


400 128 6709

行业新闻
 发布时间:2025-01-05
发布时间:2025-01-05 点击次数:
点击次数: ☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。
投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文来自腾讯 AI Lab,介绍了一套针对于低比特量化的 scaling laws。

低比特量化(low-bit quantization)和低比特大语言模型(low-bit LLM)近期受到了广泛的关注,因为有一些研究发现,它们能够以更小的模型规模、更低的内存占用和更少的计算资源,取得与 fp16 或 bf16 精度相当的性能表现。这一发现让低比特语言模型一度被认为是实现模型高效化的一个非常有前景的方向。
然而,这一观点受到了腾讯 AI Lab 的挑战。他们的研究发现,低比特量化只有在未充分训练的 LLM(训练量通常在 1000 亿 tokens 以内,基本不会超过 5000 亿 tokens:这种 setting 在当前的学术界研究论文中非常常见)上才能取得与 fp16/bf16 相当的性能表现。随着训练的深入和模型逐渐被充分训练,低比特量化与 fp16/bf16 之间的性能差距会显著扩大。
为了更系统地研究这一现象,研究人员量化了超过 1500 个不同大小以及不同训练程度的开源 LLM 检查点。试图观察并建模量化所导致的性能退化(QiD,quantization-induced degradation,即量化后模型与原始 fp16/bf16 模型的性能差距,记作∆qLoss)
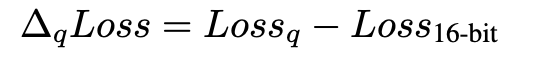
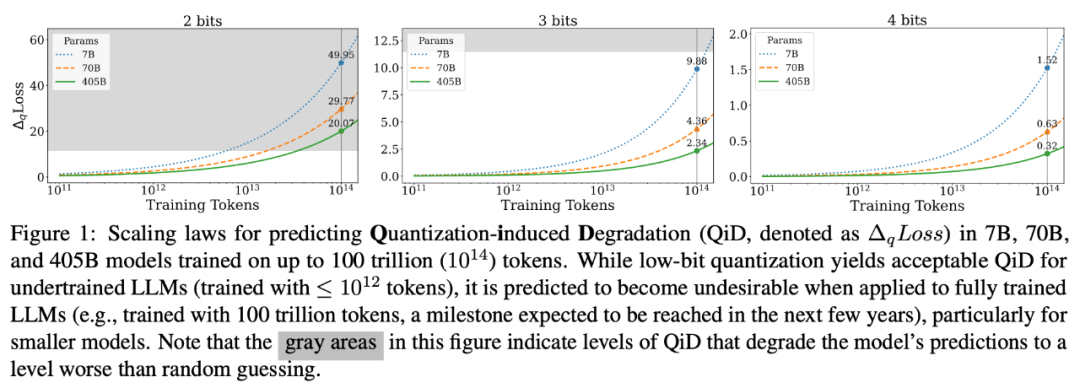
最终推演出了一套针对于低比特量化的 scaling laws。通过这套 scaling laws,可以预测出当 7B, 70B 以及 405B 的模型在训练规模达到 100 万亿 tokens 时低比特量化时损失(如下图)。
根据研究人员的描述,这个工作最初是源于 2 个观察(如下图):a) model size 固定的情况下,training tokens 越多,QiD 就会变得越大;b) training token 数固定的情况下,model size 越小,QiD 就会变得越大。考虑到不管是减小 model size 还是增加 training tokens 都会有利于模型更充分的训练,因此研究人员推测在充分训练的模型上进行低比特量化会造成较为严重的 degradation,反之在未充分训练的模型上则不会有太多 degradation.
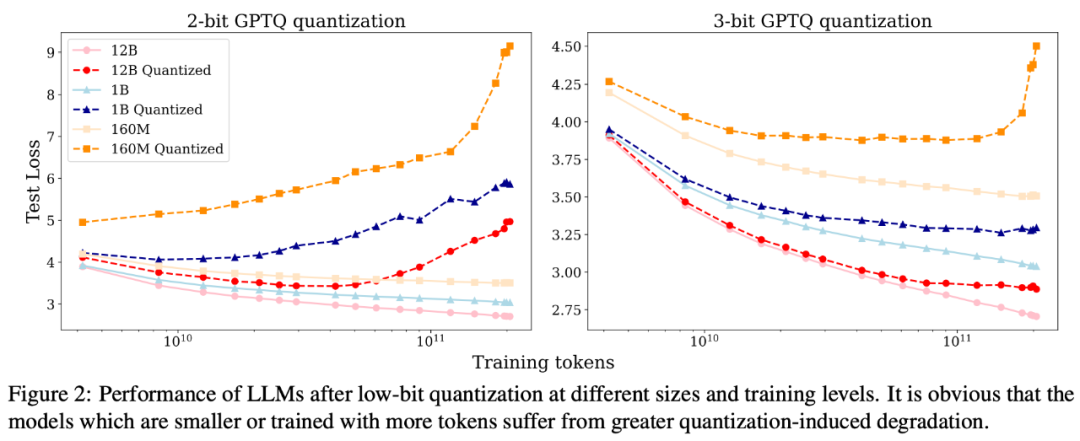
为了更好地验证这一推测,研究人员选择了 Pythia 系列开源语言模型进行实验,因为 Pythia 系列模型不仅公开了不同尺寸的 LLM,而且还开源了其中间训练过程的检查点。研究人员选取了 160M, 410M, 1B, 2.8B, 6.9B 以及 12B 这 6 种不同尺寸的 LLM。对于每种尺寸的 LLM,又选取了其训练过程中间 20 个检查点。对这 120 个检查点,研究人员用 GPTQ 对它们分别进行了 2-bit, 3-bit, 4-bit 量化,来观察在不同检查点上量化所导致的性能退化(即 QiD)。
通过分别对于 training tokens, model size 以及量化比特数分别的建模分析(分别建模的结果这里就不详述了,感兴趣的可以阅读论文),最终得到一个统一的 scaling laws:
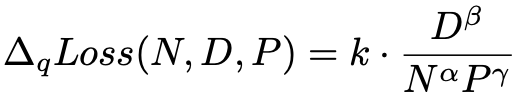
这里 N, D, P 分别表示模型参数量(除掉 embedding 部分),training tokens 数以及精度(比特数)。α, β 和 γ 分别表示它们对应的指数(α, β, γ 均为正数),k 为联合系数。根据这个 scaling law 的公式,我们不难得到当其它变量固定时:
研究人员根据上述函数形式拟合观测到的数据点,得到在 Pythia 系列 LLM 的低比特量化的 scaling law 公式:
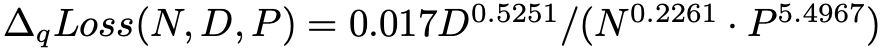
研究人员根据这个公式绘制出曲线,发现能够很好地拟合观测到的数据点:
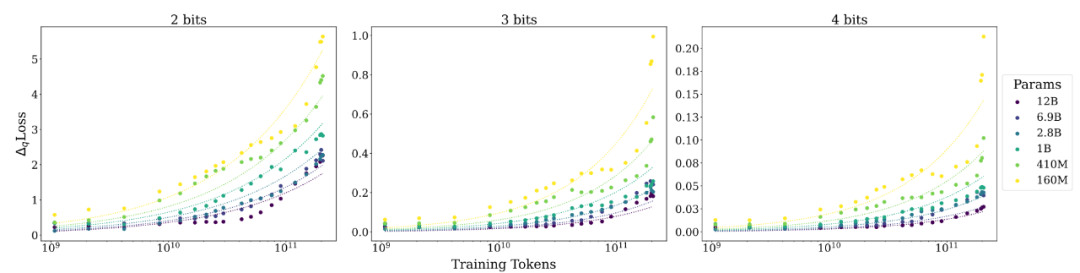
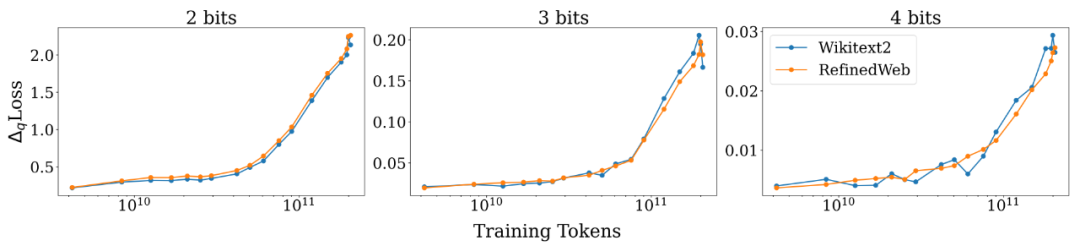
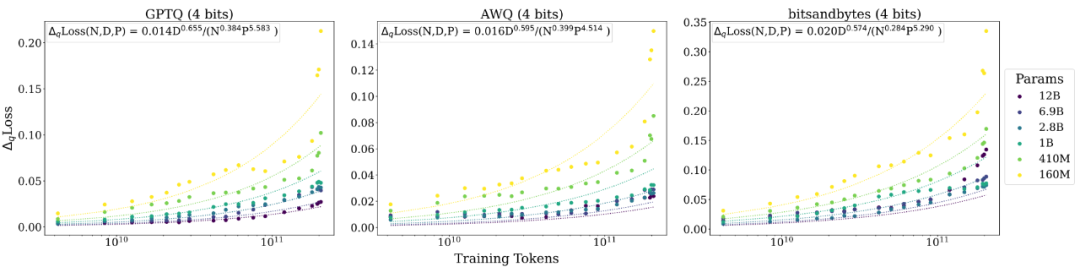
另外,研究人员对不同测试数据,不同量化方法以及不同的基础模型都进行了评测,发现所得到的 scaling laws 的函数形式大概率是普适成立的:
 Tunee AI
Tunee AI
新一代AI音乐智能体
 1104
查看详情
1104
查看详情

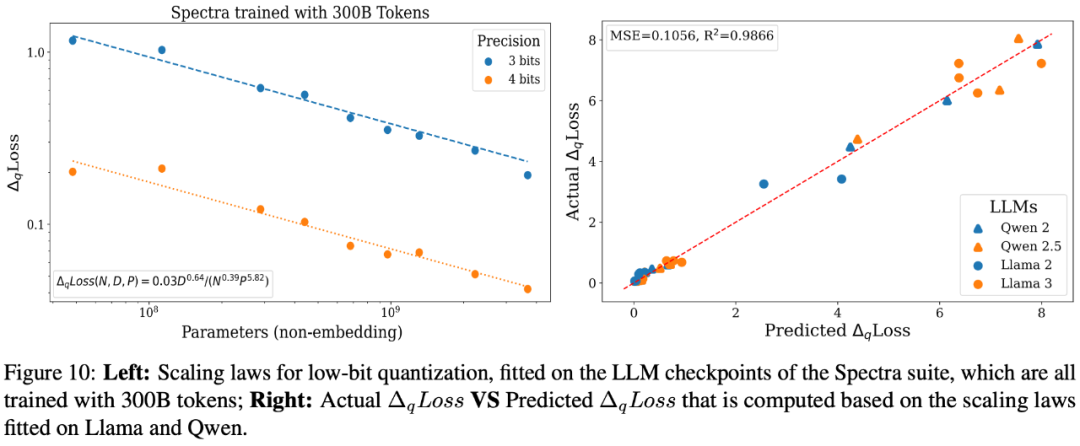
如下图所示,我们现在知道了充分训练的 LLMs 会遭受更大的 QiD,而训练不足的 LLMs 则更容易实现近乎无损的低比特量化。那这个现象是怎么造成的呢?
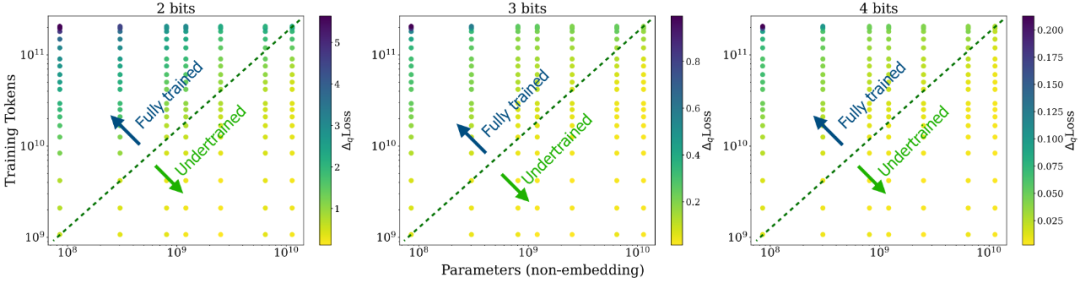
研究人员从训练时权重变化幅度这一角度给出了一些见解:未经充分训练的 LLMs 往往会经历较大幅度的权重变化,在训练过程中的这种大起大落式的变化会让模型对 weight variation 变得更为鲁棒 —— 即便进行了低比特量化,量化所造成的偏离往往也要小于它在训练过程中经历的偏移;而充分训练的 LLM 在训练过程中的权重变化就会非常小了,往往在小数点后几位变化,这个时候模型如果遭度更大幅度的权重变化 (如低比特量化带来的权重变化),就非常容易造成严重的 degradation.
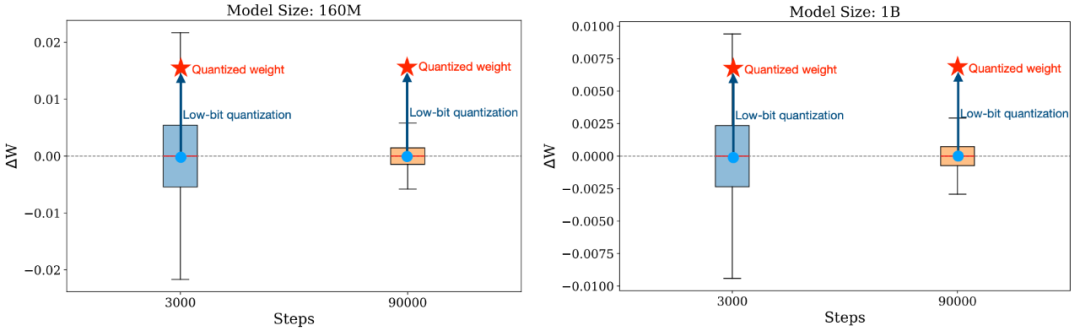
除此之外,研究人员还开创性地将 QiD 视为一个衡量 LLM 是否充分训练的指标。如果低比特量化的 QiD≈0,那说明这个 LLM 还远远没有充分训练,还没有将参数高精度的潜力发挥出来。那么根据前文所得到的 scaling laws,就可以推算出不同尺寸的 LLM 达到指定 QiD 所需要的 training tokens 数,如下表:
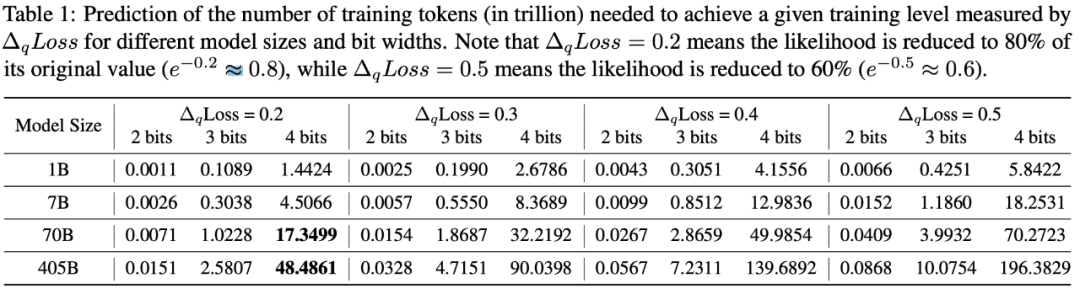
我们以 4-bit 量化造成 QiD=0.2 为例,7B 模型达到这个程度需要近 17.3 万亿 tokens,而 405b 模型则需要将近 50 万亿 tokens. 考虑到近 4 年模型的训练数据量增长了近 50 倍,可以预见未来模型的训练量会更大(例如,未来几年可能会达到 100 万亿 token)。随着模型训练变得更加充分,低比特量化在未来的应用前景则会变得并不明朗。
除此之外,研究人员也对于原生的(native)低比特 LLM(例如BitNet-b1.58)进行了评测,发现其规律与低比特量化近乎一致,但相比于量化,原生的低比特LLM可能会在更后期才会明显暴露这个问题——因为原生的低精度训练能够让模型一直保持在低精度权重下工作的能力。尽管有一些研究声称原生的低比特LLM可以媲美fp16/bf16精度下的表现,但这些研究普遍都是在未充分语言模型上得到的结果从而推出的结论,研究人员认为在充分训练的情况下进行比较的话,低比特LLM也将很难匹敌其在fp16/bf16精度下对应的模型。
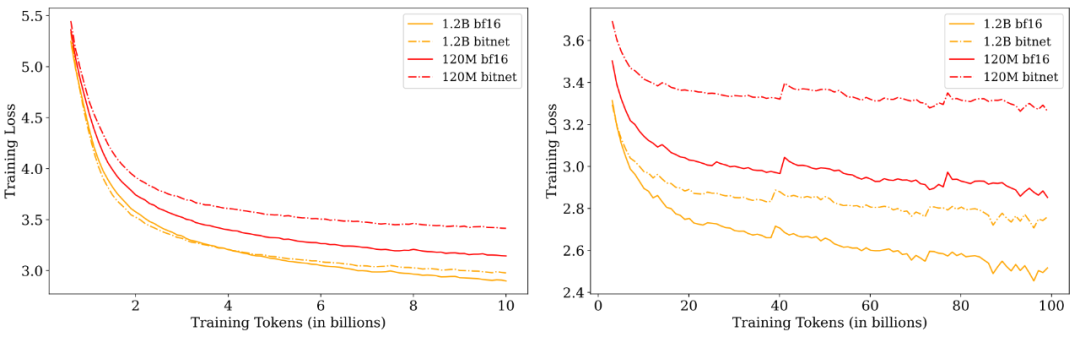
考虑到学术界算力的限制,在未充分训练的 LLM 上进行实验、评测,从而得到一些结论,并试图将这些结论推广为普遍适用,这一现象已经越来越普遍,这也引发了研究人员的担扰,因为在未充分训练的 LLM 上得到的结论并不一定能够普遍适用。研究人员也希望社区能重新审视那些在未充分训练的 LLM 上得到的结论,从而引出更深入的思考与讨论。
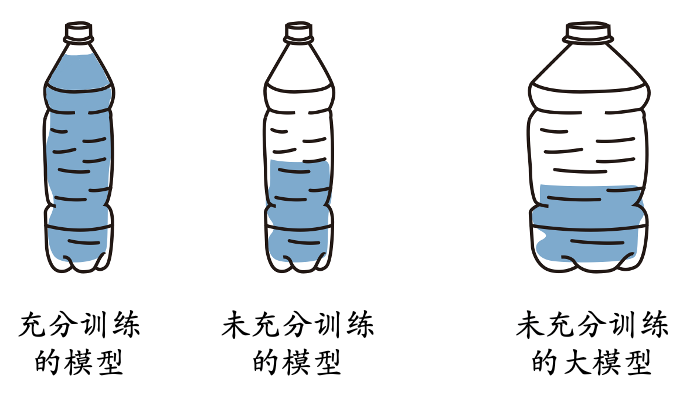
最后的最后,研究人员用了一组插画来形象地概括了一下他们的发现:
1. 如果把模型类比成水瓶,那水瓶里的装水量就可以反映模型的训练充分程度。小模型更容易被装满,大模型则需要更多的水才能装满。
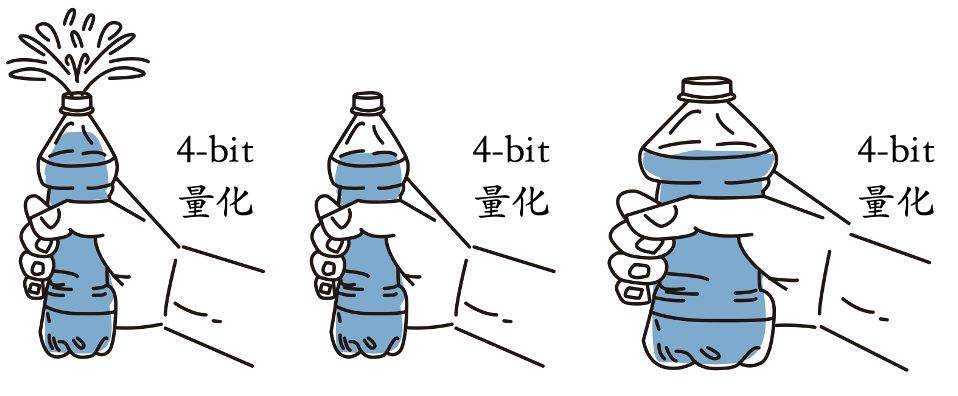
2. 量化就相当于用手去挤压瓶身。对于装满水的瓶子,水会溢出(performance degradation);而没装满水的瓶子则不会有水溢出。
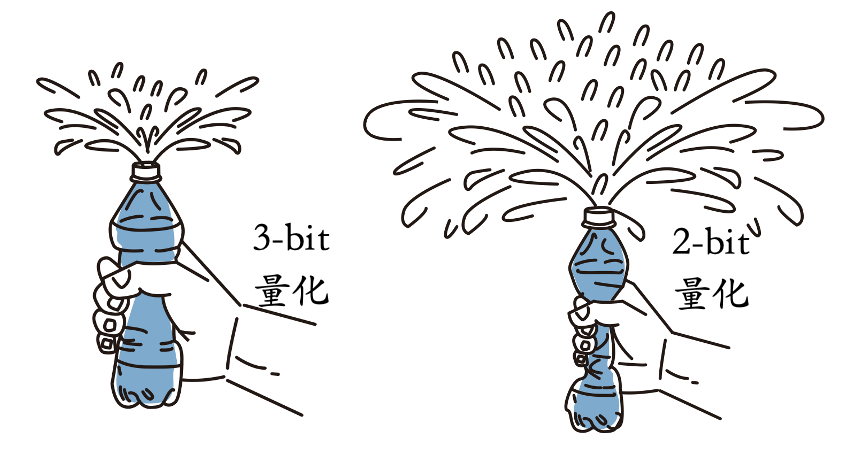
3.量化的精度可以类比成挤压瓶身的力量大小。越低比特的量化挤压得越狠,越容易造成大量的水被挤出(significant degradation)。
以上就是低精度只适用于未充分训练的LLM?腾讯提出LLM量化的scaling laws的详细内容,更多请关注其它相关文章!
# cad
# 更大
# 就会
# 越小
# 腾讯
# 工作流
# 这一
# 越大
# yy
# cos
# 内存占用
# 邮箱
# ai
# qq
# 工程
# type
# 金水区专业网站建设推荐
# 如何找猫砂货源网站推广
# 邯郸专业的网站建设价格
# 企业全网营销推广怎么做
# 当涂seo网站优化公司
# UI素材网站建设海报
# 网站推广开发费用
# 数据营销宝盟如何推广
# 巴中seo公司选9火星
# 上海能源建设集团网站
# 考虑到
# 进行了
# 官网
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
微软 GitHub Copilot 编程助手被投诉:换口吻改写公共代码来躲版权
腾讯企点客服接待与营销分析能力升级!企业操作更高效、人机交互更智能
参考封面|人工智能“淘金热”
日新月异,脑机接口技术都有哪些新应用?
衡水市冀州中学机器人社团在世界机器人大赛中斩获佳绩
大模型新品出现井喷,AI产业迎来新时代
成功孵化首个大型模型解决方案的重庆人工智能创新中心
Snow Kylin登陆中国列车,打造全球首条元宇宙专列
游族AI创新院揭牌成立 推进AI赋能游戏业务
生成式人工智能如何改变云安全的游戏规则
Meta Quest订阅服务每月7.99美元畅玩两款VR游戏应用
一文读懂自动驾驶的激光雷达与视觉融合感知
郭帆:AI发展日新月异,或是弯道超车好莱坞的最好机会
Bing Chat 和 Bing Search 正式引入深色模式
随时随地,追踪每个像素,连遮挡都不怕的「追踪一切」视频算法来了
探索人工智能在居家养老方面的应用
MiracleVision视觉大模型
美图公司影像节或发布AI设计新品
配 3D 机器人头像,谷歌展示全新安卓 LOGO
猿编程参加人工智能高峰论坛,推动人工智能教育解决方案在千所学校推行
站在社会的高度理解人工智能
美图影像节演讲实录:191次提及AI,发布7款影像生产力工具
阿里大文娱CTO郑勇:生成式AI将引发内容行业巨变,*制作机会挑战并存
“世界人工智能之都”的新烦恼:AI热潮无法拉动大量就业
7条线路感受智慧美好生活,“2025 世界人工智能大会民营企业社会开放日”主题活动启动
特斯拉人形机器人将亮相 预计售价不超过15万元
视觉中国推出AI灵感绘图功能,付费后可在“合法合规前提下使用”
脑机接口产业联盟发布十大脑机接口关键技术
全媒封面丨⑤商汤科技:原创AI算法“发电厂”
12页线性代数笔记登GitHub热榜,还获得了Gilbert Strang大神亲笔题词
美版贴吧8000小组自爆停摆!拒绝数据被谷歌OpenAI白嫖,CEO被网友骂翻:背刺第三方应用
AI成政客博弈工具,美国大选真假难辨,律师们的生意来了
世界上第一个完全由人工智能驱动的图像编辑器!
沐曦首款AI推理GPU亮相:INT8算力达160TOPS!
优化系统韧性:故障恢复与监控在RabbitMQ中的应用
30+大模型齐聚,大模型成世界人工智能大会“顶流”
全新“AI助手”!讯飞星火助手中心人机协作共创新生态
卫星通信牵引物联网竞争升维,模组厂商如何决胜百亿市场?
读创正式上线“读创AI聊”功能
Databricks 发布大数据分析平台 Spark 用 AI 模型 SDK:一键生成 SQL 及 FySpark 语言图表代码
【澎湃原动力】人工智能产业协同创新中心:全产业链资源在这里汇聚
阿里云AI绘画创作大模型通义万相发布 已开启定向邀测
AI智能室内效果图设计软件效果,确实惊到我了!
百亿量化私募:量化投资进入“精耕细作”时代 AI带来行业新变革
深度学习模型综述:用于3D MRI和CT扫描的应用
Yann LeCun团队新研究成果:对自监督学习逆向工程,原来聚类是这样实现的
靠游戏更靠AI 英伟达成唯一首季度两位数增长的公司
Midjourney 5.2震撼发布!原画生成3D场景,无限缩放无垠宇宙
网易加速行业AI大模型应用,将覆盖100多个应用场景
全新升级的广州麦当劳:面积最大餐厅正式引入智慧机器人
 当前位置:
当前位置:  投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com 上一篇:
上一篇: 返回列表
返回列表

