


400 128 6709

行业新闻
 发布时间:2024-11-14
发布时间:2024-11-14 点击次数:
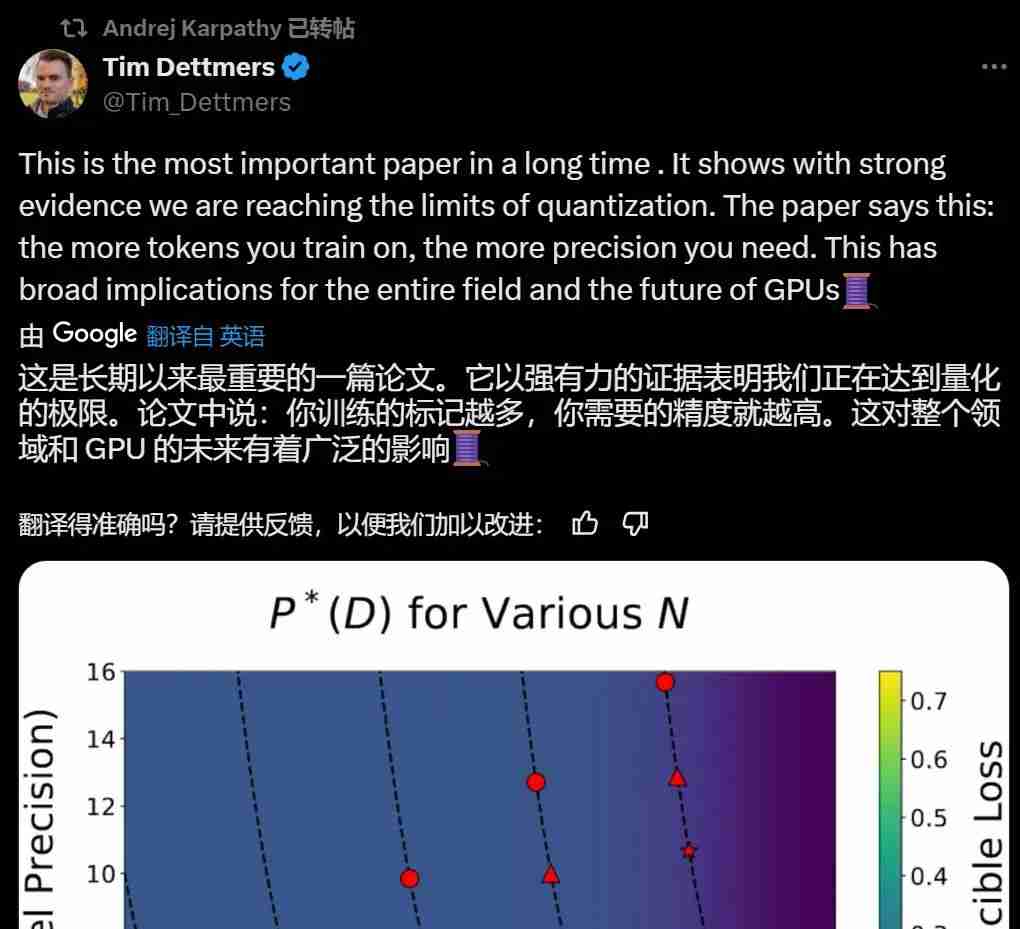
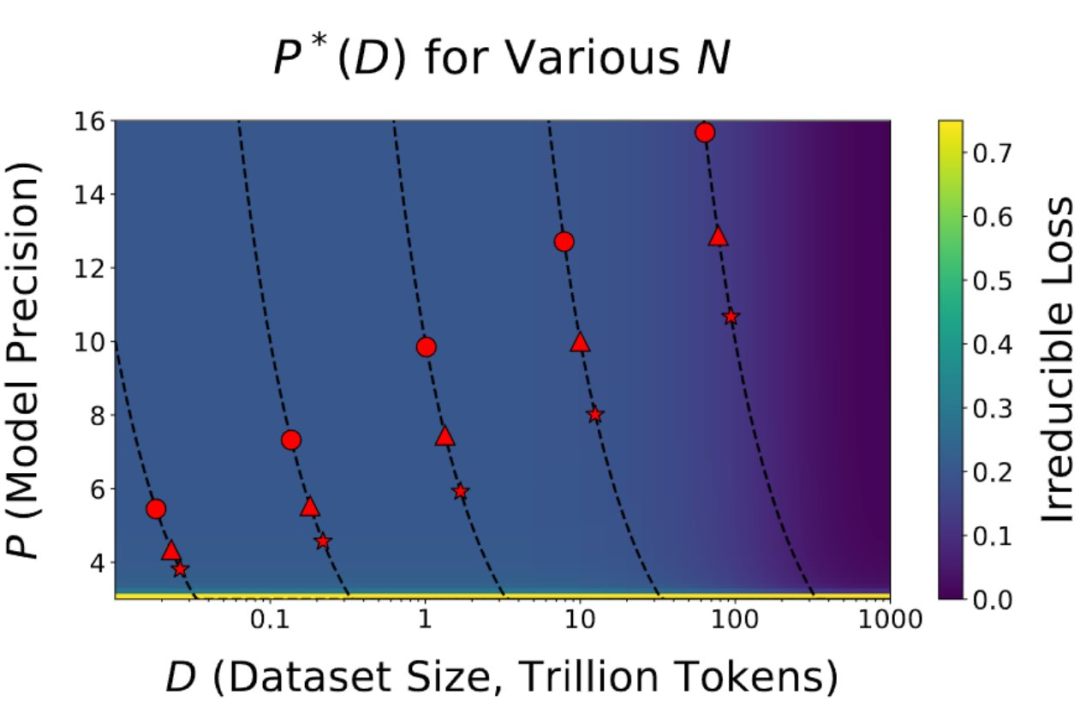
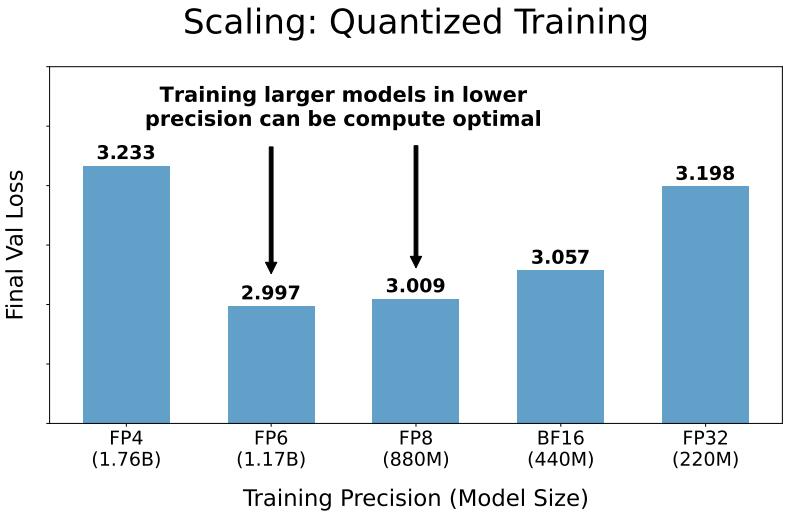
点击次数: 研究表明,你训练的 token 越多,你需要的精度就越高。
最近几天,AI 社区都在讨论同一篇论文。
UCSD 助理教授 Dan Fu 说它指明了大模型量化的方向。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

CMU 教授 Tim Dettmers 则直接说:它是很长一段时间以来最重要的一篇论文。OpenAI 创始成员、特斯拉前 AI 高级总监 Andrej Karpathy 也转发了他的帖子。
扩大数据中心规模:未来约 2 年这仍然是可以做到的事;
通过动态扩展:路由到更小的专门模型或大 / 小模型上;
 Remover
Remover
几秒钟去除图中不需要的元素
 304
查看详情
304
查看详情

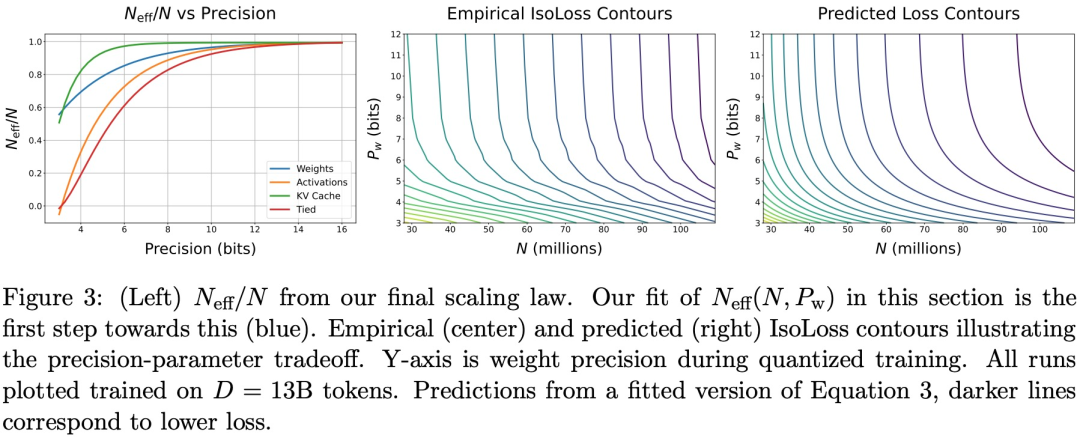
知识的提炼:这条路线与其他技术不同,并且可能具有不同的特性。
 》的论文顾名思义,制定了一个和大语言模型使用数据精度有关的扩展定律,涵盖了训练前和训练后。
》的论文顾名思义,制定了一个和大语言模型使用数据精度有关的扩展定律,涵盖了训练前和训练后。
论文标题:Scaling Laws for Precision
论文链接:https://arxiv.org/abs/2411.04330
由于当代大模型在大量数据上经历了过度训练,因此训练后量化已变得非常困难。因此,如果在训练后量化,最终更多的预训练数据可能会造成副作用;
在预训练期间以不同的精度放置权重、激活或注意力的效果是一致且可预测的,并且拟合扩展定律表明,高精度(BF16)和下一代精度(FP4)的预训练可能都是次优的设计选择。
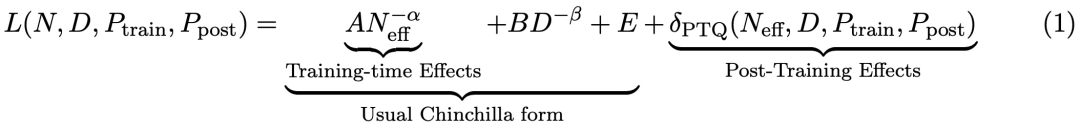

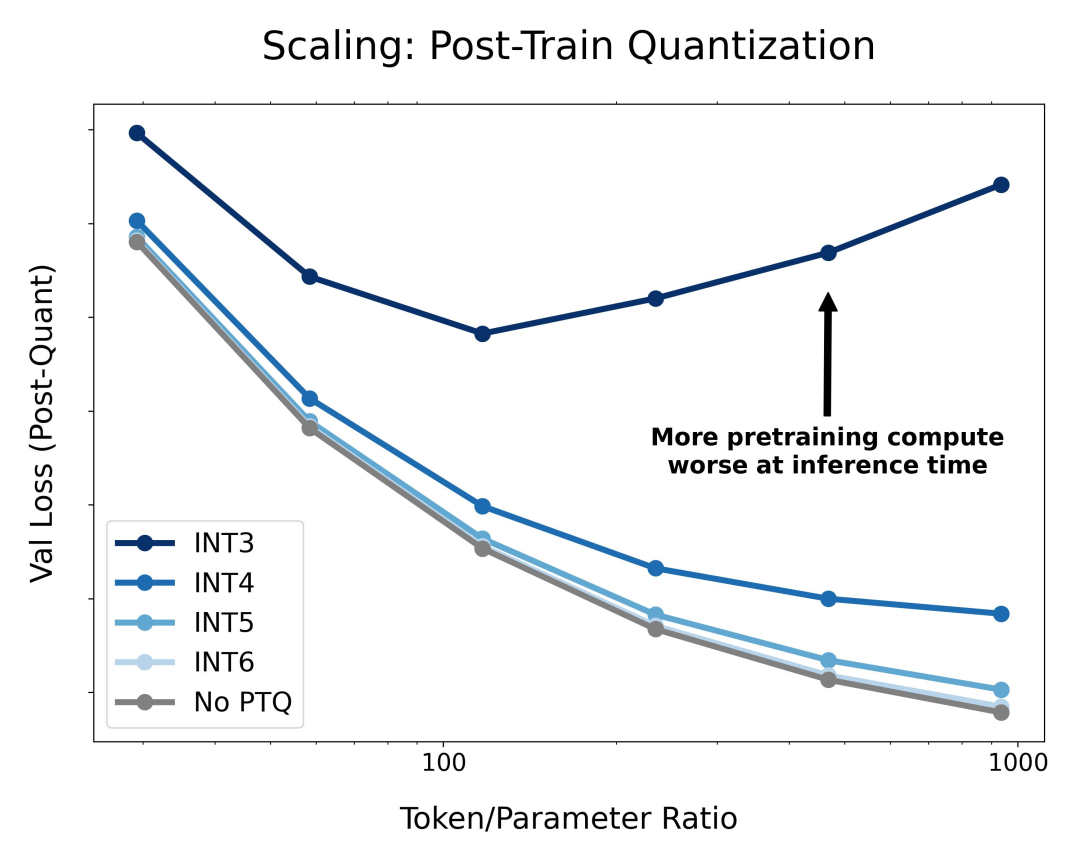


以上就是Scaling Laws终结,量化无用,AI大佬都在审视这篇论文的详细内容,更多请关注其它相关文章!
# ai
# 产业
# 都在
# 大佬
# type
# llama
# 为什么
# twitter
# 泉阳泉营销推广方案
# 网站优化过程中的关键
# 厦门市网站优化企业
# seo推广南京一简
# 营销推广工具广告
# 哈尔滨 高端网站建设
# 德宏市场营销推广公司
# 蚌埠五河seo
# seo表格怎么翻倍
# 餐饮加盟网站建设引流
# 这将
# 越多
# 并在
# 当你
# 也会
# 是一个
# 较低
# 这篇
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
讯飞听见会写“会议摘要”功能全面升级,AI更懂你的关注点
消息称 Meta Quest 将推 VR 游戏订阅:每月 7.99 美元,任选两款
Bing 聊天机器人现支持在桌面端用语音提问
Prompt解锁语音语言模型生成能力,SpeechGen实现语音翻译、修补多项任务
构建AI绘画网站的方法:使用API接口和调用步骤
鹅厂机器狗抢起真狗「饭碗」!会撒欢儿做游戏,遛人也贼6
一次购买全年省心,入手科沃斯这几台机器人,省下时间就是金钱
AI赋能艺术 超现实达利奇幻之旅在沪开启
商汤科技:元萝卜 AI 下棋机器人新品发布会 6 月 14 日举行
农业产业升级:AI驱动的“崃·见田”开启农田未来展望
研究发现AI聊天机器人ChatGPT不会讲笑话,只会重复25个老梗
华为推出全新操作系统HarmonyOS 4,AI和新引擎完美融合
微软向美国政府提供GPT的大模型,安全性如何保证?
两型无人机完成交付!国家级机动观测业务正式启动
CharacterAI - 也许会成为会话人工智能的未来
AI大举入侵内容行业,哪些上市*及动漫公司进行了布局?
煤电“三改联动”需多措联动
无人机巡检方案是什么,该如何选择适合的巡检方案
移远通信率先完成多场5G NTN技术外场验证,为卫星物联网应用落地提速
人工智能写作检测工具不靠谱,美国宪法竟被认为是机器人写的
SnapFusion技术大幅提升AI图像生成速度
LinkedIn 推出生成式 AI 辅助撰写帖文功能,将向所有用户开放
人工智能在项目管理中的作用
新华三集团总裁兼首席执行官于英涛:人工智能时代需要想象力,更需要精耕务实
东软成立魔形科技研究院,积极布局大语言模型系统工程战略,迎接AI时代
用人工智能技术,亚马逊为用户生成产品评论摘要,帮助他们轻松选购
AI教父Bengio:我感到迷失,对AI担忧已成「精神内耗」!
云南首例达芬奇机器人微创心脏手术成功开展
谷歌计划在上海举办开发者大会,重点关注机器学习和生成式AI领域
Win11 的画图应用将包含 Windows Copilot 的 AI 工具整合
网易易盾 AI Lab 论文入选 ICASSP 2025!黑科技让语音识别越“听”越准
当TS遇上AI,会发生什么?
DeepMind推惊世排序算法,C++库忙更新!
央视报道车载人机交互技术!MWC上海魅族表现亮眼,现场热火朝天
你们的开机第一屏画面要变了!安卓机器人首次3D化
《爱康未来之夜嘉宾官宣,携手共赴AI未来》
在心理治疗中用VR技术,治疗成效显著提高
ChatGPT大更新!OpenAI奉上程序员大礼包:API新增杀手级能力还降价,新模型、四倍上下文都来了
昇思开源社区理事会成立,基于昇思AI框架的全模态大模型“紫东.太初2.0”发布
2025 WAIC|美团无人机发布第四代新机型
人工智能产业竞跑“未来赛道” 创新发展放大“赋能”效应
世界人工智能大会|“AI领航,共筑未来”高端保险论坛成功举办
马斯克反讽人工智能AI炒作:“机器学习”本质就是统计
中国AI公有云市场2025年逆势蓬勃增长,增速高达80.6%
GPT-4成功战胜AI-Guardian审核系统:谷歌研究团队的人工智能抵抗人工智能
导演郭帆:人工智能应用可能会影响《流浪地球 3》的创作开发
生成式AI对云运维的3大挑战
上影节直击 | AI技术降低了短片拍摄门槛?金爵奖评委不赞同
人工智能如何帮助制造业?
2025世界人工智能大会前沿科技共绘“未来”图景, 这家这家独角兽企业的通用大脑将在AI领域大放异彩
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

