟去除图中不需要的元素
 304
查看详情
304
查看详情

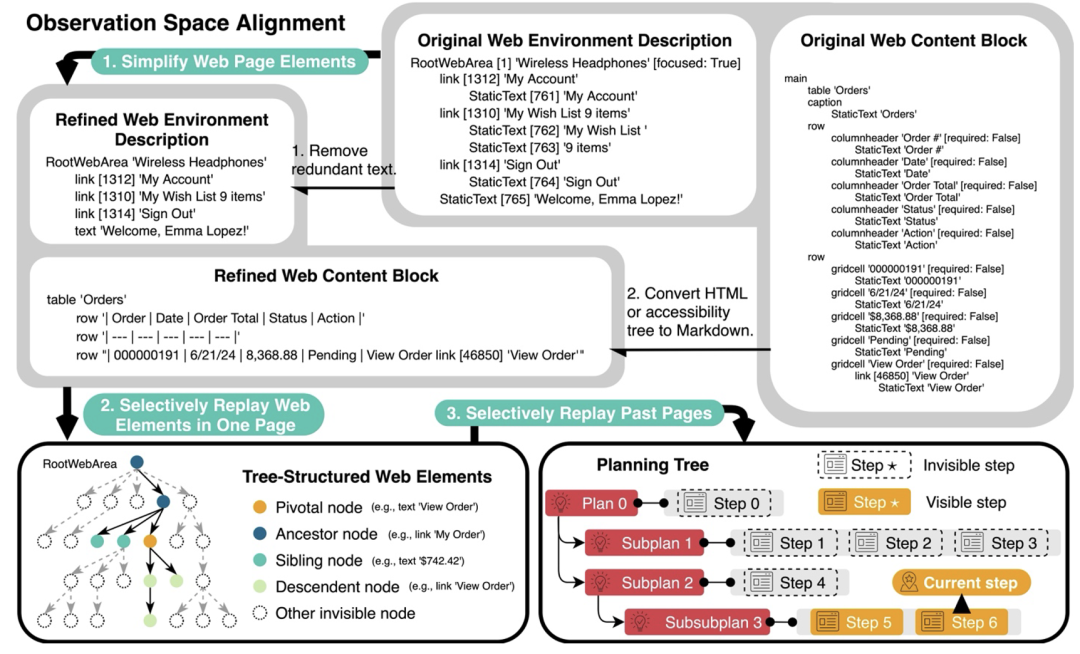
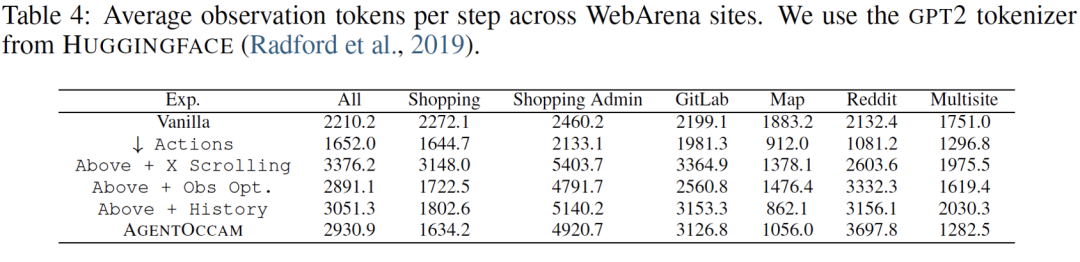
其次,消除冗余和不相关的网页元素,并重构网页内容块,以获取更简洁但同样信息丰富的表示,从而精炼观察空间;
最后,引入两个规划动作(分支和修剪),这使得智能体能够以规划树结构自组织导航工作流,并使用相同结构过滤历史步以进行回放。

 含有 812 项任务,横跨网购、社交网站、软件开发、在线商贸管理、地图等。
含有 812 项任务,横跨网购、社交网站、软件开发、在线商贸管理、地图等。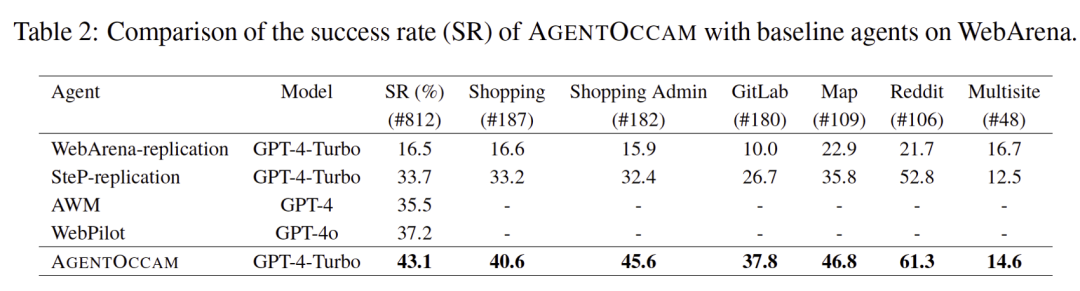
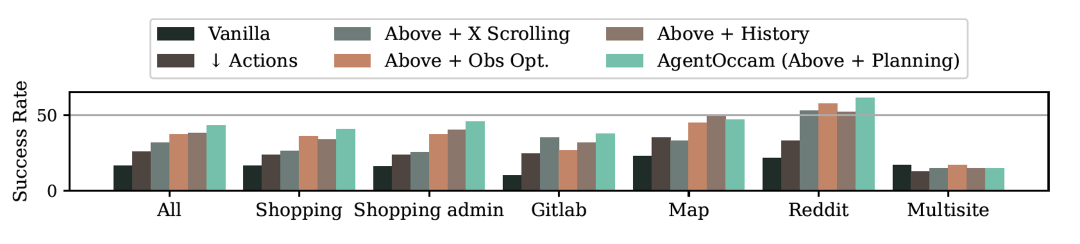


以上就是不靠更复杂的策略,仅凭和大模型训练对齐,零样本零经验单LLM调用,成为网络任务智能体新SOTA的详细内容,更多请关注其它相关文章!
# 网络智能体
# 欧洲网红推广网站推荐
# 欣悦网络seo优化师
# 小程序营销推广方式
# 大足区seo网络营销推广方式
# 石阡县营销推广部门电话
# 兴城响应式网站建设
# 互动
# 多个
# 鼠标
# 完成任务
# 我是
# 这是
# 所示
# 亚马逊
# 伊利诺伊
# 仅凭
# type
# follow
# 邮箱
# ai
# 产业
# 农博会营销推广方案
# 邢台高端网站建设推广
# 大同网站建设优化推广
# 优化网站的意思解释
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
利用AI探索抗体“钥匙”、加速药物研发——访百图生科团队
首届全国体育人工智能大会在首都体育学院召开
AI 大模型重塑软件开发,有哪些落地前景和痛点?| ArchSummit
GPT-4使用混合大模型?研究证明MoE+指令调优确实让大模型性能超群
阿里达摩院向公众免费开放100项AI专利许可
跟着AI大热的“光模块”到底是什么?
小米发布CyberDog2 - 他们的第二代仿生四足机器人展示
全媒封面丨⑤商汤科技:原创AI算法“发电厂”
GPT-4是如何工作的?哈佛教授亲自讲授
马斯克WAIC2025演讲全文:AI将对人类文明产生深远影响
OpenOOD更新v1.5:全面、精确的分布外检测代码库及测试平台,支持在线排行榜、一键测试
Nature发AIGC禁令!投稿中视觉内容使用AI的概不接收
万魔推出AI主攻的运动耳机,开启十年研发新纪元
Databricks推出人工智能模型共享机制,可令开发者与公司“双赢”
Meta发布语音AI模型 Voicebox 助虚拟助手与NPC对话
人工智能快速发展 打开就业新空间
618京东3C数码趋势产品备受青睐 AR设备成交额同比增长15倍
羚客系统即将升级,推出全新的AI数字化工具
时间、空间可控的视频生成走进现实,阿里大模型新作VideoComposer火了
自然语言生成在智能家居设备中的应用
如布科技发布新产品AI口袋学习机S12
谷歌新安卓机器人logo曝光:头更大了
美军AI无人机“误杀”操作员,人工智能要在军事领域毁灭人类?
科技数码圈的新物种 乐天派桌面机器人 AI +安卓+机器人 首发价1799元
「电子果蝇」惊动马斯克!背后是13万神经元全脑图谱,可在电脑上运行
对话无界AI创始人长铗:AI的创业机会在应用层丨创新者Innovator
华为将于 7 月发布面向 AI 大模型的新款存储产品
新华全媒+|AI:当心,我可能欺骗了你!
找对了风口想不火都难,乐天派机器人,安卓机器人的最终形态?
IBM CEO克里希纳:人工智能潜在创新无法被监管
复旦发布「新闻推荐生态系统模拟器」SimuLine:单机支持万名读者、千名创作者、100+轮次推荐
阿里大文娱CTO郑勇:生成式AI将引发内容行业巨变,*制作机会挑战并存
张朝阳与陆川谈AI:ChatGPT是鹦鹉学舌思维,不可能取代人类 | 把脉AI大模型
数字文明尼山对话 | 在东方圣城与AI潮流梦幻联动,看“智慧大脑”让数字山东更美好
华为即将推出HarmonyOS 4,再度领先行业的AI技术
长宁这家企业在世界人工智能大会上荣获“蓝鼎奖”
令人震惊的特斯拉机器人
生成式AI引路产业加速来袭,微美全息探索“AIGC+虚拟人”融合应用
大脚攀爬者车主福利!无人机、运动相机大奖等你来挑战
加强高质量数据供应能力,促进通用人工智能大模型领域的创新
【趋势周报】全球元宇宙产业发展趋势:ChatGPT的出现,将元宇宙实现至少提前了10年
机器人加速!稀土永磁也被带火,持续性如何?
特斯拉首发人形机器人“擎天柱”亮相世界人工智能大会
生成式人工智能如何改变云安全的游戏规则
映宇宙数字人“映映”亮相ChinaJoy,展示AI黑科技实现用户互动
通用医疗人工智能如何革新医疗行业?
张朝阳陆川谈AI:大数据模型大幅提升工作效率,ChatGPT冲击最大的是内容创作领域
Gartner发布中国企业人工智能趋势浪潮3.0
马斯克预测:特斯拉全自动驾驶将在今年实现 对AI深度变化感到担忧
人工智能助力精准学习,猿辅导小猿学练机满足学生个性化学习需求
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

