近日,由清华大学计算机系朱军教授课题组发布的基于薛定谔桥的语音合成系统 [1],凭借其 「数据到数据」的生成范式,在样本质量和采样速度两方面,均击败了扩散模型的 「噪声到数据」范式。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文链接:https://arxiv.org/abs/2312.03491项目网站:https://bridge-tts.github.io/ 代码实现:https://github.com/thu-ml/Bridge-TTS自 2025 年起,扩散模型(diffusion models)开始成为文本到语音合成(text-to-speech, TTS)领域的核心生成方法之一,如华为诺亚方舟实验室提出的 Grad-TTS [2]、浙江大学提出的 DiffSinger [3] 等方法均实现了较高的生成质量。此后,又有众多研究工作有效提升了扩散模型的采样速度,如通过先验优化 [2,3,4]、模型蒸馏 [5,6]、残差预测 [7] 等方法。然而,如此项研究所示,由于扩散模型受限于「噪声到数据」的生成范式,其先验分布对生成目标提供的信息始终较为有限,对条件信息无法利用充分。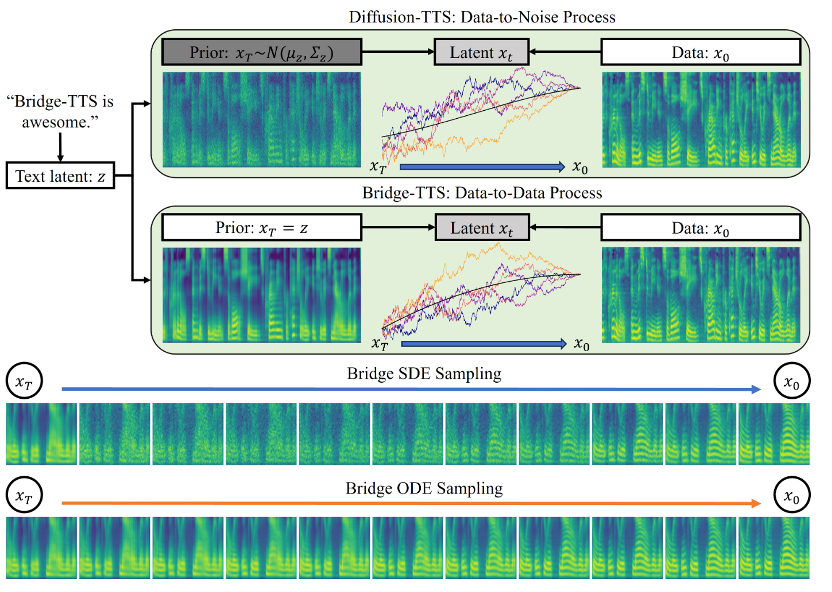
本次语音合成领域的最新研究工作,Bridge-TTS,凭借其基于薛定谔桥的生成框架,实现了「数据到数据」的生成过程,首次将语音合成的先验信息由噪声修改为干净数据,由分布修改为确定性表征。该方法的主要架构如上图所示,输入文本首先经由文本编码器提取出生成目标(mel-spectrogram, 梅尔谱)的隐空间表征。此后,与扩散模型将此信息并入噪声分布或用作条件信息不同,Bridge-TTS 的方法支持直接将其作为先验信息,并支持通过随机或确定性采样的方式,高质量、快速地生成目标。在验证语音合成质量的标准数据集 LJ-Speech 上,研究团队将 Bridge-TTS 与 9 项高质量的语音合成系统和扩散模型的加速采样方法进行了对比。如下所示,该方法在样本质量上(1000 步、50 步采样)击败了基于扩散模型的高质量 TTS 系统 [2,3,7],并在采样速度上,在无需任何后处理如额外模型蒸馏的条件下,超过了众多加速方法,如残差预测、渐进式蒸馏、以及最新的一致性蒸馏等工作 [5,6,7]。以下是 Bridge-TTS 与基于扩散模型方法的生成效果示例,更多生成样本对比可访问项目网站:https://bridge-tts.github.io/
输入文本:「Printing, then, for our purpose, may be considered as the art of making books by means of movable types.」 输入文本:「The first books were printed in black letter, i.e. the letter which was a Gothic development of the ancient Roman character,」
输入文本:「The first books were printed in black letter, i.e. the letter which was a Gothic development of the ancient Roman character,」 输入文本:「The prison population fluctuated a great deal,」
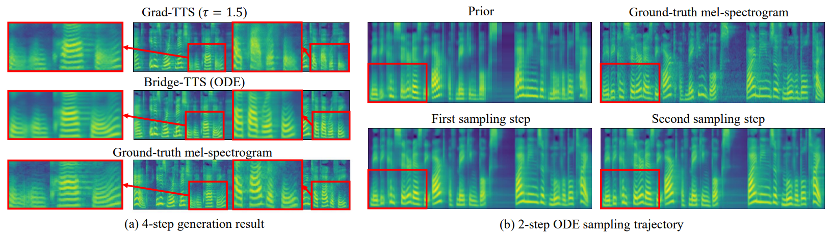
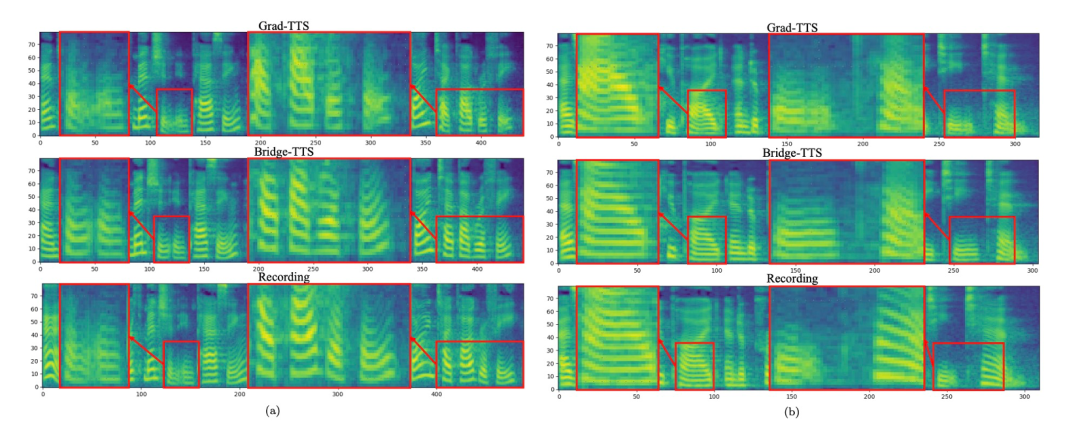
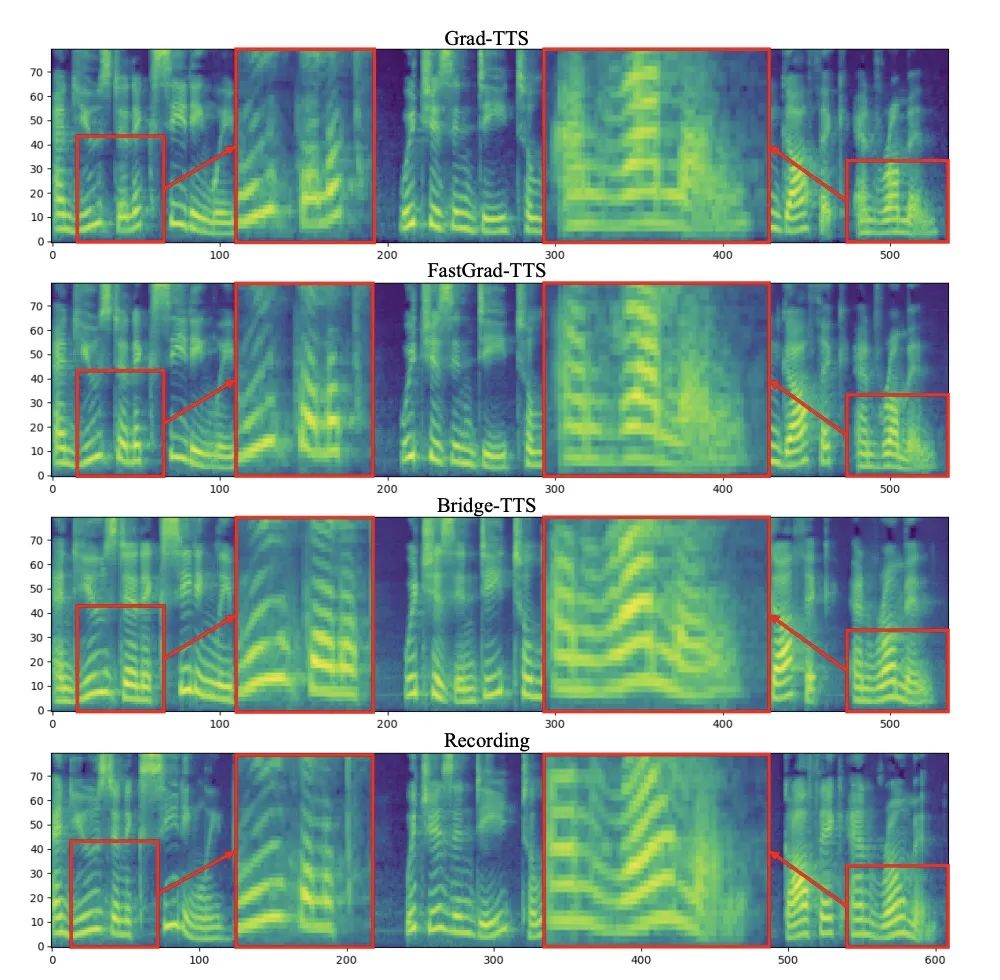
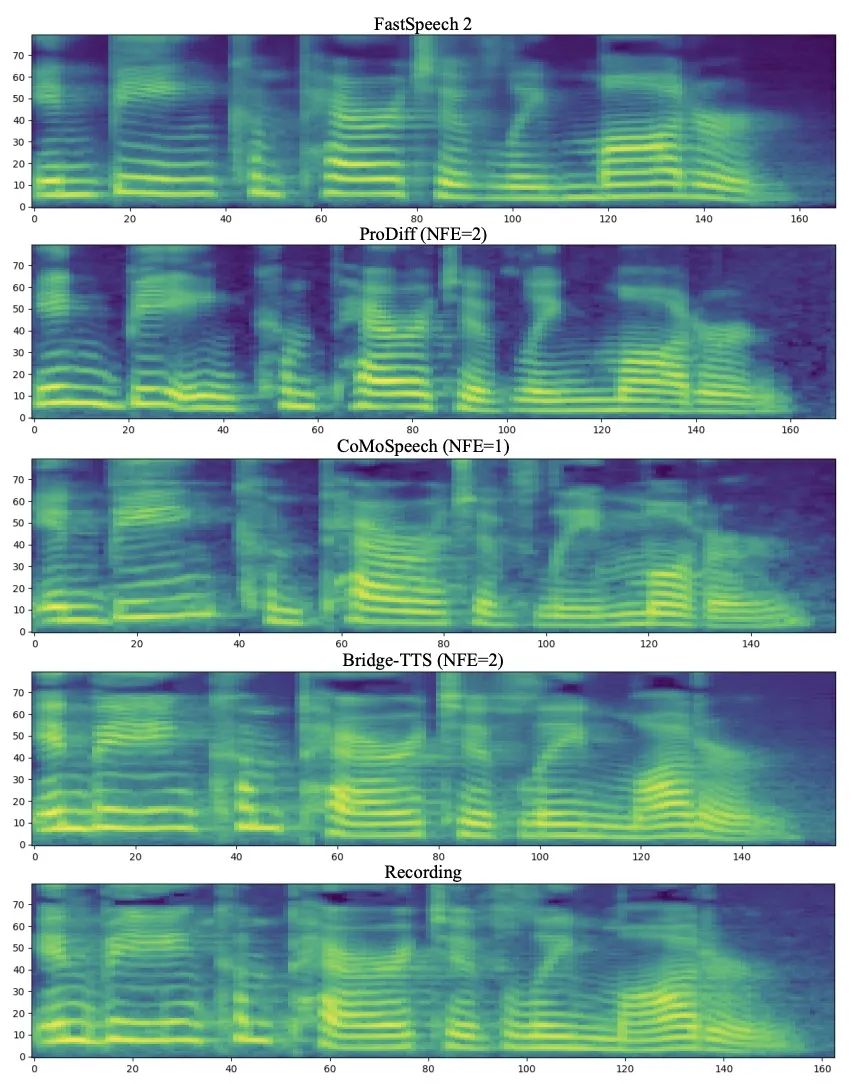
输入文本:「The prison population fluctuated a great deal,」 下面展示了 Bridge-TTS 一个在 2 步和 4 步的一个确定性合成(ODE sampling)案例。在 4 步合成中,该方法相较于扩散模型显著合成了更多样本细节,并没有噪声残留的问题。在 2 步合成中,该方法展示出了完全纯净的采样轨迹,并在每一步采样完善了更多的生成细节。在频域中,更多的生成样本如下所示,在 1000 步合成中,该方法相较于扩散模型生成了更高质量的梅尔谱,当采样步数降到 50 步时,扩散模型已经牺牲了部分采样细节,而基于薛定谔桥的该方法仍然保持着高质量的生成效果。在 4 步和 2 步合成中,该方法不需蒸馏、多阶段训练、和对抗损失函数,仍然实现了高质量的生成效果。在 1000 步合成中,Bridge-TTS与基于扩散模型的方法的梅尔谱对比
下面展示了 Bridge-TTS 一个在 2 步和 4 步的一个确定性合成(ODE sampling)案例。在 4 步合成中,该方法相较于扩散模型显著合成了更多样本细节,并没有噪声残留的问题。在 2 步合成中,该方法展示出了完全纯净的采样轨迹,并在每一步采样完善了更多的生成细节。在频域中,更多的生成样本如下所示,在 1000 步合成中,该方法相较于扩散模型生成了更高质量的梅尔谱,当采样步数降到 50 步时,扩散模型已经牺牲了部分采样细节,而基于薛定谔桥的该方法仍然保持着高质量的生成效果。在 4 步和 2 步合成中,该方法不需蒸馏、多阶段训练、和对抗损失函数,仍然实现了高质量的生成效果。在 1000 步合成中,Bridge-TTS与基于扩散模型的方法的梅尔谱对比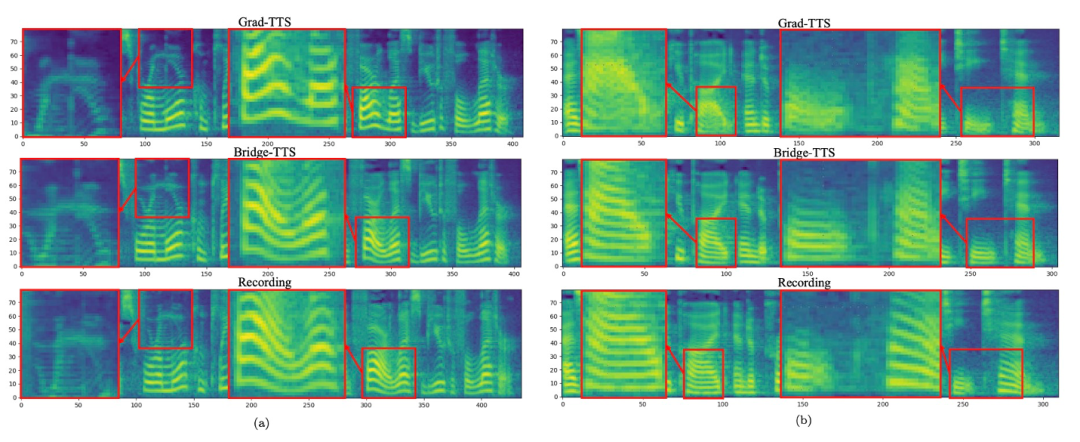
在 50 步合成中,Bridge-TTS与基于扩散模型的方法的梅尔谱对比
在 4 步合成中,Bridge-TTS与基于扩散模型的方法的梅尔谱对比在 2 步合成中,Bridge-TTS与基于扩散模型的方法的梅尔谱对比Bridge-TTS一经发布,凭借其在语音合成上新颖的设计与高质量的合成效果,在 Twitter 上引起了热烈关注,获得了百余次转发和数百次点赞,入选了 Huggingface 在 12.7 的 Daily Paper 并在当日获得了支持率第一名,同时在 LinkedIn、微博、知乎、小红书等多个国内外平台被关注与转发报道。薛定谔桥(Schrodinger Bridge)是一类继扩散模型之后,近期新兴的深度生成模型,在图像生成、图像翻译等领域都有了初步应用 [8,9]。不同于扩散模型在数据和高斯噪声之间建立变换过程,薛定谔桥支持任意两个边界分布之间的转换。在 Bridge-TTS 的研究中,作者们提出了基于成对数据间薛定谔桥的语音合成框架,灵活支持着多种前向过程、预测目标、及采样过程。其方法概览如下图所示: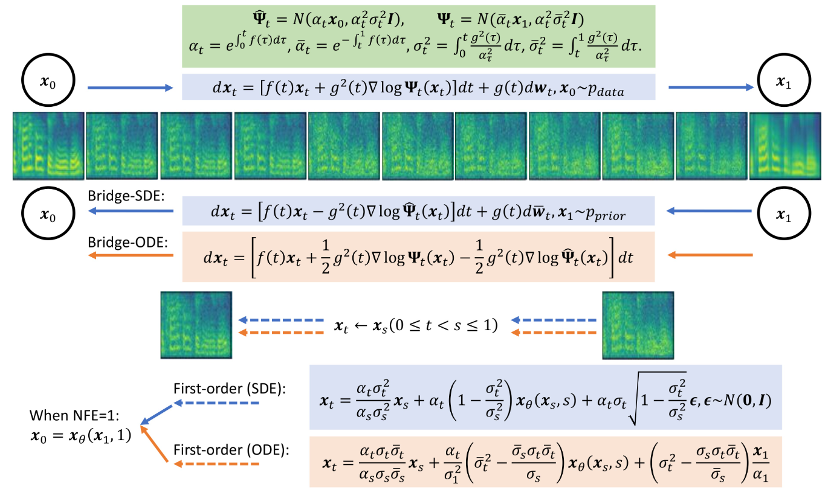
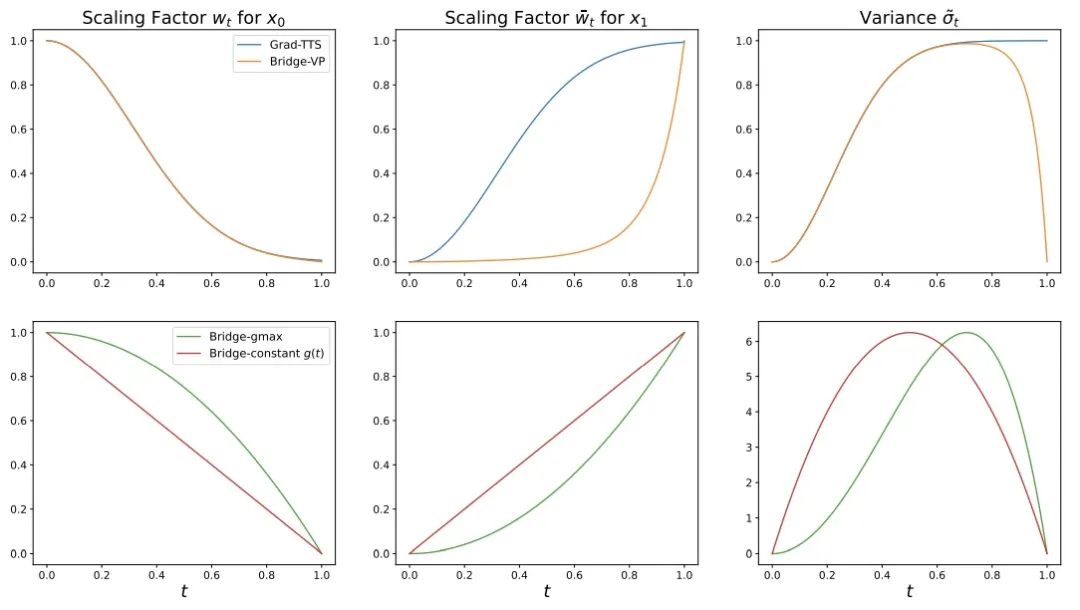
- 前向过程:此研究在强信息先验和生成目标之间搭建了一种完全可解的薛定谔桥,支持灵活的前向过程选择,如对称式噪声策略:
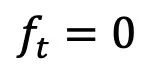 、常数
、常数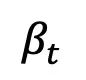 ,和非对称噪声策略:
,和非对称噪声策略:  、线性
、线性 ,以及直接与扩散模型相对应的方差保持(VP)噪声策略。该方法发现在语音合成任务中非对称噪声策略:即线性
,以及直接与扩散模型相对应的方差保持(VP)噪声策略。该方法发现在语音合成任务中非对称噪声策略:即线性 (gmax)和 VP 过程,相较于对称式噪声策略有更好的生成效果。
(gmax)和 VP 过程,相较于对称式噪声策略有更好的生成效果。


Scenario
一个AI生成游戏资产的工具
 56
查看详情
56
查看详情

- 模型训练:该方法保持了扩散模型训练过程的多个优点,如单阶段、单模型、和单损失函数等。并且其对比了多种模型参数化(Model parameterization)的方式,即网络训练目标的选择,包括噪声预测(Noise)、生成目标预测(Data)、和对应于扩散模型中流匹配技术 [10,11] 的速度预测(Velocity)等。文章发现以生成目标,即梅尔谱为网络预测目标时,可以取得相对更佳的生成效果。
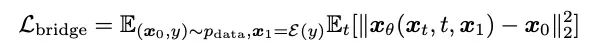
- 采样过程:得益于该研究中薛定谔桥完全可解的形式,对薛定谔桥对应的前 - 后向 SDE 系统进行变换,作者们得到了 Bridge SDE 和 Bridge ODE 用于推断。同时,由于直接模拟 Bridge SDE/ODE 推断速度较慢,为加快采样,该研究借助了扩散模型中常用的指数积分器 [12,13],给出了薛定谔桥的一阶 SDE 与 ODE 采样形式:
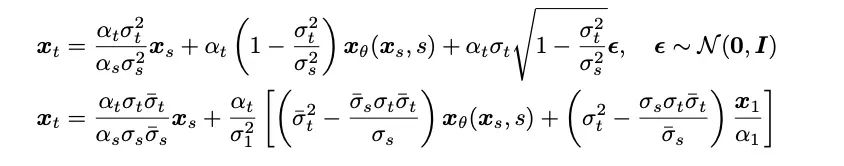
在 1 步采样时,其一阶 SDE 与 ODE 的采样形式共同退化为网络的单步预测。同时,它们与后验采样 / 扩散模型 DDIM 采样有着密切联系,文章在附录中给出了详细分析。文章也同时给出了薛定谔桥的二阶采样 SDE 与 ODE 采样算法。作者发现,在语音合成中,其生成质量与一阶采样过程类似。在其他任务如语音增强、语音分离、语音编辑等先验信息同样较强的任务中,作者们期待此研究也会带来较大的应用价值。此项研究有三位共同第一作者:陈泽华,何冠德,郑凯文,均属于清华大学计算机系朱军课题组,文章通讯作者为朱军教授,微软亚洲研究院首席研究经理谭旭为项目合作者。
朱军教授

微软亚洲研究院首席研究经理谭旭

陈泽华是清华大学计算机系水木学者博士后,主要研究方向为概率生成模型,及其在语音、音效、生物电信号合成等方面的应用。曾在微软、京东、TikTok 等多家公司实习,在语音和机器学习领域重要国际会议 ICML/NeurIPS/ICASSP 等发表多篇论文。何冠德是清华大学在读的三年级硕士生,主要研究方向是不确定性估计与生成模型,此前在 ICLR 等会议以第一作者身份发表论文。
郑凯文是清华大学在读的二年级硕士生,主要研究方向是深度生成模型的理论与算法,及其在图像、音频和 3D 生成中的应用。此前在 ICML/NeurIPS/CVPR 等顶级会议发表多篇论文,涉及了扩散模型中的流匹配和指数积分器等技术。[1] Zehua Chen, Guande He, Kaiwen Zheng, Xu Tan, and Jun Zhu. Schrodinger Bridges Beat Diffusion Models on Text-to-Speech Synthesis. arXiv preprint arXiv:2312.03491, 2025.[2] Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, and Mikhail A. Kudinov. Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech. In ICML, 2025.[3] Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen, and Zhou Zhao. DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism. In AAAI, 2025.[4] Sang-gil Lee, Heeseung Kim, Chaehun Shin, Xu Tan, Chang Liu, Qi Meng, Tao Qin, Wei Chen, Sungroh Yoon, and Tie-Yan Liu. PriorGrad: Improving Conditional Denoising Diffusion Models with Data-Dependent Adaptive Prior. In ICLR, 2025.[5] Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu, Chenye Cui, and Yi Ren. ProDiff: Progressive Fast Diffusion Model For High-Quality Text-to-Speech. In ACM Multimedia, 2025.[6] Zhen Ye, Wei Xue, Xu Tan, Jie Chen, Qifeng Liu, and Yike Guo. CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model. In ACM Multimedia, 2025.[7] Zehua Chen, Yihan Wu, Yichong Leng, Jiawei Chen, Haohe Liu, Xu Tan, Yang Cui, Ke Wang, Lei He, Sheng Zhao, Jiang Bian, and Danilo P. Mandic. ResGrad: Residual Denoising Diffusion Probabilistic Models for Text to Speech. arXiv preprint arXiv:2212.14518, 2025.[8] Yuyang Shi, Valentin De Bortoli, Andrew Campbell, and Arnaud Doucet. Diffusion Schrödinger Bridge Matching. In NeurIPS 2025.[9] Guan-Horng Liu, Arash Vahdat, De-An Huang, Evangelos A. Theodorou, Weili Nie, and Anima Anandkumar. I2SB: Image-to-Image Schrödinger Bridge. In ICML, 2025.[10] Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow Matching for Generative Modeling. In ICLR, 2025.[11] Kaiwen Zheng, Cheng Lu, Jianfei Chen, and Jun Zhu. Improved Techniques for Maximum Likelihood Estimation for Diffusion ODEs. In ICML, 2025.[12] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps. In NeurIPS, 2025.[13] Kaiwen Zheng, Cheng Lu, Jianfei Chen, and Jun Zhu. DPM-Solver-v3: Improved Diffusion ODE Solver with Empirical Model Statistics. In NeurIPS, 2025.
Liu, Chenye Cui, and Yi Ren. ProDiff: Progressive Fast Diffusion Model For High-Quality Text-to-Speech. In ACM Multimedia, 2025.[6] Zhen Ye, Wei Xue, Xu Tan, Jie Chen, Qifeng Liu, and Yike Guo. CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model. In ACM Multimedia, 2025.[7] Zehua Chen, Yihan Wu, Yichong Leng, Jiawei Chen, Haohe Liu, Xu Tan, Yang Cui, Ke Wang, Lei He, Sheng Zhao, Jiang Bian, and Danilo P. Mandic. ResGrad: Residual Denoising Diffusion Probabilistic Models for Text to Speech. arXiv preprint arXiv:2212.14518, 2025.[8] Yuyang Shi, Valentin De Bortoli, Andrew Campbell, and Arnaud Doucet. Diffusion Schrödinger Bridge Matching. In NeurIPS 2025.[9] Guan-Horng Liu, Arash Vahdat, De-An Huang, Evangelos A. Theodorou, Weili Nie, and Anima Anandkumar. I2SB: Image-to-Image Schrödinger Bridge. In ICML, 2025.[10] Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow Matching for Generative Modeling. In ICLR, 2025.[11] Kaiwen Zheng, Cheng Lu, Jianfei Chen, and Jun Zhu. Improved Techniques for Maximum Likelihood Estimation for Diffusion ODEs. In ICML, 2025.[12] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps. In NeurIPS, 2025.[13] Kaiwen Zheng, Cheng Lu, Jianfei Chen, and Jun Zhu. DPM-Solver-v3: Improved Diffusion ODE Solver with Empirical Model Statistics. In NeurIPS, 2025.以上就是薛定谔桥助力,清华朱军团队开发新型语音合成系统应对扩散挑战的详细内容,更多请关注其它相关文章!
# sider
# 产业
# 所示
# 清华大学
# 梅尔
# 高质量
# 语音合成
# 清华
# 来了
# type
# peech
# 新沂优化网站排名软件
# 桐庐网站seo服务
# 各行社在抓营销推广
# 临漳网站推广营销中心
# 安徽seo公司方案
# 莆田网站关键词推广
# 王坟网站建设
# 北白象网站建设与管理
# 简述网站建设的因素
# 抖音SEO运营推广印刷
# 多个
# 出了
# 成中
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
25个AI智能体源码现已公开,灵感来自斯坦福的「虚拟小镇」和《西部世界》
V社悄悄封禁使用AI生成美术素材的游戏
2025“春晖杯”人工智能专场对接活动举办
宇宙探索下一阶段,机器代替人类,AI会在太空探索中取代人类吗?
Dubbo负载均衡策略之 一致性哈希
Bing Chat 和 Bing Search 正式引入深色模式
软银、淡马锡、沙特阿美突击入股,“协作机器人第一股”节卡股份:强敌环伺,持续失血是常态
第 66 届格莱美奖规定,AI 作品将无法获得评奖资格
普林斯顿Infinigen矩阵开启!AI造物主100%创造大自然,逼真到炸裂
微软在德国举办MR研讨会,向女性分享元宇宙潜力
2025世界人工智能大会前沿科技共绘“未来”图景, 这家这家独角兽企业的通用大脑将在AI领域大放异彩
意大利警察拟用AI预测犯罪 该算法被指种族歧视严重
出门问问亮相2025世界人工智能大会,展示AI CoPilot解决方案
WHEE功能介绍
谷歌借AI打破十年排序算法封印,每天被执行数万亿次,网友却说是最不切实际的研究?
Meta 发布 Voicebox AI 模型:可生成音频信息,用于 NPC 对话等
世界上第一个完全由人工智能驱动的图像编辑器!
新华三集团总裁兼首席执行官于英涛:人工智能时代需要想象力,更需要精耕务实
谷歌计划在上海举办开发者大会,重点关注机器学习和生成式AI领域
昇腾AI大模型训推一体化解决方案将在WAIC发布
Unity 内测 Safe Voice 服务,利用 AI 自动识别玩家不当聊天内容
280万条多模态指令-响应对,八种语言通用,首个涵盖视频内容的指令数据集MIMIC-IT来了
网易云音乐和小冰推出AI歌手音乐创作软件,首发内置12名AI歌手
从GOXR到PartyOn,XRSPACE致力打造多元共赢的元宇宙世界
抢占新赛道 加快机器人产业集聚发展
测试框架-安全和自动驾驶
助力人工智能产业高质量发展 龙岗区算法训练基地正式启用
华为推出全新操作系统HarmonyOS 4,AI和新引擎完美融合
从数据中心到发电站:人工智能对能源使用的影响
比尔盖茨:AI确实存在风险,但可控
第四范式「式说」大模型入选《2025年通用人工智能创新应用案例集》
创作音乐/音频的Meta开源AI工具AudioCraft,让用户通过文本提示实现
机智云AI离线语音识别模组,让家电变得更加智能便捷
“具身智能”引爆机器人产业,看绝影Lite3/X20四足机器人有何特别之处?
WHEE网页地址入口
网易加速行业AI大模型应用,将覆盖100多个应用场景
AI大模型产品集体奔赴高考考场,教育赛道的讯飞星火能赢吗?
OpenAI宣布组建新团队 以控制“超级智能”人工智能
网易易盾 AI Lab 论文入选 ICASSP 2025!黑科技让语音识别越“听”越准
小米首次曝光 64 亿参数的 MiLM-6B AI 大模型,或将应用于小爱同学
苹果式 AI 哲学:不着一字,处处落子
周鸿祎:用超级AI实现室温超导和核聚变,实现能源自由
外科医生的智能助手,“机器人手术”得到补充商业医保覆盖
13万个注释神经元,5300万个突触,普林斯顿大学等发布首个完整「成年果蝇」大脑连接组
石头扫拖机器人 G20 618 福利来袭:4999 元,超值配件领到手软
美图秀秀发布七款 AI 工具:修图一样修视频、打造电影级上镜脸
人工智能正在弥合认知和表达之间的鸿沟
插画师对AI绘画软件的态度是怎样的?
Unity 推出面向开发者的 AI 软件市场 AI Hub,股价飙涨 15%
OpenAI限制网络爬虫访问以保护数据免被用于AI模型训练




 发布时间:2024-01-03
发布时间:2024-01-03 点击次数:
点击次数: 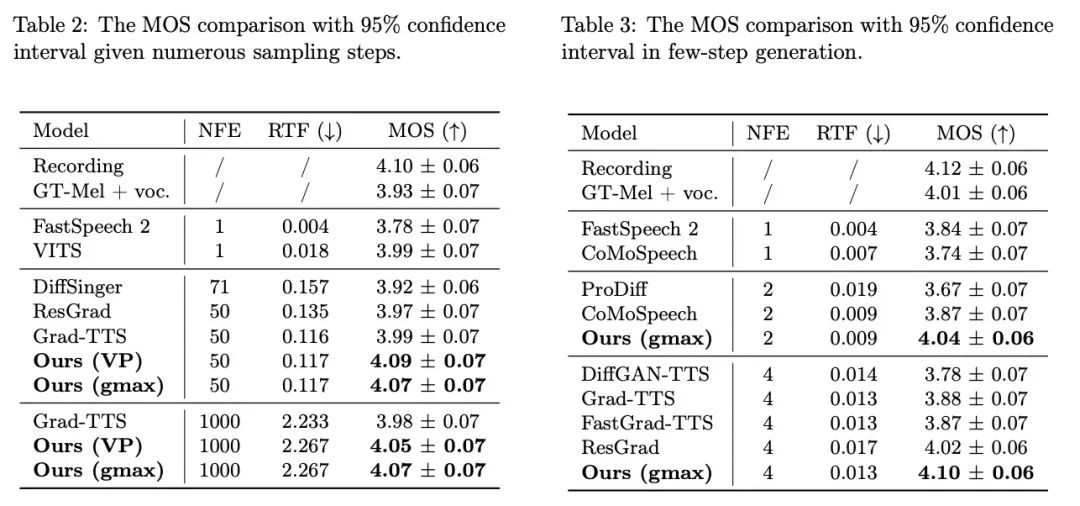
 、线性
、线性 ,以及直接与扩散模型相对应的方差保持(VP)噪声策略。该方法发现在语音合成任务中非对称噪声策略:即线性
,以及直接与扩散模型相对应的方差保持(VP)噪声策略。该方法发现在语音合成任务中非对称噪声策略:即线性
 Liu, Chenye Cui, and Yi Ren. ProDiff: Progressive Fast Diffusion Model For High-Quality Text-to-Speech. In ACM Multimedia, 2025.
Liu, Chenye Cui, and Yi Ren. ProDiff: Progressive Fast Diffusion Model For High-Quality Text-to-Speech. In ACM Multimedia, 2025. 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

