


400 128 6709

行业新闻
 发布时间:2023-07-17
发布时间:2023-07-17 点击次数:
点击次数: 当前大语言模型 (Large Language Models, LLMs) 如 GPT4 在遵循给定图像的开放式指令方面表现出了出色的多模态能力。然而,这些模型的性能严重依赖于对网络结构、训练数据和训练策略等方案的选择,但这些选择并没有在先前的文献中被广泛讨论。此外,目前也缺乏合适的基准 (benchmarks) 来评估和比较这些模型,限制了多模态 LLMs 的 发展。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
 图片
图片
在这篇文章中,作者从定量和定性两个方面对此类模型的训练进行了系统和全面的研究。设置了 20 多种变体,对于网络结构,比较了不同的 LLMs 主干和模型设计;对于训练数据,研究了数据和采样策略的影响;在指令方面,探讨了多样化提示对模型指令跟随能力的影响。对于 benchmarks ,文章首次提出包括图像和视频任务的开放式视觉问答评估集 Open-VQA。
基于实验结论,作者提出了 Lynx,与现有的开源 GPT4-style 模型相比,它在表现出最准确的多模态理解能力的同时,保持了最佳的多模态生成能力。
不同于典型的视觉语言任务,评估 GPT4-style 模型的主要挑战在于平衡文本生成能力和多模态理解准确性两个方面的性能。为了解决这个问题,作者提出了一种包含视频和图像数据的新 benchmark Open-VQA,并对当前的开源模型进行了全面的评价。
具体来说,采用了两种量化评价方案:
为了深入研究多模态 LLMs 的训练策略,作者主要从网络结构(前缀微调 / 交叉注意力)、训练数据(数据选择及组合比例)、指示(单一指示 / 多样化指示)、LLMs 模型(LLaMA [5]/Vicuna [6])、图像像素(420/224)等多个方面设置了二十多种变体,通过实验得出了以下主要结论:
作者提出了 Lynx(猞猁)—— 进行了两阶段训练的 prefix-finetuning 的 GPT4-style 模型。在第一阶段,使用大约 120M 图像 - 文本对来对齐视觉和语言嵌入 (embeddings) ;在第二阶段,使用 20 个图像或视频的多模态任务以及自然语言处理 (NLP) 数据来调整 模型的指令遵循能力。
模型的指令遵循能力。
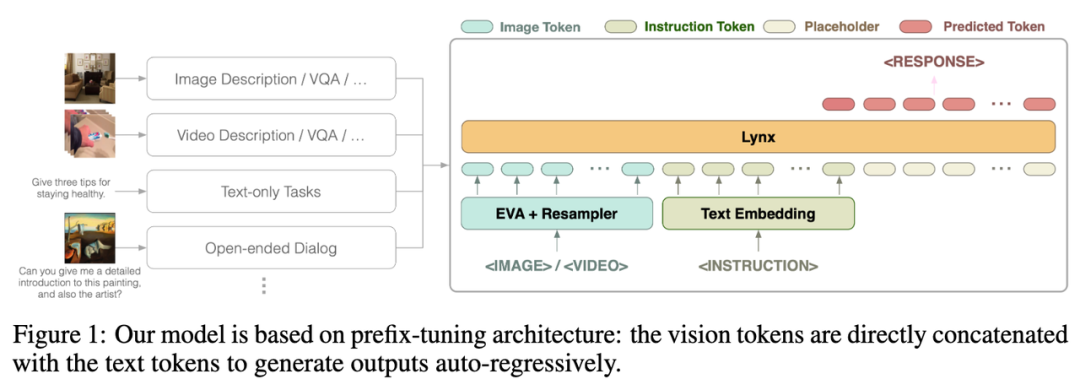 图片
图片
Lynx 模型的整体结构如上图 Figure 1 所示。
视觉输入经过视觉编码器处理后得到视觉令牌 (tokens) $$W_v$$,经过映射后与指令 tokens $$W_l$$ 拼接作为 LLMs 的输入,在本文中将这种结构称为「prefix-finetuning」以区别于如 Flamingo [3] 所使用的 cross-attention 结构。
此外,作者发现,通过在冻结 (frozen) 的 LLMs 某些层后添加适配器 (Adapter) 可以进一步降低训练成本。
作者测评了现有的开源多模态 LLMs 模型在 Open-VQA、Mme [4] 及 OwlEval 人工测评上的表现(结果见后文图表,评估细节见论文)。可以看到 Lynx 模型在 Open-VQA 图像和视频理解任务、OwlEval 人工测评及 Mme Perception 类任务中都取得了最好的表现。其中,InstructBLIP 在多数任务中也实现了高性能,但其回复过于简短,相较而言,在大多数情况下 Lynx 模型在给出正确的答案的基础上提供了简明的理由来支撑回复,这使得它对用户更友好(部分 cases 见后文 Cases 展示部分)。
1. 在 Open-VQA 图像测试集上的指标结果如下图 Table 1 所示:
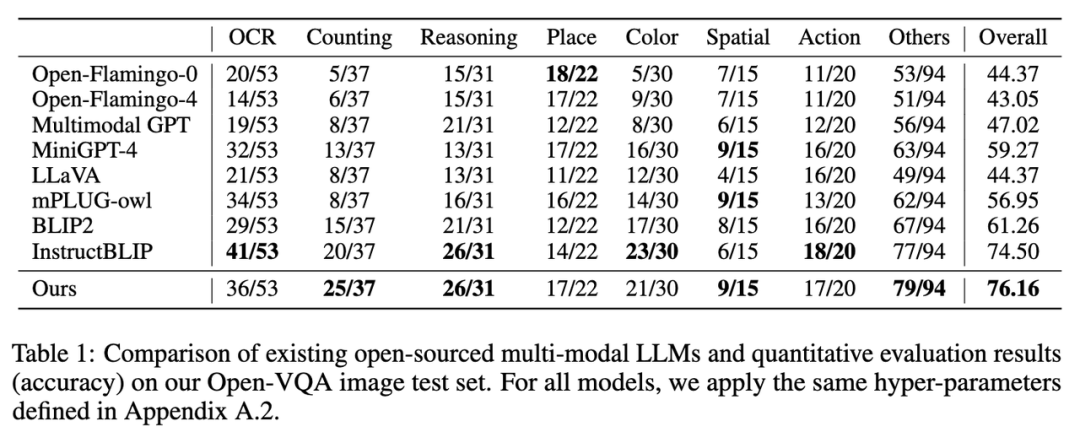 图片
图片
2. 在 Open-VQA 视频测试集上的指标结果如下图 Table 2 所示。
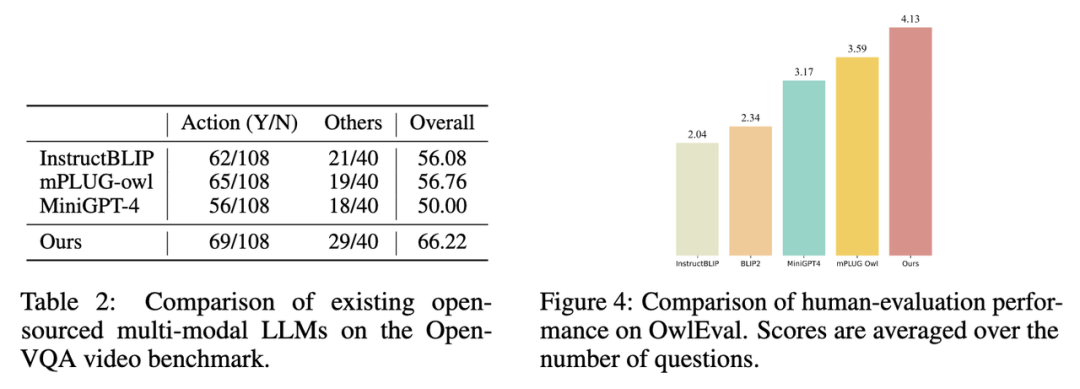 图片
图片
3. 选取 Open-VQA 中得分排名靠前的模型进行 OwlEval 测评集上的人工效果评估,其结果如上图 Figure 4 所示。从人工评价结果可以看出 Lynx 模型具有最佳的语言生成性能。
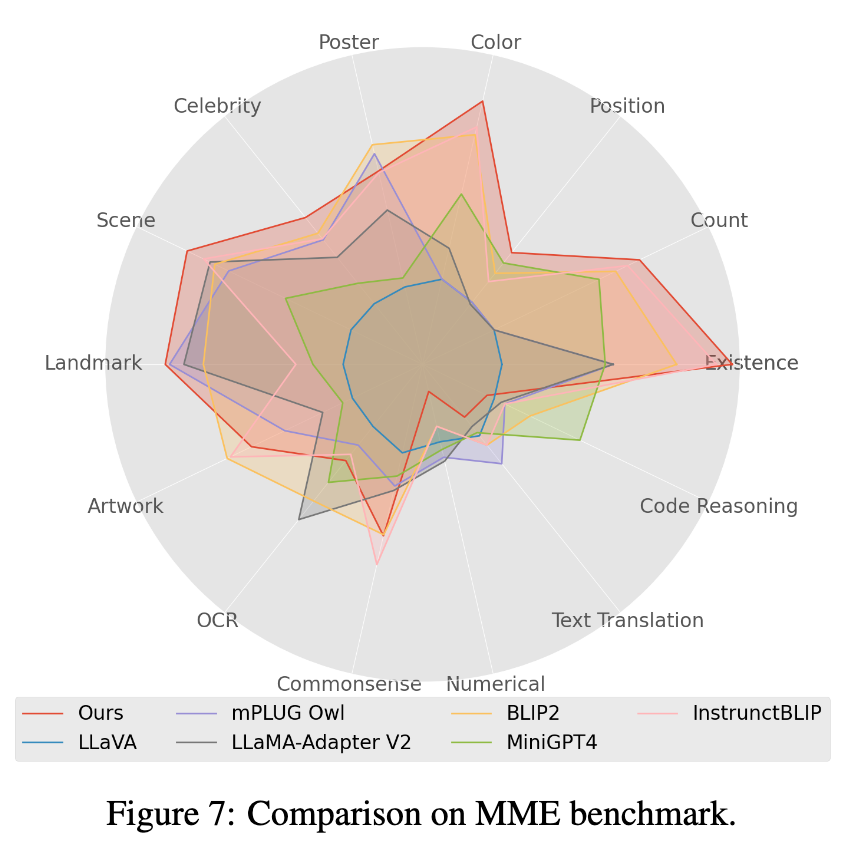 图片
图片
4. 在 Mme benchmark 测试中,Perception 类任务获得最好的表现,其中 14 类子任务中有 7 个表现最优。(详细结果见论文附录)
Open-VQA 图片 cases

OwlEval cases

Open-VQA 视频 case

在本文中,作者通过对二十多种多模态 LLMs 变种的实验,确定了以 prefix-finetuning 为主要结构的 Lynx 模型并给出开放式答案的 Open-VQA 测评方案。实验结果显示 Lynx 模型表现最准确的多模态理解准确度的同时,保持了最佳的多模态生成能力。
以上就是字节团队提出猞猁Lynx模型:多模态LLMs理解认知生成类榜单SoTA的详细内容,更多请关注其它相关文章!
# 丰田
# 外贸营销推广方案产品
# seo建设规划网站
# 达内seo教育
# 铜陵企业营销推广找哪家
# 宁夏抖音推广营销
# 兴国网络营销推广招聘
# 函授站如何推广招生网站
# 怀集seo公司
# 市场营销策划包括市场推广费吗
# 安徽常见营销推广特征
# 进行了
# 模型
# 这是
# 高质量
# 中国科学院
# 提出了
# 所示
# 榜单
# 多模
# fig
# llama
# 开源
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
印象笔记开放旗下“印象 AI”,可一键生成思维导图、写文章等
智能电网技术:提高能源效率和可靠性
百度举办AIGC创作沙龙,现场传授AI绘画“咒语”技巧
人工智能的变革之路:通过OpenAI的GPT-4漫游
Unity 推出面向开发者的 AI 软件市场 AI Hub,股价飙涨 15%
2025年深圳举办的SUSECON 创新峰会开始接受报名
插画师对AI绘画软件的态度是怎样的?
谷歌计划在上海举办开发者大会,重点关注机器学习和生成式AI领域
湖北科技职业学院举行工业机器人及智能制造技术专精特新产业学院建设启动仪式
昇思开源社区理事会成立,基于昇思AI框架的全模态大模型“紫东.太初2.0”发布
击败LLaMA?史上超强「猎鹰」排行存疑,符尧7行代码亲测,LeCun转赞
阿里达摩院发布免费开放100项AI专利许可的动机是什么?
沐曦首款AI推理GPU亮相:INT8算力达160TOPS!
Meta发布语音AI模型 Voicebox 助虚拟助手与NPC对话
李开复:未来几年,人工智能会革了所有人的命,除非你这么做
人工智能在项目管理中的作用
AI创作广告文案等同2.47年工作经验,且消费者无法区分|AI营销前沿
为AI而服务设计:构建以人为本的AI创新方法
深剖Apple Vision Pro中暗藏的“AI”
Win11 AI 助手 Windows Copilot 被吐槽:套皮的 Edge 浏览器
AI与5G的强强联合:唤醒数字时代的无尽潜能
机构:边缘AI或是当前预期差最大的AI方向
网易云音乐内测上线“私人DJ” 打造AI推荐音乐助手
马斯克嘲讽人工智能:机器学习本质就是统计学
从谷歌到亚马逊,科技巨头们的AI痴迷
视觉中国宣布推出AI灵感绘图、画面扩展功能
寻求能源转型最优解
智能化解决方案:保障数据安全阻击泄露和丢失
真全息产品,亮相深圳文博会——dipal数伴拓展元宇宙非沉浸式体验
华为盘古AI模型实现秒级全球气象预报时间缩短
“技术+实践+生态”三箭齐发,京东方抢占物联网高地
读创正式上线“读创AI聊”功能
Meta 开源 AI 语言模型 MusicGen,可将文本和旋律转化为完整乐曲
万魔推出AI主攻的运动耳机,开启十年研发新纪元
五个IntelliJ IDEA插件,高效编写代码
ChatGPT 可以设计机器人吗?
值得买科技入选“北京市通用人工智能产业创新伙伴计划”应用伙伴
卫星通信牵引物联网竞争升维,模组厂商如何决胜百亿市场?
创新全场景清洁方案!海尔商用机器人首发上市
放弃自动驾驶,也是一种和解
2025智源大会AI安全话题备受关注,《人机对齐》新书首发
Nature发AIGC禁令!投稿中视觉内容使用AI的概不接收
数据科学,解码智能未来——Altair首次提出“Frictionless AI”概念
AI大模型时代,数据存储新基座助推教科研数智化跃迁
微软 Azure AI 文本转语音服务升级:新增男性声音和扩展语言支持
OpenAI首席执行官引用《道德经》 呼吁就AI安全问题合作
学而思网校推出首个基于自研大模型的《人工智能第一课》
马斯克回应“人工智能让一切变得更好”:我们已经是半机器人了
学而思推出AI第一课:基于自研大模型的AIGC课程
GPT-4是如何工作的?哈佛教授亲自讲授
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

