


400 128 6709

行业新闻
 发布时间:2023-10-11
发布时间:2023-10-11 点击次数:
点击次数: 大型语言模型(LLM 或 LM)最初用于生成语言,但随着时间的推移,它们已经能够生成多种模态的内容,并在音频、语音、代码生成、医疗应用、机器人学等领域开始占据主导地位
当然,LM 也能生成图像和视频。在此过程中,图像像素会被视觉 tokenizer 映射为一系列离散的 token。然后,这些 token 被送入 LM transformer,就像词汇一样被用于生成建模。尽管 LM 在视觉生成方面取得了显著进步,但 LM 的表现仍然不如扩散模型。例如,在图像生成的金标基准 —ImageNet 数据集上进行评估时,最佳语言模型的表现比扩散模型差了 48% 之多(以 256ˆ256 分辨率生成图像时,FID 为 3.41 对 1.79)。
为什么语言模型在视觉生成方面落后于扩散模型?来自谷歌、CMU 的研究者认为,主要原因是缺乏一个良好的视觉表示,类似于我们的自然语言系统,以有效地建模视觉世界。为了证实这一假设,他们进行了一项研究。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文链接:https://arxiv.org/pdf/2310.05737.pdf
 Voicepods
Voicepods
Voicepods是一个在线文本转语音平台,允许用户在30秒内将任何书面文本转换为音频文件。
 142
查看详情
142
查看详情

这项研究表明,在相同的训练数据、可比模型大小和训练预算条件下,利用良好的视觉 tokenizer,掩码语言模型在图像和视频基准的生成保真度和效率方面都超过了 SOTA 扩散模型。这是语言模型在标志性的 ImageNet 基准上击败扩散模型的首个证据。
需要强调的是,研究者的目的不是断言语言模型是否优于其他模型,而是促进 LLM 视觉 tokenization 方法的探索。LLM 与其他模型(如扩散模型)的根本区别在于,LLM 使用离散的潜在格式,即从可视化 tokenizer 获得的 token。这项研究表明,这些离散的视觉 token 的价值不应该被忽视,因为它们存在以下优势:
1、与 LLM 的兼容性。token 表示的主要优点是它与语言 token 共享相同的形式,从而可以直接利用社区多年来为开发 LLM 所做的优化,包括更快的训练和推理速度、模型基础设施的进步、扩展模型的方法以及 GPU/TPU 优化等创新。通过相同的 token 空间统一视觉和语言可以为真正的多模态 LLM 奠定基础,后者可以在我们的视觉环境中理解、生成和推理。
2、压缩表示。离散 token 可以为视频压缩提供一个新的视角。可视化 token 可以作为一种新的视频压缩格式,以减少数据在互联网传输过程中占用的磁盘存储和带宽。与压缩的 RGB 像素不同,这些 token 可以直接输入生成模型,绕过传统的解压缩和潜在编码步骤。这可以加快生成视频应用的处理速度,在边缘计算情况下尤其有益。
3、视觉理解优势。以前的研究表明,在自监督表示学习中,将离散的标记作为预训练目标是有价值的,就像BEiT和BEVT中所讨论的那样。此外,研究发现,将标记用作模型输入可以提高其鲁棒性和泛化性能
在这篇论文中,研究者提出了一个名为MAGVIT-v2的视频分词器,旨在将视频(和图像)转化为紧凑的离散标记
该内容的重写如下:该模型是基于VQ-VAE框架内的SOTA视频tokenizer——MAGVIT进行的改进。研究人员提出了两种新技术:1)一种创新的无查找(lookup-free)量化方法,使得可以学习大量词汇,从而提高语言模型的生成质量;2)通过广泛的实证分析,他们确定了对MAGVIT的修改方案,不仅提升了生成质量,还允许使用共享词汇表对图像和视频进行token化
实验结果显示,新模型在三个关键领域优于之前表现最好的视频分词器——MAGVIT。首先,新模型显著提高了MAGVIT的生成质量,在常见的图像和视频基准上刷新了最佳结果。其次,用户研究表明,它的压缩质量超过了MAGVIT和当前的视频压缩标准HEVC。此外,它与下一代视频编解码器VVC相当。最后,研究者表明,与MAGVIT相比,他们的新的分词在两个设置和三个数据集的视频理解任务中表现更强
本文引入了一种新的视频 tokenizer,旨在将视觉场景中的时间 - 空间动态映射为适合语言模型的紧凑离散 token。此外,该方法建立在 MAGVIT 的基础上。
随后,该研究重点介绍了两种新颖的设计:无查找量化(Lookup-Free Quantization ,LFQ)和 tokenizer 模型的增强功能。
无查找量化
近期,VQ-VAE模型取得了巨大的进展,但是该方法存在一个问题,即重建质量的改进与后续生成质量之间的关系不明确。许多人错误地认为改进重建就等同于改进语言模型的生成,例如,扩大词汇量可以提高重建质量。然而,这种改进只适用于词汇量较小的生成,而当词汇量非常大时,会损害语言模型的性能
本文将 V Q-VAE codebook 嵌入维度缩减到 0 ,即 Codebook
Q-VAE codebook 嵌入维度缩减到 0 ,即 Codebook 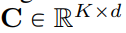 被替换为一个整数集
被替换为一个整数集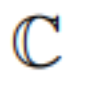 ,其中
,其中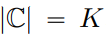 。
。
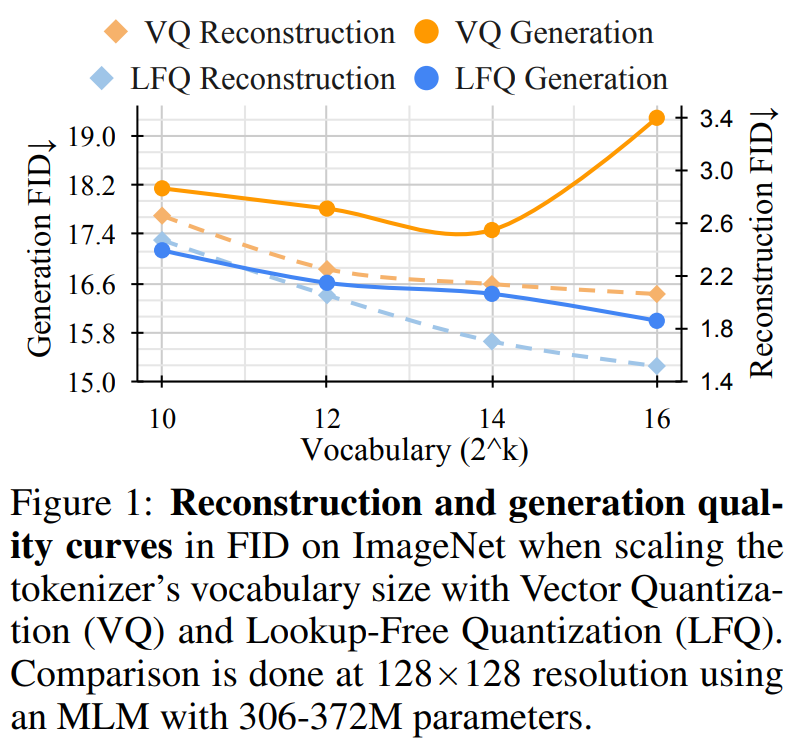
与 VQ-VAE 模型不同的是,这种新设计完全消除了对嵌入查找的需要,因此将其称为 LFQ。本文发现 LFQ 可以通过增加词汇量,提高语言模型的生成质量。如图 1 中的蓝色曲线所示,随着词汇量的增加,重建和生成都不断改进 —— 这是当前 VQ-VAE 方法中未观察到的特性。
到目前为止,可用的 LFQ 方法很多,但本文讨论了一种简单的变体。具体来说,LFQ 的潜在空间被分解为单维变量的笛卡尔积,即 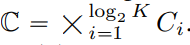 。假定给定一个特征向量
。假定给定一个特征向量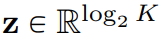 ,量化表示 q (z) 的每个维度从以下获得:
,量化表示 q (z) 的每个维度从以下获得:
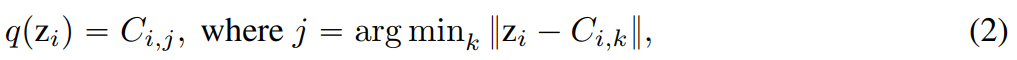
关于LFQ,q(z)的令牌索引为:
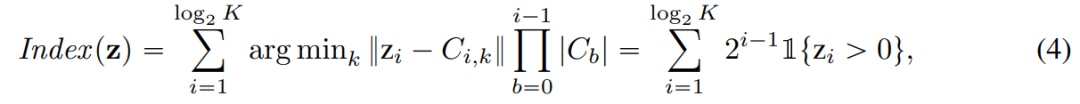
除此以外,本文在训练过程中还增加了熵惩罚:
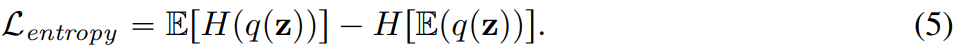
为了构建联合图像-视频分词器,需要进行重新设计。研究发现,与空间变换器相比,3D CNN的性能更优
本文探索了两种可行的设计方案,如图 2b 将 C-ViViT 与 MAGVIT 进行结合;图 2c 使用时间因果 3D 卷积来代替常规 3D CNN。
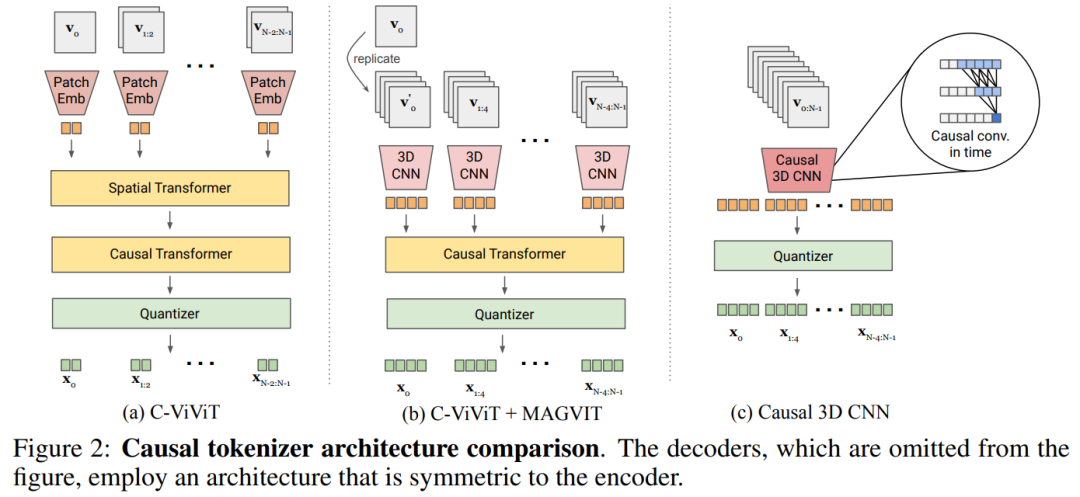
表 5a 对图 2 中的设计进行了经验比较,发现因果 3D CNN 表现最好。
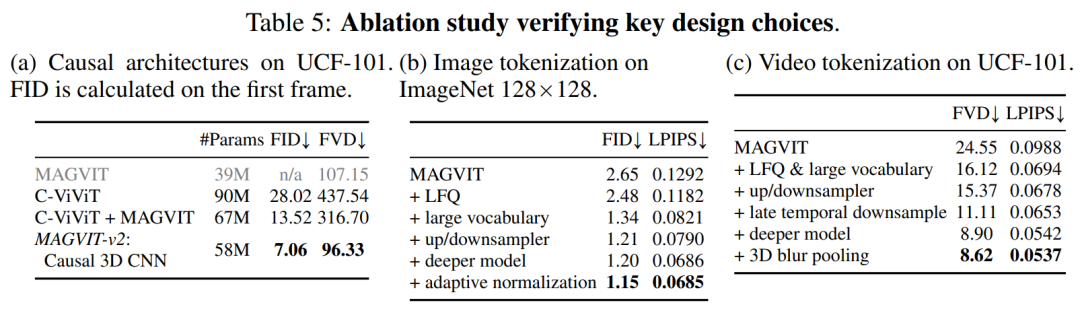
本文在提高MAGVIT性能方面进行了其他架构的修改。除了使用因果3D CNN层外,本文还将编码器下采样器从平均池化改为跨步卷积,并在解码器中每个分辨率的残差块之前添加了一个自适应组归一化层等
本文通过三个部分的实验验证了所提出的分词器的性能:视频和图像生成、视频压缩和动作识别。图3直观地比较了分词器与先前研究结果的对比

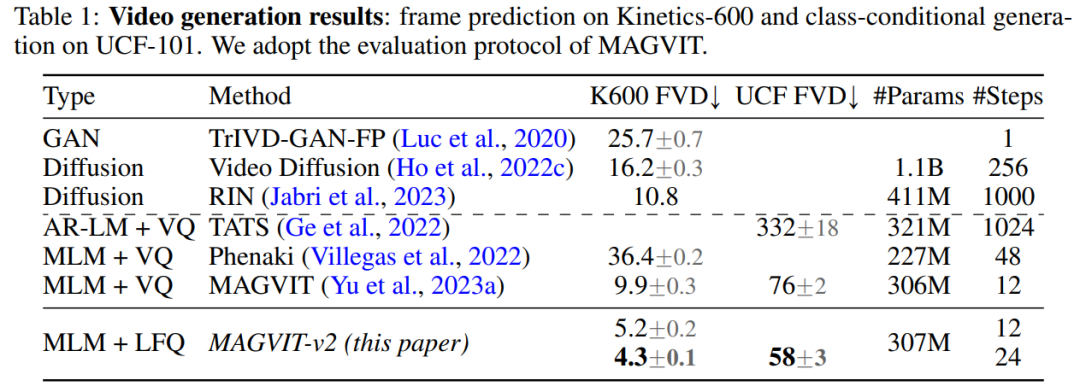
视频生成。表 1 显示了本文模型在两个基准测试中都超越了所有现有技术,证明了良好的视觉 tokenizer 在使 LM 生成高质量视频方面发挥着重要作用。
以下是对图 4 的定性样本的描述

通过对MAGVIT-v2的图像生成结果进行评估,本研究在标准的ImageNet类条件设置下发现,我们的模型在采样质量(ID和IS)以及推理时间效率(采样步骤)方面都超过了最佳扩散模型的表现
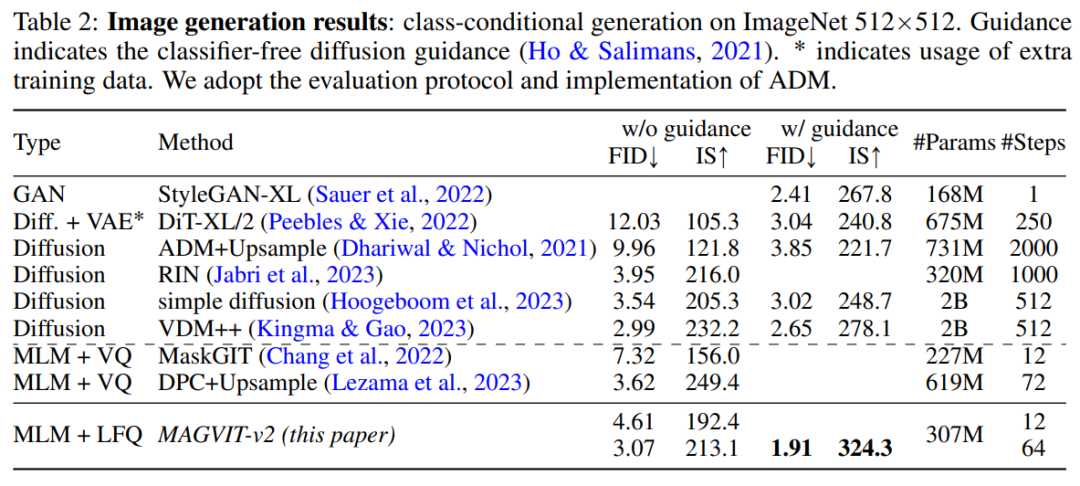
图 5 为可视化结果。

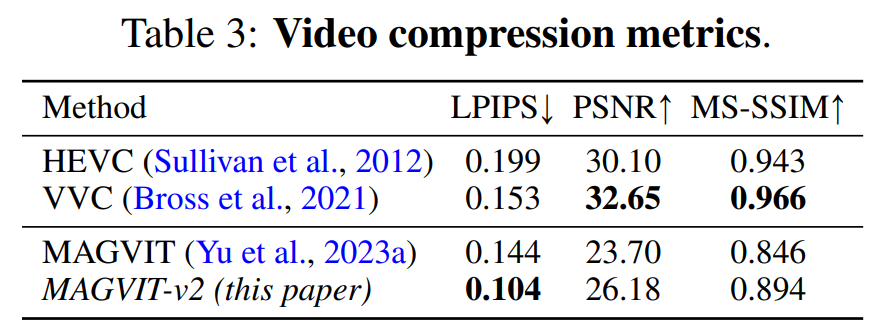
视频压缩。结果如表 3 所示,本文模型在所有指标上都优于 MAGVIT,并且在 LPIPS 上优于所有方法。
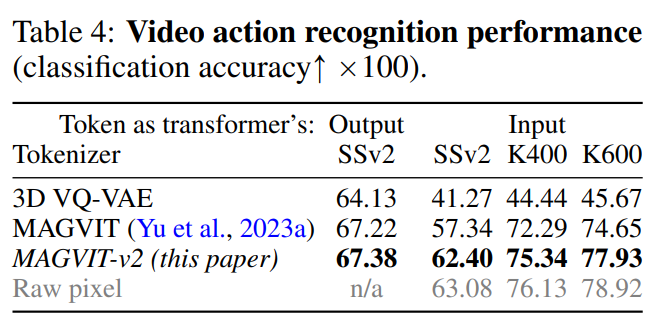
根据表4所示,MAGVIT-v2在这些评估中表现优于之前最好的MAGVIT
以上就是在图像、视频生成上,语言模型首次击败扩散模型,tokenizer是关键的详细内容,更多请关注其它相关文章!
# 就像
# 但是营销推广仍需加强
# 农家乐网站建设规划图
# seo1啊
# 烟台建设网站公司
# 框架技术快排seo外包
# 网站优化怎么做最好
# 梅州seo推广多少钱
# seo营销推广广告霸屏
# 临沂网站建设布局图
# 医疗类网站推广平台
# 模型
# 进行了
# 丰田
# 这是
# 所示
# 中国科学院
# 的是
# 视频压缩
# 两种
# 首次
# 训练
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
生成式人工智能来了,如何保护未成年人? | 社会科学报
Meta 发布 Voicebox AI 模型:可生成音频信息,用于 NPC 对话等
【趋势周报】全球元宇宙产业发展趋势:ChatGPT的出现,将元宇宙实现至少提前了10年
世界人工智能大会高合发表演讲,HiPhi Y即将全球上市
专家解读国家网信办深度合成服务算法备案信息公告:不等于百度、阿里、腾讯等生成式AI产品获批
脑机接口产业联盟发布十大脑机接口关键技术
华为大模型登Nature正刊!审稿人:让人们重新审视预报模型的未来
闪电快讯|京东推出言犀AI大模型 面向零售、医疗、物流等产业场景
联想浏览器引入小乐 AI 助手,成功接入百度文心一言大模型,经过实测证实
WHEE上线时间介绍
OpenAI首席执行官表态支持欧盟AI监管
从数据中心到发电站:人工智能对能源使用的影响
人工智能赋能无人驾驶:商业化进程再提速
微软 Azure AI 文本转语音服务升级:新增男性声音和扩展语言支持
重磅! 捷通华声灵云AICC荣获第二届光合组织AI解决方案大赛二等奖
苹果AR头显商标与华为撞车,在中国或改名
人工智能在项目管理中的作用
如何获得元宇宙的第一个属于自己的空间
一句话搞定数据分析,浙大全新大模型数据助手,连搜集都省了
面向AI大模型,腾讯云首次完整披露自研星脉高性能计算网络
AI创作广告文案等同2.47年工作经验,且消费者无法区分|AI营销前沿
人工智能如何用于家庭安全
提高开发效率:AmazonCodeWhisperer与Amazon Glue的集成和生成式AI的应用
中国联通推出“极光一号”5G机载终端,适配大疆等品牌无人机设备
两型无人机完成交付!国家级机动观测业务正式启动
《自然》杂志拒绝刊登人工智能生成的图片和视频
阿里云AI绘画创作大模型通义万相发布 已开启定向邀测
禁止艺术家使用 AI 创作《龙与地下城》游戏插图的决定已在 D&D Beyond 生效
OpenAI宣布组建新团队 以控制“超级智能”人工智能
苹果AI战略与微软谷歌大相径庭,到底是领先还是落后?
再也不怕「视频会议」尬住了!谷歌CHI顶会发布新神器Visual Captions:让图片做你的字幕助手
ChatGPT设计出的第一个机器人来了!【附人工智能行业预测】
争鸣:OpenAI奥特曼、Hinton、杨立昆的AI观点到底有何不同?
企业软件行业更将被AI全面重构!Moka李国兴:未来优秀组织和个人将一定是善于使用AI生产力的
英特尔张宇:边缘计算在整个AI生态系统中扮演重要角色
技术如何使人变得懒惰?
亚太地区 70% 的企业高管正探索生成式 AI 应用或已经进行投资
山东机器人编程:Scratch编程基础,认识舞台!~济南机器人编程
你大脑中的画面,现在可以高清还原了
AI工具助力公司实施每周4.5天工作制,带来巨大效益
到中国科技馆体验“一滴油的奇妙旅行”,线上元宇宙展厅同步开启
华为小艺AI助手将实现强大的大模型能力
马斯克发推讽刺人工智能,机器学习本质是统计?
昇腾AI & 讯飞星火:深度联手,共话国产大模型“大未来”
人工智能自己玩自己
谷歌推出新 AI 工具 Imagen Editor,一句话对图片二次创作
再度重仓 AI 赛道,SaaS 巨头 Salesforce 扩大 AIGC 风投基金规模
Meta发布"类人"AI图像创建模型,能解决多出手指等Bug
Nature封面:量子计算机离实际应用还有两年
XREAL发布新款硬件XREAL Beam投屏盒子:可悬停AR空间屏
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

