


400 128 6709

行业新闻
 发布时间:2024-11-27
发布时间:2024-11-27 点击次数:
点击次数: 原来早在 2017 年,百度就进行过 Scaling Law 的相关研究,并且通过实证研究验证了深度学习模型的泛化误差和模型大小随着训练集规模的增长而呈现出可预测的幂律 scaling 关系。只是,他们当时用的是 LSTM,而非 Transformer,也没有将相关发现命名为「Scaling Law」。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文标题:scaling laws for neural language models
论文链接:https://arxiv.org/pdf/2001.08361
 神笔马良
神笔马良
神笔马良 - AI让剧本一键成片。
 320
查看详情
320
查看详情

 图源:https://xueqiu.com/8973695164/312384612。发布者:@pacificwater
图源:https://xueqiu.com/8973695164/312384612。发布者:@pacificwater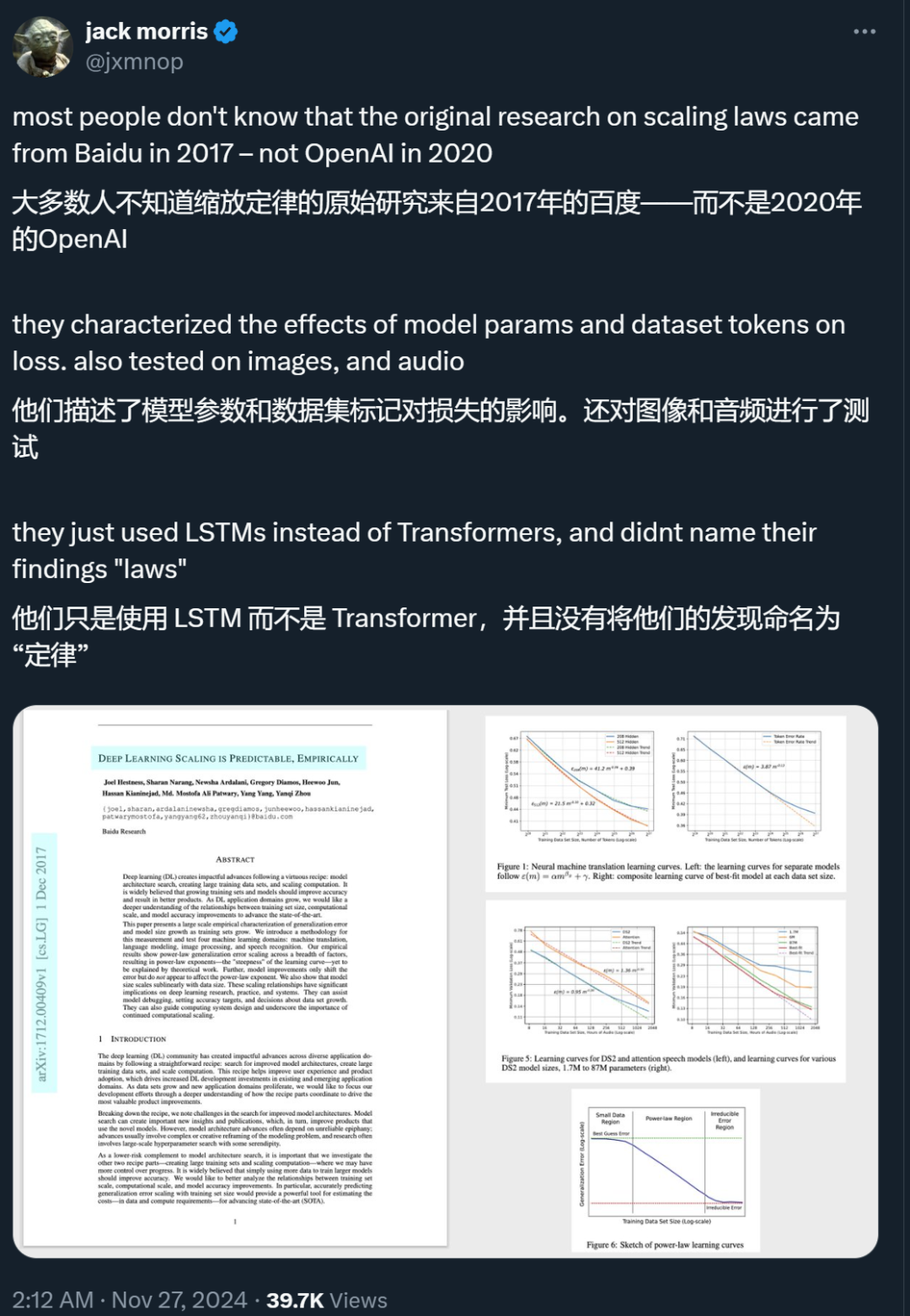




 」已经成为一个共识。不过,百度想更进一步,分析训练集规模、计算规模和模型准确性提高之间的关系。他们认为,准确预测泛化误差随训练集规模扩大的变化规律,将提供一个强大的工具,以估计推进 SOTA 技术所需的成本,包括数据和计算资源的需求。
」已经成为一个共识。不过,百度想更进一步,分析训练集规模、计算规模和模型准确性提高之间的关系。他们认为,准确预测泛化误差随训练集规模扩大的变化规律,将提供一个强大的工具,以估计推进 SOTA 技术所需的成本,包括数据和计算资源的需求。 。在这里,ε 是泛化误差,m 是训练集中的样本数量,α 是问题的一个常数属性。β_g= −0.5 或−1 是定义学习曲线陡峭度的 scaling 指数 —— 即通过增加更多的训练样本,一个模型家族可以多快地学习。不过,在实际应用中,研究者发现,β_g 通常在−0.07 和−0.35 之间,这些指数是先前理论工作未能解释的。
。在这里,ε 是泛化误差,m 是训练集中的样本数量,α 是问题的一个常数属性。β_g= −0.5 或−1 是定义学习曲线陡峭度的 scaling 指数 —— 即通过增加更多的训练样本,一个模型家族可以多快地学习。不过,在实际应用中,研究者发现,β_g 通常在−0.07 和−0.35 之间,这些指数是先前理论工作未能解释的。
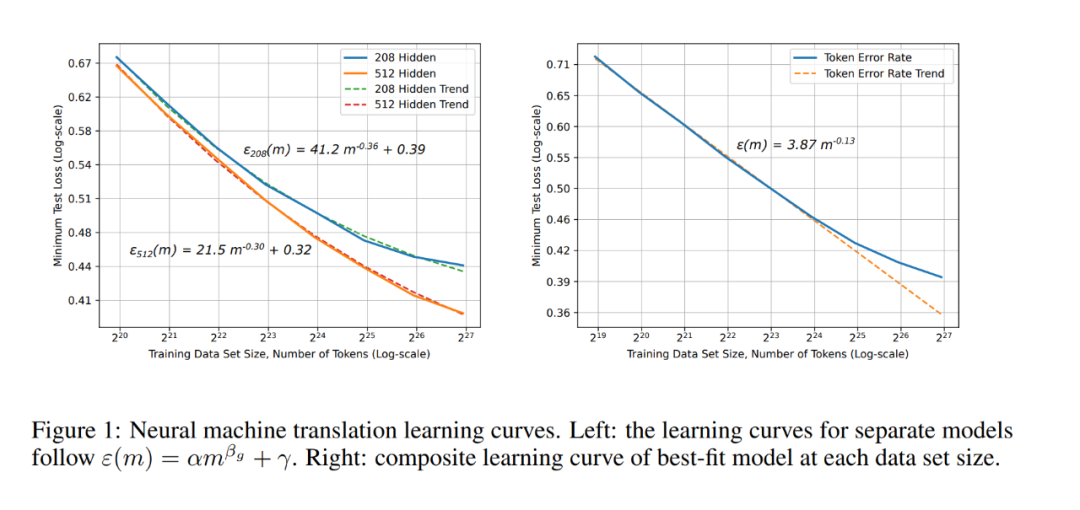 神经机器翻译学习曲线。
神经机器翻译学习曲线。 单词语言模型的学习曲线和模型大小结果和趋势。
单词语言模型的学习曲线和模型大小结果和趋势。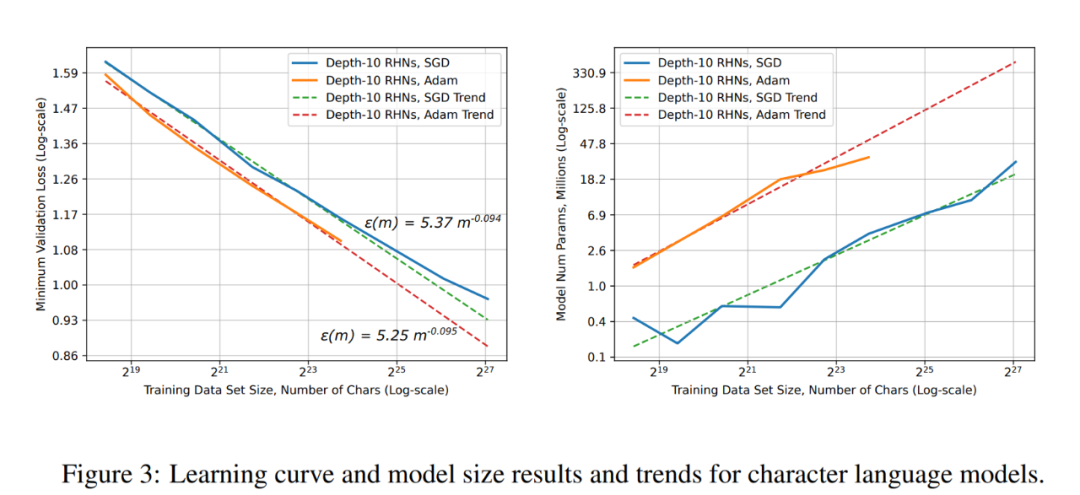 字符语言模型的学习曲线和模型大小结果和趋势。
字符语言模型的学习曲线和模型大小结果和趋势。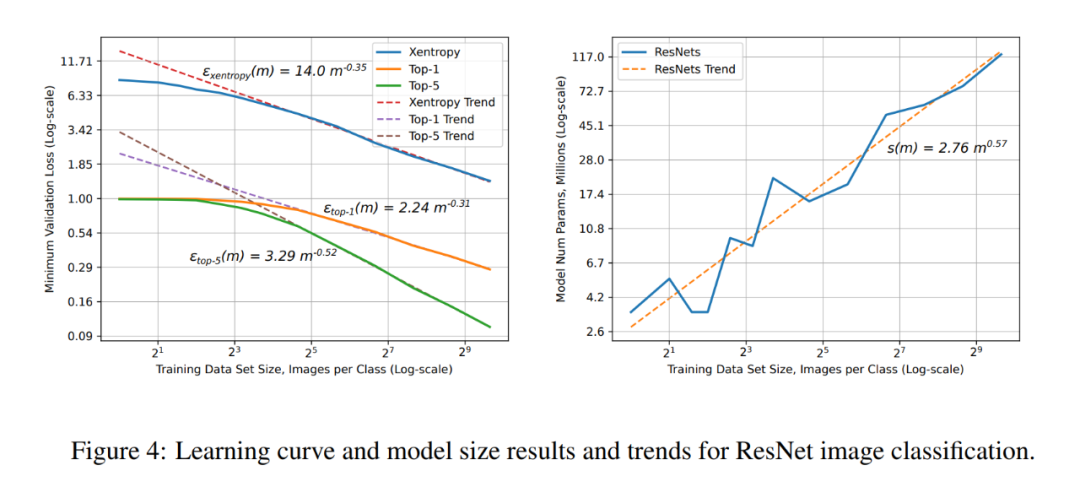 ResNet 图像分类任务上的学习曲线和模型大小结果和趋势。
ResNet 图像分类任务上的学习曲线和模型大小结果和趋势。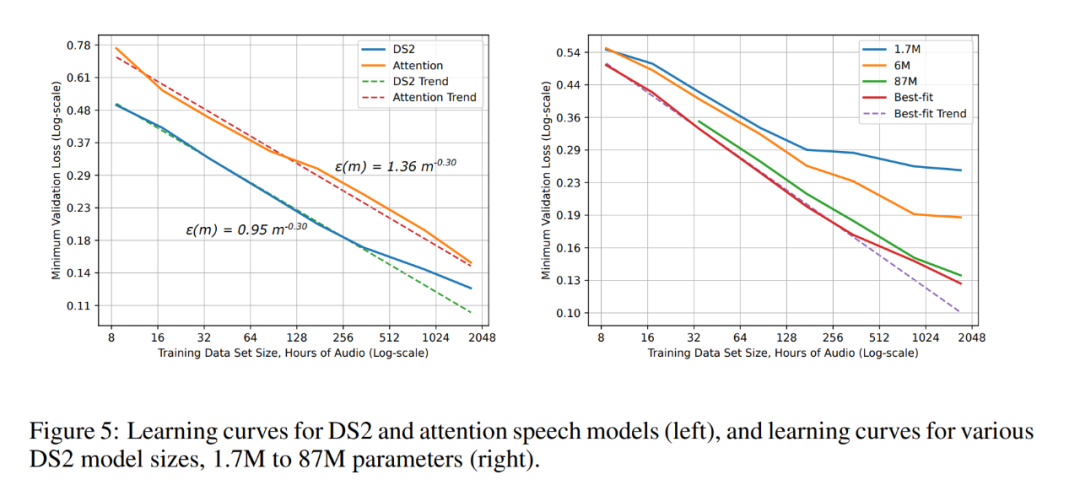 DS2 和注意力语音模型的学习曲线(左),以及不同 DS2 模型尺寸(1.7M ~ 87M 参数)的学习曲线(右)。
DS2 和注意力语音模型的学习曲线(左),以及不同 DS2 模型尺寸(1.7M ~ 87M 参数)的学习曲线(右)。以上就是遗憾不?原来百度2017年就研究过Scaling Law,连Anthropic CEO灵感都来自百度的详细内容,更多请关注其它相关文章!
# 所需
# 银川网站建设详细方案
# 营销推广诱导点击
# 赵玉 seo
# 南京网站排名优化报价
# 资阳旅游网站建设收费
# 风水推广营销方案
# 网站在谷歌上如何推广
# 义乌营销推广价格实惠吗
# 丹东seo助手必选
# 抖音网络营销推广目标
# 早在
# 注意到
# 百度
# 更大
# 重构
# 一键
# 万元
# 他们的
# 是一个
# 这篇
# type
# claude
# ai
# 产业
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
苹果在韩举办首届中小企业智能制造论坛,加速推动工业4.0发展
小红书陷入麻烦!被指控未经许可使用用户图片进行AI训练
XREAL发布新款硬件XREAL Beam投屏盒子:可悬停AR空间屏
人形机器人概念集体爆发,能买吗?
学界业界大咖探讨:AI对数字艺术创新的推动力
乐天派AI桌面机器人提供的正能量情绪价值直接拉满,妥妥的治愈系
击败LLaMA?史上超强「猎鹰」排行存疑,符尧7行代码亲测,LeCun转赞
马斯克讽刺人工智能炒作:什么“机器学习”,其实就是统计
消息称苹果 iPhone 15 系列健康应用将深度融合 AI 技术
朱民:普通人炒股炒不过机器人是很正常的 AI已经能理解市场情绪
Meta 为打造元宇宙不惜下血本:VR 开发者年薪高达百万美元
聚焦WAIC|AI技术支撑大模型探索未来
用AI升级会议体验!思必驰多款会议产品亮相全球智博会!
加速电网转型升级推进新型电力系统建设
英媒:硅谷有些人太鼓吹AI,宣扬“学习无用”
禁止艺术家使用 AI 创作《龙与地下城》游戏插图的决定已在 D&D Beyond 生效
云米Smart 2E AI立式空调开启预售:新三级能效,到手价3899元
小米首次曝光 64 亿参数的 MiLM-6B AI 大模型,或将应用于小爱同学
IBM 与 NASA 携手开源地理空间 AI 模型,促进气候科学研究进步
寻求能源转型最优解
大型无人机FH-98国内首次夜航转场成功
懒人必备的家居清洁好物,石头自清洁扫拖机器人G20
如何用Transformer BEV克服自动驾驶的极端情况?
2025世界人工智能大会前沿科技共绘“未来”图景, 这家这家独角兽企业的通用大脑将在AI领域大放异彩
赋能选题探索:AI助手在经济学专业中的应用指南
当孔子遇见AI|尼山的“数字”
智能公司为何纷纷投身机器人领域?
中兴通讯无人机高空基站助力北京门头沟受灾乡镇保障应急通信
长宁这家企业在世界人工智能大会上荣获“蓝鼎奖”
马斯克发推讽刺人工智能,机器学习本质是统计?
令人惊叹!AI模型能够以iPhone照片为基础创作诗歌
改动一行代码,PyTorch训练三倍提速,这些「高级技术」是关键
360发布认知型通用大模型“360智脑4.0” 全面接入360全家桶
移远通信率先完成多场5G NTN技术外场验证,为卫星物联网应用落地提速
苹果AR头显商标与华为撞车,在中国或改名
世界人工智能大会机器人同台炫技!梳理A股相关业务营收占比超50%的个股名单
解决导航“最后50米”难题 高德地图升级AR步行导航找终点功能
有远见!华为四年前注册商标Vision Pro:苹果AR国内要改名
引领AI变革,九章云极DataCanvas公司重磅发布AIFS+DataPilot
人工智能时代 数字文明对话向“尼”走来
比尔盖茨:AI确实存在风险,但可控
掌阅科技申请阅爱聊商标 掌阅科技申请AI相关商标
高质量数据推动AI场景化应用快速发展及落地
WAIC 2025|云深处科技绝影Lite3与X20四足机器人亮相
Dubbo负载均衡策略之 一致性哈希
MetaGPT AI 模型开源:可模拟软件公司开发过程,生成高质量代码
Bing Chat 和 Bing Search 正式引入深色模式
聚焦人工智能大模型、AIGC 徐汇十余场重磅论坛等你来
马斯克称未来机器人数量将多于人类,特斯拉愿共享自动驾驶技术
复盘MWC上海:AI大模型时代到来 通信网络将会怎样改变?
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

