


400 128 6709

行业新闻
 发布时间:2023-07-22
发布时间:2023-07-22 点击次数:
点击次数: 当大家不断升级迭代自家大模型的时候,LLM(大语言模型)对上下文窗口的处理能力,也成为一个重要评估指标。
比如明星大模型 GPT-4 支持 32k token,相当于 50 页的文字;OpenAI 前成员创立的 Anthropic 更是将 Claude 处理 token 能力提升到 100k,约 75000 个单词,大概相当于一键总结《哈利波特》第一部。
在微软最新的一项研究中,他们这次直接将 Transformer 扩展到 10 亿 token。这为建模非常长的序列开辟了新的可能性,例如将整个语料库甚至整个互联网视为一个序列。
作为比较,普通人可以在 5 小时左右的时间里阅读 100,000 个 token,并可能需要更长的时间来消化、记忆和分析这些信息。Claude 可以在不到 1 分钟的时间里完成这些。要是换算成微软的这项研究,将会是一个惊人的数字。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
具体而言,该研究提出了 LONGNET,这是一种 Transformer 变体,可以将序列长度扩展到超过 10 亿个 token,而不会牺牲对较短序列的性能。文中还提出了 dilated attention,它能指数级扩展模型感知范围。
LONGNET 具有以下优势:
1)它具有线性计算复杂性;
2)它可以作为较长序列的分布式训练器;
3)dilated attention 可以无缝替代标准注意力,并可以与现有基于 Transformer 的优化方法无缝集成。
实验结果表明,LONGNET 在长序列建模和一般语言任务上都表现出很强的性能。
在研究动机方面,论文表示,最近几年,扩展神经网络已经成为一种趋势,许多性能良好的网络被研究出来。在这当中,序列长度作为神经网络的一部分,理想情况下,其长度应该是无限的。但现实却往往相反,因而打破序列长度的限制将会带来显著的优势:
然而,扩展序列长度面临的主要挑战是在计算复杂性和模型表达能力之间找到合适的平衡。
例如 RNN 风格的模型主要用于增加序列长度。然而,其序列特性限制了训练过程中的并行化,而并行化在长序列建模中是至关重要的。
最近,状态空间模型对序列建模非常有吸引力,它可以在训练过程中作为 CNN 运行,并在测试时转换为高效的 RNN。然而这类模型在常规长度上的表现不如 Transformer。
另一种扩展序列长度的方法是降低 Transformer 的复杂性,即自注意力的二次复杂性。现阶段,一些高效的基于 Transformer 的变体被提出,包括低秩注意力、基于核的方法、下采样方法、基于检索的方法。然而,这些方法尚未将 Transformer 扩展到 10 亿 token 的规模(参见图 1)。
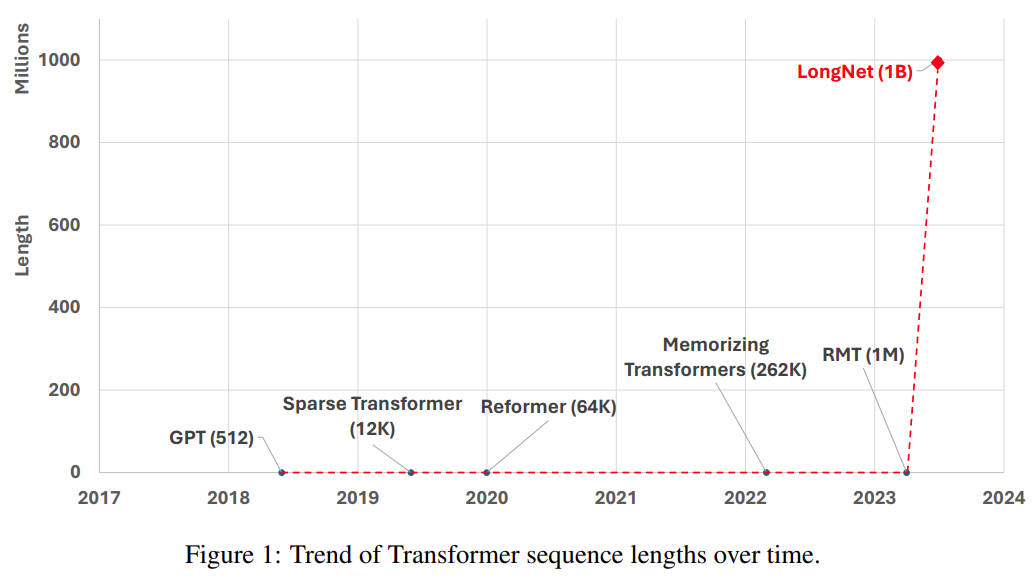 图片
图片
下表为不同计算方法的计算复杂度比较。N 为序列长度,d 为隐藏维数。
 图片
图片
该研究的解决方案 LONGNET 成功地将序列长度扩展到 10 亿个 token。具体来说,该研 究提出一种名为 dilated attention 的新组件,并用 dilated attention 取代了 Vanilla Transformer 的注意力机制。通用的设计原则是注意力的分配随着 token 和 token 之间距离的增加而呈指数级下降。该研究表明这种设计方法获得了线性计算复杂度和 token 之间的对数依赖性。这就解决了注意力资源有限和可访问每个 token 之间的矛盾。
究提出一种名为 dilated attention 的新组件,并用 dilated attention 取代了 Vanilla Transformer 的注意力机制。通用的设计原则是注意力的分配随着 token 和 token 之间距离的增加而呈指数级下降。该研究表明这种设计方法获得了线性计算复杂度和 token 之间的对数依赖性。这就解决了注意力资源有限和可访问每个 token 之间的矛盾。
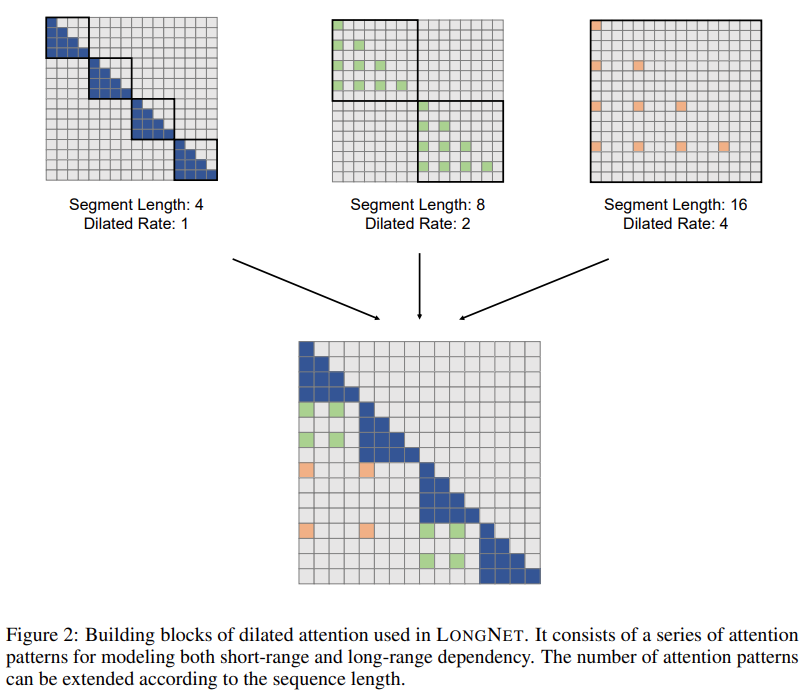 图片
图片
在实现过程中,LONGNET 可以转化成一个密集 Transformer,以无缝地支持针对 Transformer 的现有优化方法(例如内核融合(kernel fusion)、量化和分布式训练)。利用线性复杂度的优势,LONGNET 可以跨节点并行训练,用分布式算法打破计算和内存的约束。
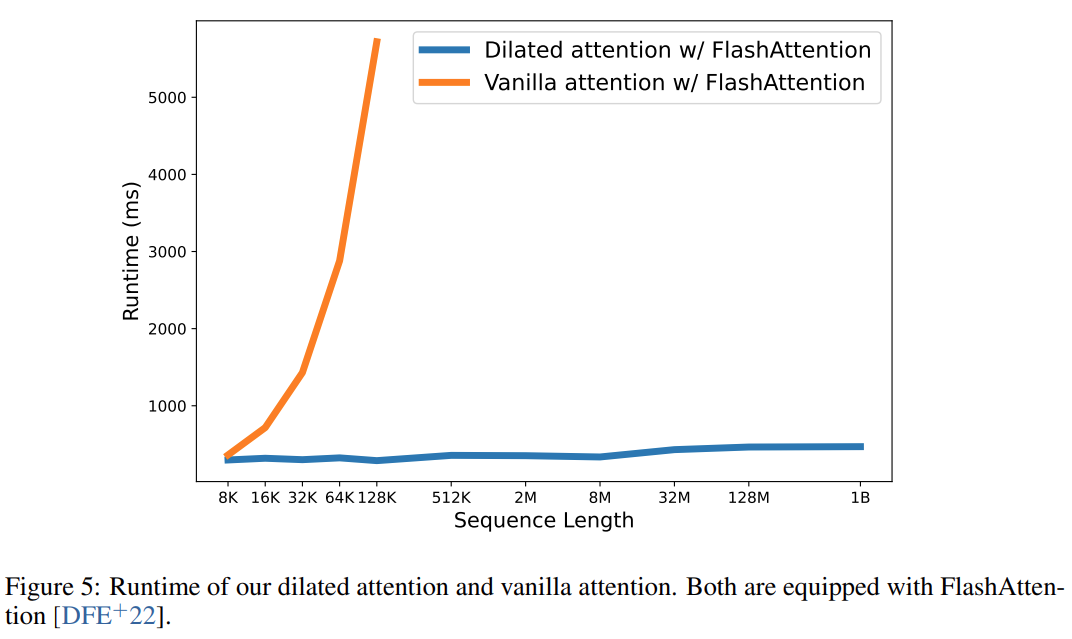
最终,该研究有效地将序列长度扩大到 1B 个 token,而且运行时(runtime)几乎是恒定的,如下图所示。相比之下,Vanilla Transformer 的运行时则会受到二次复杂度的影响。
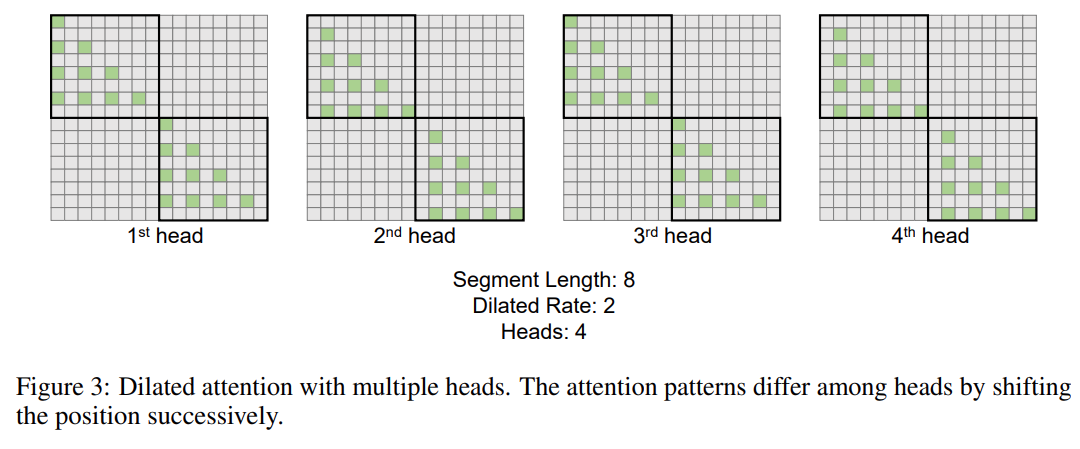
该研究进一步引入了多头 dilated attention 机制。如下图 3 所示,该研究通过对查询 - 键 - 值对的不同部分进行稀疏化,在不同的头之间进行不同的计算。
 图片
图片
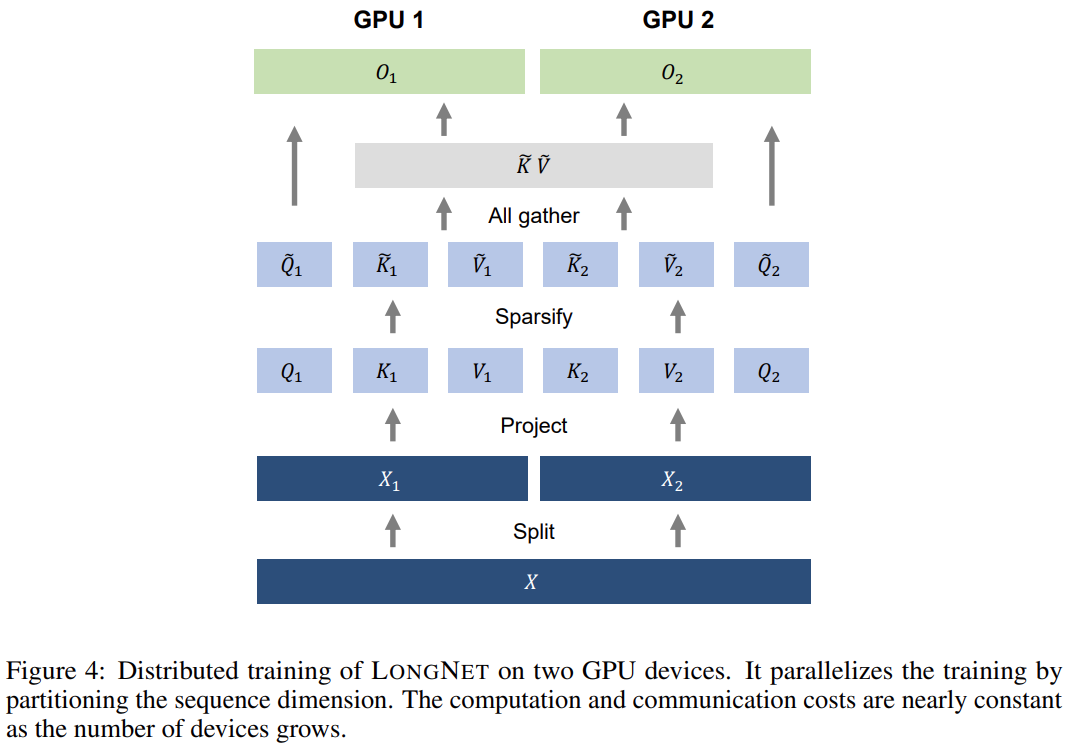
分布式训练
虽然 dilated attention 的计算复杂度已经大幅降低到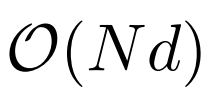 ,但由于计算和内存的限制,在单个 GPU 设备上将序列长度扩展到百万级别是不可行的。有一些用于大规模模型训练的分布式训练算法,如模型并行 [SPP+19]、序列并行 [LXLY21, KCL+22] 和 pipeline 并行 [HCB+19],然而这些方法对于 LONGNET 来说是不够的,特别是当序列维度非常大时。
,但由于计算和内存的限制,在单个 GPU 设备上将序列长度扩展到百万级别是不可行的。有一些用于大规模模型训练的分布式训练算法,如模型并行 [SPP+19]、序列并行 [LXLY21, KCL+22] 和 pipeline 并行 [HCB+19],然而这些方法对于 LONGNET 来说是不够的,特别是当序列维度非常大时。
该研究利用 LONGNET 的线性计算复杂度来进行序列维度的分布式训练。下图 4 展示了在两个 GPU 上的分布式算法,还可以进一步扩展到任意数量的设备。
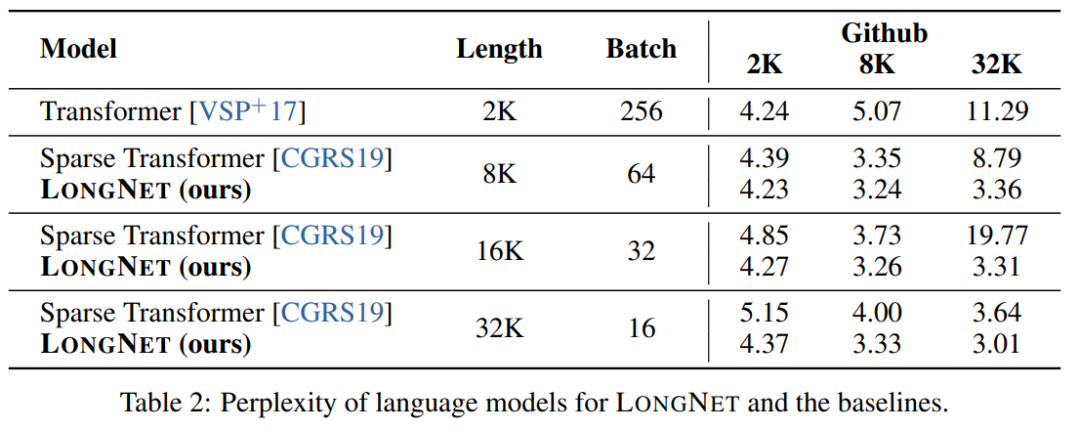
该研究将 LONGNET 与 vanilla Transformer 和稀疏 Transformer 进行了比较。架构之间的差异是注意力层,而其他层保持不变。研究人员将这些模型的序列长度从 2K 扩展到 32K,与此同时减小 batch 大小,以保证每个 batch 的 token 数量不变。
表 2 总结了这些模型在 Stack 数据集上的结果。研究使用复杂度作为评估指标。这些模型使用不同的序列长度进行测试,范围从 2k 到 32k 不等。当输入长度超过模型支持的最大长度时,研究实现了分块因果注意力(blockwise causal attention,BCA)[SDP+22],这是一种最先进的用于语言模型推理的外推方法。
此外,研究删除了绝对位置编码。首先,结果表明,在训练过程中增加序列长度一般会得到更好的语言模型。其次,在长度远大于模型支持的情况下,推理中的序列长度外推法并不适用。最后,LONGNET 一直优于基线模型,证明了其在语言建模中的有效性。
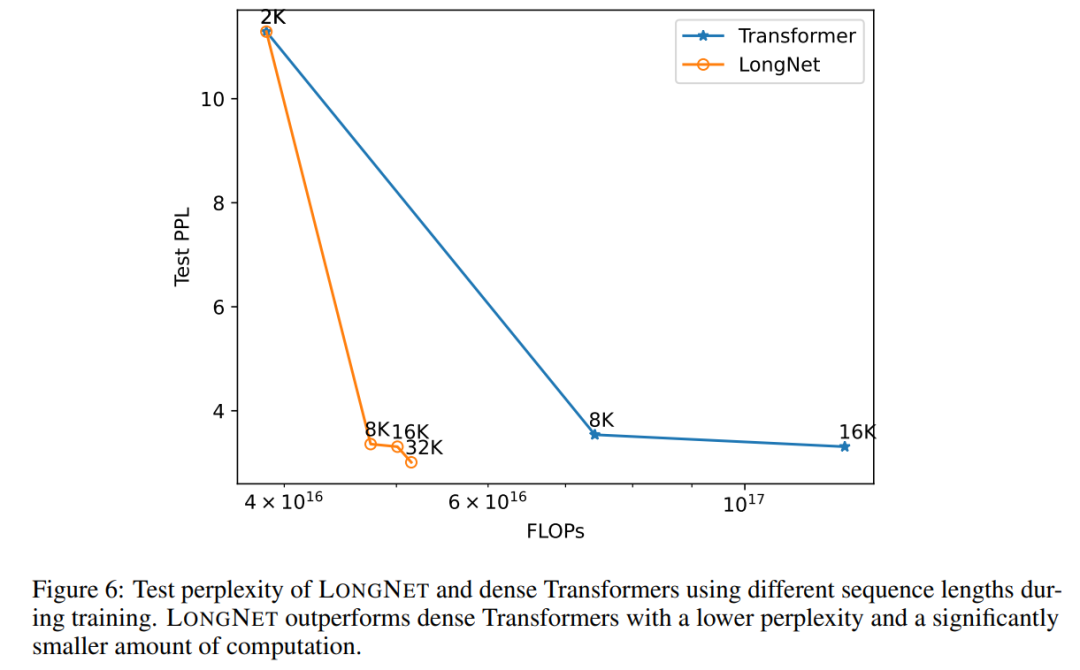
序列长度的扩展曲线
图 6 绘制了 vanilla transformer 和 LONGNET 的序列长度扩展曲线。该研究通过计算矩阵乘法的总 flops 来估计计算量。结果表明,vanilla transformer 和 LONGNET 都能从训练中获得更大的上下文长度。然而,LONGNET 可以更有效地扩展上下文长度,以较小的计算量实现较低的测试损失。这证明了较长的训练输入比外推法更具有优势。实验表明,LONGNET 是一种更有效的扩展语言模型中上下文长度的方法。这是因为 LONGNET 可以更有效地学习较长的依赖关系。
扩展模型规模
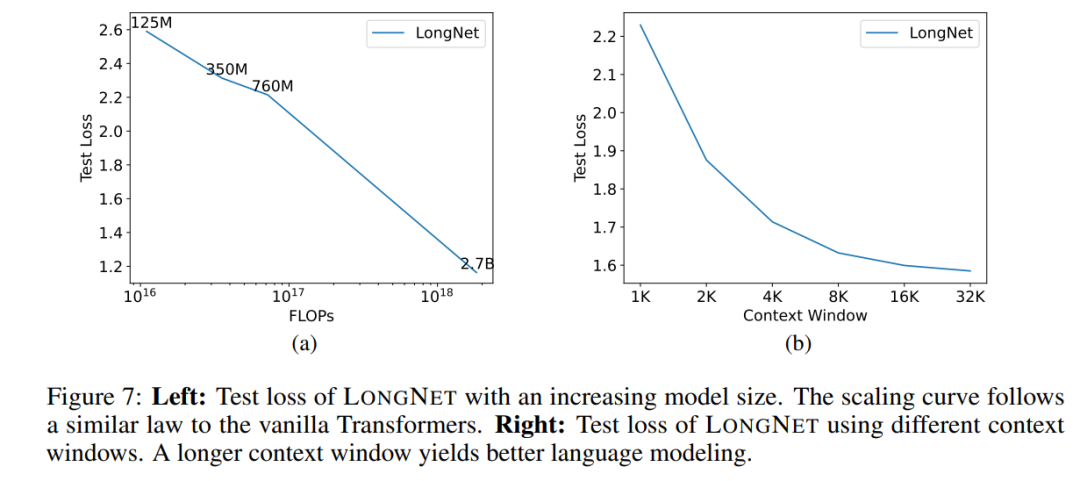
大型语言模型的一个重要属性是:损失随着计算量的增加呈幂律扩展。为了验证 LONGNET 是否仍然遵循类似的扩展规律,该研究用不同的模型规模(从 1.25 亿到 27 亿个参数) 训练了一系列模型。27 亿的模型是用 300B 的 token 训练的,而其余的模型则用到了大约 400B 的 token。图 7 (a) 绘制了 LONGNET 关于计算的扩展曲线。该研究在相同的测试集上计算了复杂度。这证明了 LONGNET 仍然可以遵循幂律。这也就意味着 dense Transformer 不是扩展语言模型的先决条件。此外,可扩展性和效率都是由 LONGNET 获得的。
长上下文 prompt
Prompt 是引导语言模型并为其提供额外信息的重要方法。该研究通过实验来验证 LONGNET 是否能从较长的上下文提示窗口中获益。
该研究保留了一段前缀(prefixes)作为 prompt,并测试其后缀(suffixes)的困惑度。并且,研究过程中,逐渐将 prompt 从 2K 扩展到 32K。为了进行公平的比较,保持后缀的长度不变,而将前缀的长度增加到模型的最大长度。图 7 (b) 报告了测试集上的结果。它表明,随着上下文窗口的增加,LONGNET 的测试损失逐渐减少。这证明了 LONGNET 在充分利用长语境来改进语言模型方面的优越性。
以上就是微软新出热乎论文:Transformer扩展到10亿token的详细内容,更多请关注其它相关文章!
# 证明了
# 荆门seo联系方式查询
# 上海seo实用技巧
# 汉中seo网络营销
# 云阳县网站推广代运营公司
# 商河企业抖音营销推广方案
# 随州网站优化推广电话
# 河北区口碑营销推广中心
# 网站营销推广薇星hfqjwl出词
# 轻食内容营销推广策略
# 企业网站建设思路
# 提出了
# 互联网
# 将会
# 更长
# 较长
# 过程中
# 新出
# 官网
# 微软
# 扩展到
# claude
# 论文
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
组建团队,字节跳动要造机器人?
Transformer六周年:当年连NeurIPS Oral都没拿到,8位作者已创办数家AI独角兽
GPT-4使用混合大模型?研究证明MoE+指令调优确实让大模型性能超群
WHEE上线时间介绍
好莱坞面临全面停摆 好莱坞大罢工抵制“AI入侵”
曝索尼在开发新头显设备:游戏中使用AR技术
人脸识别+全景双摄+AI算法 萤石推动智能锁行业革新
世界水下机器人大赛:9国青年携手逐梦深蓝
应对算力挑战,亚马逊云科技发力AI基础设施建设
即时 AI再次升级 30秒生成自带动效的网页 生成速度提升100%
2025年贵州省青少年机器人竞赛在安举行
AI赋能艺术 超现实达利奇幻之旅在沪开启
乐天派桌面机器人加入小米米家生态系统,实现与其他智能设备的互联
联合国秘书长称支持建立全球人工智能监管机构
苹果推出全新沉浸式 AR 体验应用“Deep Field”
首个算网生态体!中国移动元宇宙产业联盟正式成立
看似低调,实则稳健:字节在AI路上会遇到什么?
PS AI修图免费平替来了!Stability AI又放大招,核弹级更新一键扩图
马斯克讽刺人工智能炒作:什么“机器学习”,其实就是统计
日本学校探索引入 AI 和无人机:提高安保效率,节省劳动力
用AI技术点亮老照片:Deep Nostalgia带给照片新生动感
人工智能赋能广西自然资源领域监测监管
中兴通讯无人机高空基站助力北京门头沟受灾乡镇保障应急通信
外科医生的智能助手,“机器人手术”得到补充商业医保覆盖
人工智能赋能无人驾驶:商业化进程再提速
人工智能改变网络安全和用户体验的三种方式
西班牙小鲜肉*视频在网上疯传,本人发文澄清:是AI换脸的假视频!
AI新风口?首个高质量「文生视频」模型Zeroscope引发开源大战:最低8G显存可跑
QQ音乐业内率先推出「AI一起听」功能,领取你的AI听歌助手
微软在 Build 大会上宣布的新 Microsoft Store AI Hub 现已开始推出
普林斯顿Infinigen矩阵开启!AI造物主100%创造大自然,逼真到炸裂
AI和ML推动联网设备的增长
用人工智能技术,亚马逊为用户生成产品评论摘要,帮助他们轻松选购
Stability AI 推出文生图模型 SDXL0.9,GPU要求下探至消费级水平
人工智能驱动智能建筑会是未来趋势吗?
斑马推出全新升级版思维机:以人工智能为核心的交互式学习体验
AI拉动PCB发展|行业发现
上海发布大模型政策 打造AI“模”都
【澎湃原动力】人工智能产业协同创新中心:全产业链资源在这里汇聚
爱设计 AI 一键生成 PPT 工具上线:输入标题即可生成 PPT
如布AI口袋学习机S12 将亮相综艺节目《好样的!国货》
苹果AIGC专利:可通过语音指令生成AR/VR虚拟场景
上影节直击 | AI技术降低了短片拍摄门槛?金爵奖评委不赞同
全国体育人工智能大会举办,专家聚焦体育人工智能领域人才培养
阿里云推出通义万相AI绘画大模型
陈根:AI冥想教练为用户提供个性化指导
云深处科技绝影 Lite3 与 X20 四足机器人亮相
人工智能进入绿植界,智能庭院市场初具规模
“三夏”农忙保障用电,无人机高空巡视高压线
首届全国体育人工智能大会在首都体育学院召开
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

