不知 Gemini 1.5 Pro 是否用到了这项技术。
谷歌又放大招了,发布下一代 transformer 模型 infini-transformer。
Infini-Transformer 引入了一种有效的方法,可以将基于 Transformer 的大型语言模型 (LLM) 扩展到无限长输入,而不增加内存和计算需求。使用该技术,研究者成功将一个 1B 的模型上下文长度提高到 100 万;应用到 8B 模型上,模型能处理 500K 的书籍摘要任务。自 2017 年开创性研究论文《Attention is All You Need》问世以来,Transformer 架构就一直主导着生成式人工智能领域。而谷歌对 Transformer 的优化设计最近比较频繁,几天前,他们更新了 Transformer 架构,发布 Mixture-of-Depths(MoD),改变了以往 Transformer 计算模式。没过几天,谷歌又放出了这项新研究。专注 AI 领域的研究者都了解内存的重要性,它是智能的基石,可以为 LLM 提供高效的计算。然而,Transformer 和基于 Transformer 的 LLM 由于注意力机制的固有特性,即 Transformer 中的注意力机制在内存占用和计算时间上都表现出二次复杂性。例如,对于批大小为 512、上下文长度为 2048 的 500B 模型,注意力键 - 值 (KV) 状态的内存占用为 3TB。但事实上,标准 Transformer 架构有时需要将 LLM 扩展到更长的序列(如 100 万 token),这就带来巨大的内存开销,并且随着上下文长度的增加,部署成本也在增加。基于此,谷歌引入了一种有效的方法,其关键组成部分是一种称为 Infini-attention(无限注意力)的新注意力技术。不同于传统的 Transformer 使用局部注意力丢弃旧片段,为新片段释放内存空间。Infini-attention 增加了压缩内存(compressive memory),可以将使用后的旧片段存储到压缩内存中,输出时会聚合当前上下文信息以及压缩内存中的信息,因而模型可以检索完整的上下文历史。该方法使 Transformer LLM 在有限内存的情况下扩展到无限长上下文,并以流的方式处理极长的输入进行计算。实验表明,该方法在长上下文语言建模基准测试中的性能优于基线,同时内存参数减少了 100 倍以上。当使用 100K 序列长度进行训练时,该模型实现了更好的困惑度。此外该研究发现,1B 模型在 5K 序列长度的密钥实例上进行了微调,解决了 1M 长度的问题。最后,论文展示了具有 Infini-attention 的 8B 模型经过持续的预训练和任务微调,在 500K 长度的书籍摘要任务上达到了新的 SOTA 结果。
- 引入了一种实用且强大的注意力机制 Infini-attention—— 具有长期压缩内存和局部因果注意力,可用于有效地建模长期和短期上下文依赖关系;
- Infini-attention 对标准缩放点积注意力( standard scaled dot-product attention)进行了最小的改变,并通过设计支持即插即用的持续预训练和长上下文自适应;
- 该方法使 Transformer LLM 能够通过流的方式处理极长的输入,在有限的内存和计算资源下扩展到无限长的上下文。
- 论文链接:https://arxiv.org/pdf/2404.07143.pdf
- 论文标题:Le*e No Context Behind: Efficient Infinite Context Transformers with Infini-attention
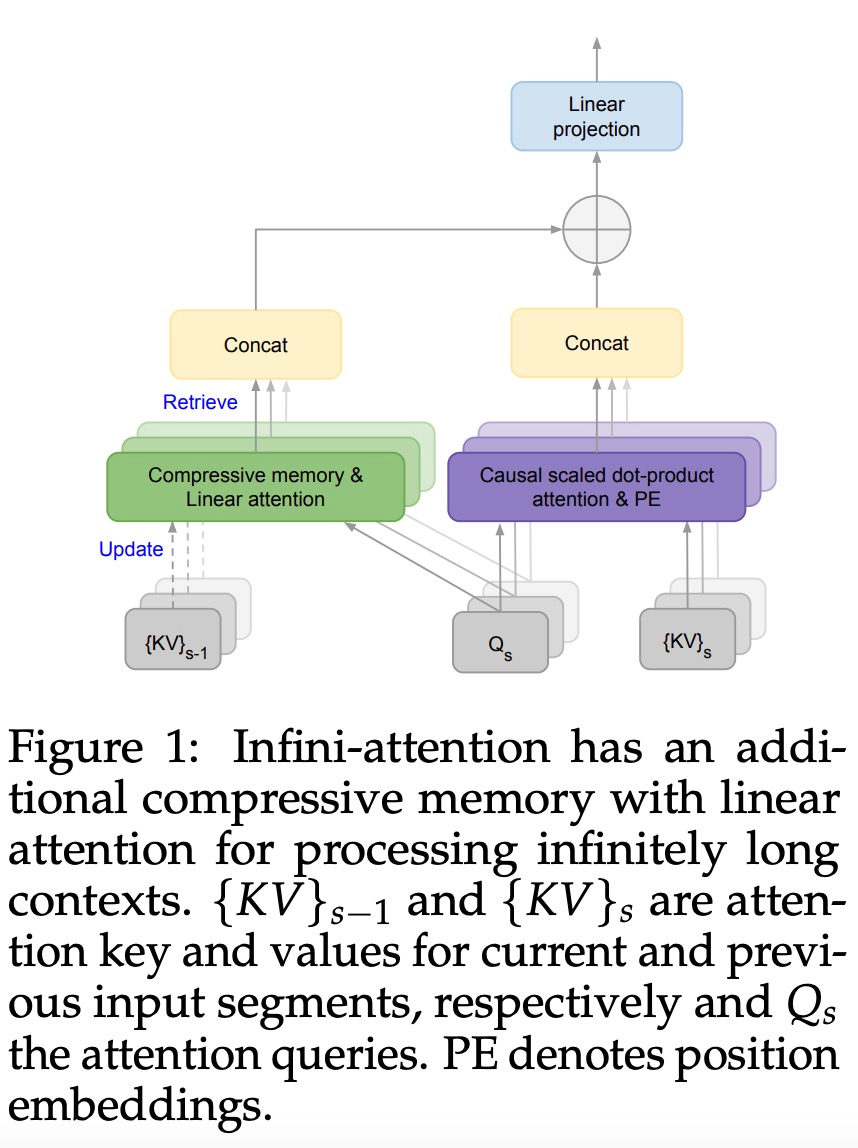
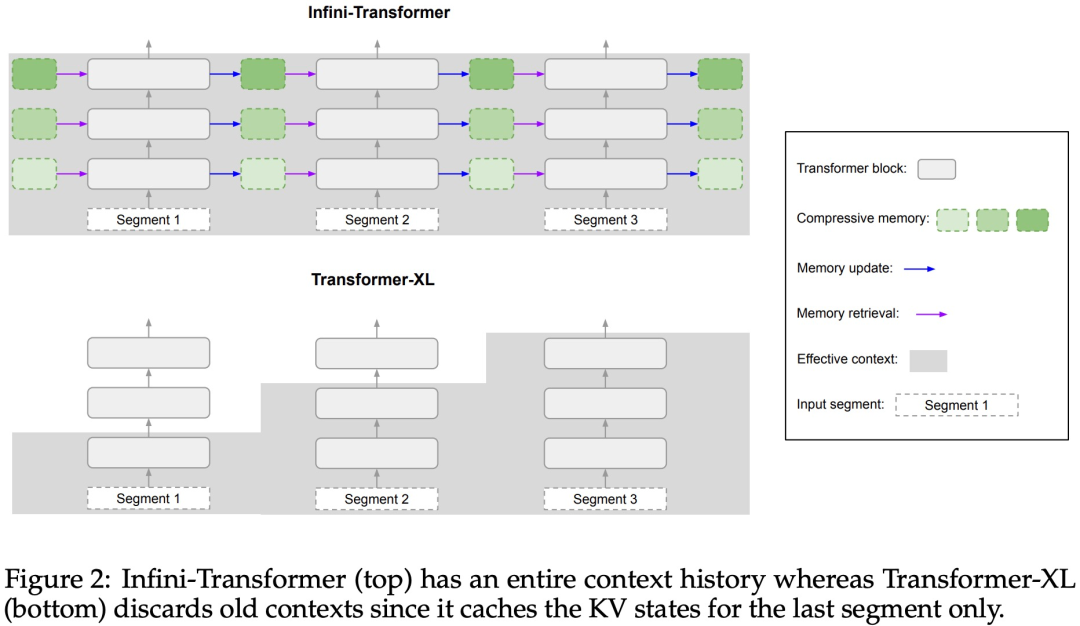
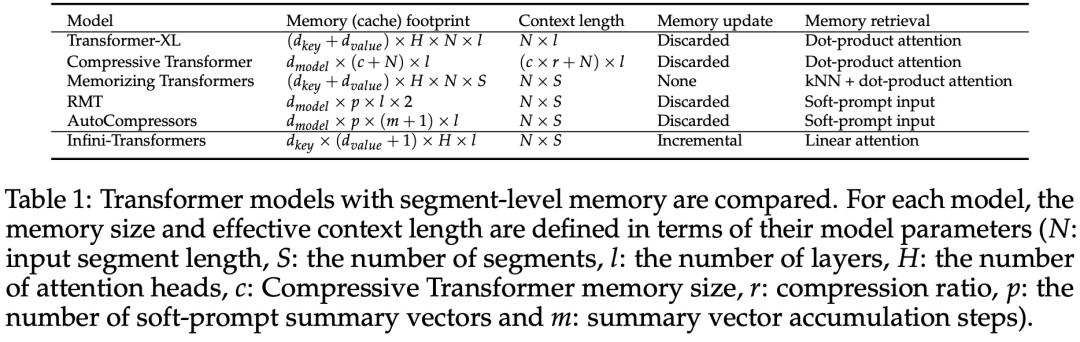
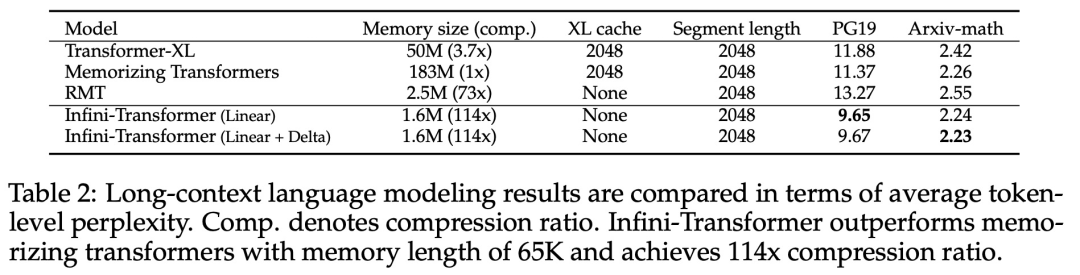
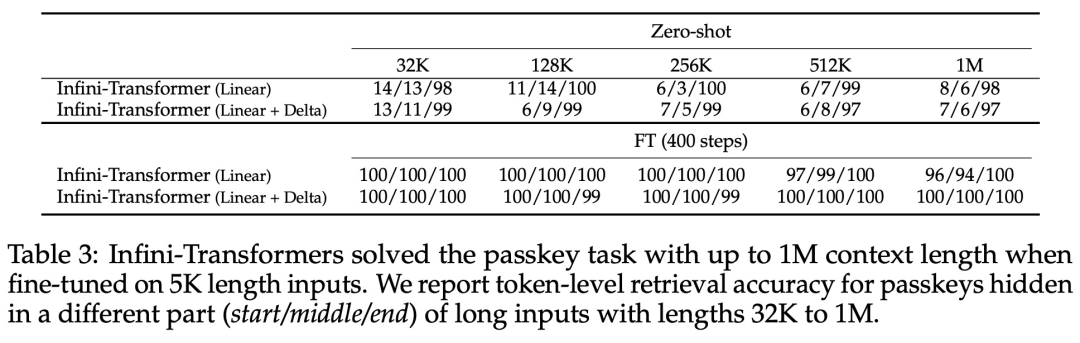
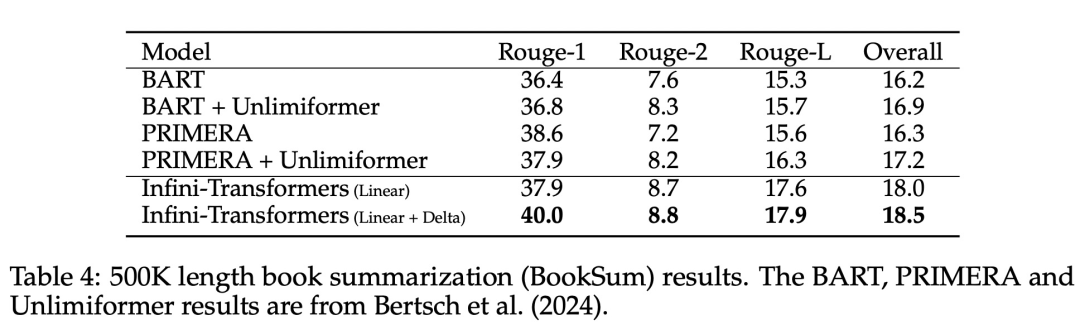
Infini-attention 使 Transformer LLM 能够通过有限的内存占用和计算有效地处理无限长的输入。如下图 1 所示,Infini-attention 将压缩记忆融入到普通的注意力机制中,并在单个 Transformer 块中构建了掩码局部注意力和长期线性注意力机制。对 Transformer 注意力层进行这种微妙但关键的修改可以通过持续的预训练和微调将现有 LLM 的上下文窗口扩展到无限长。Infini-attention 采用标准注意力计算的所有键、值和查询状态,以进行长期记忆巩固(memory consolidation)和检索,并将注意力的旧 KV 状态存储在压缩内存中,而不是像标准注意力机制那样丢弃它们。在处理后续序列时,Infini-attention 使用注意查询状态从内存中检索值。为了计算最终的上下文输出,Infini-attention 聚合了长期记忆检索值和局部注意力上下文。如下图 2 所示,研究团队比较了基于 Infini-attention 的 Infini-Transformer 和 Transformer-XL。与 Transformer-XL 类似,Infini-Transformer 对 segment 序列进行操作,并计算每个 segment 中的标准因果点积注意力上下文。因此,点积注意力计算在某种意义上是局部的。然而,局部注意力在处理下一个 segment 时会丢弃前一个 segment 的注意力状态,但 Infini-Transformer 复用旧的 KV 注意力状态,以通过压缩存储来维护整个上下文历史。因此,Infini-Transformer 的每个注意力层都具有全局压缩状态和局部细粒度状态。与多头注意力(MHA)类似,除了点积注意力之外,Infini-attention 还为每个注意力层维护 H 个并行压缩内存(H 是注意力头的数量)。下表 1 列出了几种模型根据模型参数和输入 segment 长度,定义的上下文内存占用和有效上下文长度。Infini-Transformer 支持具有有限内存占用的无限上下文窗口。该研究在长上下文语言建模、长度为 1M 的密钥上下文块检索和 500K 长度的书籍摘要任务上评估了 Infini-Transformer 模型,这些任务具有极长的输入序列。对于语言建模,研究者选择从头开始训练模型,而对于密钥和书籍摘要任务,研究者采用不断预训练 LLM 的方式,以证明 Infini-attention 即插即用的长上下文适应能力。长上下文语言建模。表 2 结果表明 Infini-Transformer 优于 Transformer-XL 和 Memorizing Transformers 基线,并且与 Memorizing Transformer 模型相比,存储参数减少了 114 倍。密钥任务。表 3 为 Infini-Transformer 在 5K 长度输入上进行微调后,解决了高达 1M 上下文长度的密钥任务。实验中输入 token 的范围从 32K 到 1M,对于每个测试子集,研究者控制密钥的位置,使其位于输入序列的开头、中间或结尾附近。实验报告了零样本准确率和微调准确率。在对 5K 长度输入进行 400 个步骤的微调后,Infini-Transformer 解决了高达 1M 上下文长度的任务。摘要任务。表 4 将 Infini-Transformer 与专门为摘要任务构建的编码器 - 解码器模型进行了比较。结果表明 Infini-Transformer 超越了之前最佳结果,并且通过处理书中的整个文本在 BookSum 上实现了新的 SOTA。 研究者还在图 4 中绘制了 BookSum 数据验证分割的总体 Rouge 分数。根据折线趋势表明,随着输入长度的增加,Infini-Transformers 提高了摘要性能指标。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜


Machine Translation
聚合多个来源的AI翻译
 49
查看详情
49
查看详情

以上就是直接扩展到无限长,谷歌Infini-Transformer终结上下文长度之争的详细内容,更多请关注其它相关文章!
# 产业
# 公司seo网站营销推广
# 杭州衣服网站推荐优化店
# 上海seo优化手段
# 即用
# 新能源
# 所示
# 有效地
# 解决了
# 几天
# 出了
# 进行了
# 之争
# 扩展到
# type
# gemini
# 内存占用
# 谷歌
# 贵阳网站建设作品
# 推广游戏靠什么营销
# 网站设计优化的最佳阶段
# 推广做的好的网站
# 营销推广启动阶段是什么
# 津南区地方网站建设策划
# 清酒吧营销推广方案
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
为AI而服务设计:构建以人为本的AI创新方法
如何提高集群协作效率?中外团队合作研发基于均值偏移的机器人队形控制策略
Bing 聊天机器人现支持在桌面端用语音提问
华为4G5G通信物联网收费标准公布,多年研发成果,十年花费近万亿
人形机器人概念集体爆发,能买吗?
烟台大学学生首次在全国大学生无人机航拍竞赛中获奖
AI 模型 Stable Diffusion 升级:正常生成五指、图像更逼真
视觉中国宣布推出AI灵感绘图、画面扩展功能
十个AI算法常用库J*a版
当一切设备都受到人工智能的控制
关于开展“与AI共创未来”——2025年全国青少年人工智能创新实践活动的通知
腾讯AI首次模拟拼接三星堆文物,工作取得阶段性的成果
智能机器人正在彻底改变客户服务
探展WAIC |万向区块链杜宇:不存在单一技术的iPhone时刻,Web3.0核心将基于AI+区块链+物联网
OpenAI CEO 山姆・阿尔特曼呼吁 AI 领域中美应当合作
全球首款AI裸眼3D平板 国产的售价破万
Zoom远程会议应用:AI培训需经用户授权
成功孵化首个大型模型解决方案的重庆人工智能创新中心
大型无人机FH-98国内首次夜航转场成功
组建团队,字节跳动要造机器人?
世界人工智能大会中西部县域数字就业中心组团亮相
万兴播爆桌面端上线,支持AI数字人搜索、视频编辑等功能
三个全球首创,青岛西海岸新区“海元宇宙”亮相世界人工智能大会
上海发布“元宇宙关键技术攻关行动方案”,加快 AIGC 等突破
360发布AI数字人广场,可同孙悟空、爱因斯坦等古今中外角色对话
复旦发布「新闻推荐生态系统模拟器」SimuLine:单机支持万名读者、千名创作者、100+轮次推荐
谷歌借AI打破十年排序算法封印,每天被执行数万亿次,网友却说是最不切实际的研究?
腾讯自主研发机器狗 Max 升级,可“奔跑跳跃”完成避障动作
原小米 9 号员工李明打造全球首款 AI 安卓桌面机器人
中国最强AI研究院的大模型为何迟到了
苹果2万5的AR遭遇砍单95%:不及预期
2025年的网络分区:人工智能和自动化如何改变事物
构建AI绘画网站的方法:使用API接口和调用步骤
AI智能室内效果图设计软件效果,确实惊到我了!
以计算机视觉技术为基础的库存管理如何改革零售行业
Spotify计划推出AI驱动的音乐播放器功能
特斯拉机器人面世 未来将大幅提振磁材需求,引领人工智能时代
新华全媒+|AI:当心,我可能欺骗了你!
人工智能在服务优化方面优缺点有哪些
引领AI变革,九章云极DataCanvas公司重磅发布AIFS+DataPilot
从GOXR到PartyOn,XRSPACE致力打造多元共赢的元宇宙世界
《共同的演化》展览启幕,重新思考人类与人工智能关系
国内AI大模型“安卓时刻”到来!阿里云通义千问免费、开源、可商用
微软大牛加入ZOOM,AI人才大战打响
比尔盖茨:AI确实存在风险,但可控
中国气象局预测:到 2030 年,中国人工智能气象应用将达到国际领先水平
高通发布长期产品计划,为工业和企业物联网产品提供全新组合方案
微软最新推出的NaturalSpeech2语音合成模型:提供更准确的语音重构,避免棒读效果
"探索Meta发布的Quest MR/VR视频录制与拍摄指南"
“三夏”农忙保障用电,无人机高空巡视高压线




 发布时间:2024-04-13
发布时间:2024-04-13 点击次数:
点击次数: 


 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表

