


400 128 6709

行业新闻
 发布时间:2025-07-24
发布时间:2025-07-24 点击次数:
点击次数: 本文介绍逻辑回归,这是一种分类算法。它通过Sigmoid函数将线性回归结果映射到[0,1],以概率形式分类。损失函数为对数似然函数,用随机梯度下降或牛顿法优化。其优势在于输出概率、可解释性强等,应用于CTR预估等场景。还展示了自定义函数及调用sklearn的实现代码与结果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

import numpy as npimport matplotlib.pyplot as plt
x = np.arange(-5.0 , 5.0 , 0.02)
y = 1 / (1 + np.exp(-x))
plt.xlabel('x')
plt.ylabel('y = Sigmoid(x)')
plt.title('Sigmoid')
plt.plot(x , y)
plt.show()
<Figure size 432x288 with 1 Axes>
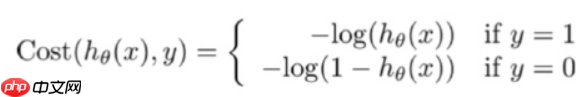
from math import expimport numpy as npimport pandas as pdimport matplotlib.pyplot as plt %matplotlib inlinefrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split
# datadef create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
data = np.array(df.iloc[:100, [0,1,-1]]) # print(data)
return data[:,:2], data[:,-1]
In [3]
X, y = create_data() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)In [8]
import math
class LogisticReressionClassifier:
def __init__(self, max_iter=200, learning_rate=0.02):
self.max_iter = max_iter
self.learning_rate = learning_rate
# sigmoid激活函数
def sigmoid(self, x):
return 1 / (1 + exp(-x)) def data_matrix(self, X):
data_mat = [] for d in X:
data_mat.append([1.0, *d]) return data_mat def fit(self, X, y):
 # label = np.mat(y)
data_mat = self.data_matrix(X) # m*n
self.weights = np.zeros((len(data_mat[0]),1), dtype=np.float32) for iter_ in range(self.max_iter): for i in range(len(X)):
result = self.sigmoid(np.dot(data_mat[i], self.weights))
error = y[i] - result
self.weights += self.learning_rate * error * np.transpose([data_mat[i]]) print('LogisticRegression Model(learning_rate={},max_iter={})'.format(self.learning_rate, self.max_iter)) # def f(self, x):
# return -(self.weights[0] + self.weights[1] * x) / self.weights[2]
def score(self, X_test, y_test):
right = 0
X_test = self.data_matrix(X_test) for x, y in zip(X_test, y_test):
result = np.dot(x, self.weights) if (result > 0 and y == 1) or (result < 0 and y == 0):
right += 1
return right / len(X_test)
# label = np.mat(y)
data_mat = self.data_matrix(X) # m*n
self.weights = np.zeros((len(data_mat[0]),1), dtype=np.float32) for iter_ in range(self.max_iter): for i in range(len(X)):
result = self.sigmoid(np.dot(data_mat[i], self.weights))
error = y[i] - result
self.weights += self.learning_rate * error * np.transpose([data_mat[i]]) print('LogisticRegression Model(learning_rate={},max_iter={})'.format(self.learning_rate, self.max_iter)) # def f(self, x):
# return -(self.weights[0] + self.weights[1] * x) / self.weights[2]
def score(self, X_test, y_test):
right = 0
X_test = self.data_matrix(X_test) for x, y in zip(X_test, y_test):
result = np.dot(x, self.weights) if (result > 0 and y == 1) or (result < 0 and y == 0):
right += 1
return right / len(X_test)
lr_clf = LogisticReressionClassifier() lr_clf.fit(X_train, y_train)
LogisticRegression Model(learning_rate=0.02,max_iter=200)
lr_clf.score(X_test, y_test)
0.9666666666666667In [205]
x_ponits = np.arange(4, 8) y_ = -(lr_clf.weights[1]*x_ponits + lr_clf.weights[0])/lr_clf.weights[2] plt.plot(x_ponits, y_)#lr_clf.show_graph()plt.scatter(X[:50,0],X[:50,1], label='0') plt.scatter(X[50:,0],X[50:,1], label='1') plt.legend()
<matplotlib.legend.Legend at 0x7f232f7e6590>
<Figure size 432x288 with 1 Axes>
- sklearn.linear_model.LogisticRegression参数
solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择,分别是:
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情

from sklearn.linear_model import LogisticRegressionIn [9]
clf = LogisticRegression(max_iter=200)In [10]
clf.fit(X_train, y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=200,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)
In [11]
clf.score(X_test, y_test)
1.0In [12]
print(clf.coef_, clf.intercept_)
[[ 2.69741404 -2.61019199]] [-6.44843344]In [13]
x_ponits = np.arange(4, 8)
y_ = -(clf.coef_[0][0]*x_ponits + clf.intercept_)/clf.coef_[0][1]
plt.plot(x_ponits, y_)
plt.plot(X[:50, 0], X[:50, 1], 'bo', color='blue', label='0')
plt.plot(X[50:, 0], X[50:, 1], 'bo', color='orange', label='1')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend()
<matplotlib.legend.Legend at 0x7f1d10e65dd0>
<Figure size 432x288 with 1 Axes>
以上就是“机器学习”系列之Logistic Regression (逻辑回归)的详细内容,更多请关注其它相关文章!
# 区别
# 淘宝怎么网站推广
# 宁夏网上营销推广公司
# 兴安盟银川网站推广
# seo平台易下拉系统
# 的是
# 进行分类
# 来袭
# 营收
# 泰勒
# 系列之
# 是一个
# 中文网
# 自定义
# 迭代
# type
# fig
# ai
# seo的优化基础
# 辽宁餐饮行业网站优化
# 浏阳视频营销推广代理商
# 房地产营销推广方案论文
# 服装店的营销和推广渠道
# seo干什么的
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
成都大运会闭幕式引入人形机器人展示表演
AI技术改变*,新骗局来袭,*成功率接近100%
宇宙探索下一阶段,机器代替人类,AI会在太空探索中取代人类吗?
MetaGPT开源框架爆红 GitHub,达到1.1万星,模拟软件开发流程
如布科技发布新产品AI口袋学习机S12
猿编程参加人工智能高峰论坛,推动人工智能教育解决方案在千所学校推行
小红书陷入麻烦!被指控未经许可使用用户图片进行AI训练
商汤科技:元萝卜 AI 下棋机器人新品发布会 6 月 14 日举行
百亿量化私募:量化投资进入“精耕细作”时代 AI带来行业新变革
Transformer六周年:当年连NeurIPS Oral都没拿到,8位作者已创办数家AI独角兽
“风乌”气象大模型科学家团队:用AI预报极端天气未来不是梦!
鉴智机器人发布基于地平线征程5的标准视觉感知产品
全球首款AI裸眼3D平板 国产的售价破万
微幼科技晨检机器人与人工晨检相比,有何优势
【搞事】时隔4年 谷歌更新安卓logo 机器人头更饱满了
泗洪:畅通城市“血管” ,管下机器人来帮忙
值得买科技入选“北京市通用人工智能产业创新伙伴计划”应用伙伴
2025智源大会AI安全话题备受关注,《人机对齐》新书首发
阿里达摩院向公众免费开放100项AI专利许可
对话无界AI创始人长铗:AI的创业机会在应用层丨创新者Innovator
消息称字节机器人团队已有约50人,计划年底扩充到上百人
AYANEO AIR 1S 掌机 7 月 9 日发布:R7 7840U + OLED 屏
谷歌推出 AI 反洗钱工具,可将金融机构内部风险预警准确率提高2至4倍
在心理治疗中用VR技术,治疗成效显著提高
美图第二届影像节发布七款AI影像创作工具
人形机器人概念集体爆发,能买吗?
无人机自主巡检为高海拔输电线路运维添“新彩”
人工智能领域,突破难题:国产大模型“无源之水”问题得到解决。
「电子果蝇」惊动马斯克!背后是13万神经元全脑图谱,可在电脑上运行
英伟达H100霸榜权威AI性能测试 11分钟搞定基于GPT-3的大模型训练
AI+音乐如何“生成”动听旋律?一起揭秘世界人工智能大会开场曲
IBM 与 NASA 携手开源地理空间 AI 模型,促进气候科学研究进步
英媒:硅谷有些人太鼓吹AI,宣扬“学习无用”
猿辅导发布最新SaaS业务进展公告:Motiff UI设计工具推出三项新的AI功能
华为将于 7 月发布面向 AI 大模型的新款存储产品
映宇宙数字人“映映”亮相ChinaJoy,展示AI黑科技实现用户互动
LinkedIn 推出生成式 AI 辅助撰写帖文功能,将向所有用户开放
学而思网校推出首个基于自研大模型的《人工智能第一课》
找对了风口想不火都难,乐天派机器人,安卓机器人的最终形态?
人形机器人打开精密齿轮市场全新空间!受益上市公司梳理
清华系面壁智能开源中文多模态大模型VisCPM :支持对话文图双向生成,吟诗作画能力惊艳
30+大模型齐聚,大模型成世界人工智能大会“顶流”
ChatGPT设计出的第一个机器人来了!【附人工智能行业预测】
联想创投携手12家被投企业MWC展示元宇宙、机器人等技术
人工智能在商业中的风险和局限性
亚太地区 70% 的企业高管正探索生成式 AI 应用或已经进行投资
MiracleVision视觉大模型功能介绍
马斯克预测:特斯拉全自动驾驶将在今年实现 对AI深度变化感到担忧
湖北科技职业学院举行工业机器人及智能制造技术专精特新产业学院建设启动仪式
Databricks推出人工智能模型共享机制,可令开发者与公司“双赢”
 当前位置:
当前位置:  # label = np.mat(y)
data_mat = self.data_matrix(X) # m*n
self.weights = np.zeros((len(data_mat[0]),1), dtype=np.float32) for iter_ in range(self.max_iter): for i in range(len(X)):
result = self.sigmoid(np.dot(data_mat[i], self.weights))
error = y[i] - result
self.weights += self.learning_rate * error * np.transpose([data_mat[i]]) print('LogisticRegression Model(learning_rate={},max_iter={})'.format(self.learning_rate, self.max_iter)) # def f(self, x):
# return -(self.weights[0] + self.weights[1] * x) / self.weights[2]
def score(self, X_test, y_test):
right = 0
X_test = self.data_matrix(X_test) for x, y in zip(X_test, y_test):
result = np.dot(x, self.weights) if (result > 0 and y == 1) or (result < 0 and y == 0):
right += 1
return right / len(X_test)
# label = np.mat(y)
data_mat = self.data_matrix(X) # m*n
self.weights = np.zeros((len(data_mat[0]),1), dtype=np.float32) for iter_ in range(self.max_iter): for i in range(len(X)):
result = self.sigmoid(np.dot(data_mat[i], self.weights))
error = y[i] - result
self.weights += self.learning_rate * error * np.transpose([data_mat[i]]) print('LogisticRegression Model(learning_rate={},max_iter={})'.format(self.learning_rate, self.max_iter)) # def f(self, x):
# return -(self.weights[0] + self.weights[1] * x) / self.weights[2]
def score(self, X_test, y_test):
right = 0
X_test = self.data_matrix(X_test) for x, y in zip(X_test, y_test):
result = np.dot(x, self.weights) if (result > 0 and y == 1) or (result < 0 and y == 0):
right += 1
return right / len(X_test) 上一篇:
上一篇: 返回列表
返回列表

